给毕业论文方向找资料ing,虽说具体要做的东西目前还在思考比较多,从之前的 【整理一下看过的论文】 里面把相关的论文理出来了。
大致分成三个方面:
- Distributed Machine Learning System
- Distributed Deep Learning System
- Large Scale Neural Network Training
虽说重点主要集中在后面两块上,不过其他方面的机器学习毕竟发展的时间比深度学习更早,分布式系统方面还是有参考价值的。
把第二三两部分分开整理主要考虑一个是偏框架和算法设计,一个是偏向针对某个具体的应用问题做的大规模实现。
Distributed Machine Learning System
2013 NIPS - More Effective Distributed ML via a Stale Synchronous Parallel Parameter Server
话说我第一眼看这个系列的文章还以为讲的就是深度学习了,后来才发现这些全是主要针对机器学习的。
分布式方法还是主要基于传统的 Parameter Server 对 Worker 的形式,但是提出了一种 SSP(Stale Synchronous Parallel) 模型来解决普通的同步或者异步模式下训练会有的问题。SSP 模型大致是说会在本地维护一个参数的 cache,每个工作的 node 直接从本地的 cache 中拿数据,跟 PS 之间的同步问题应该是另外处理,这样就把每个工作 node 等待网络的时间给降下来了。
Introduction 中首先分析了机器学习训练中可能有的问题:massive data volume 和 massive model size,数据量太大和模型太大这两个问题即使可以通过尽可能地缩减、压缩,也终有个尽头,未来总有解决不了的时候,因此不得不需要用到分布式的训练环境。
分布式机器学习系统需要解决的最终目标是:
- 最大化利用计算资源(把更多的时间花在运算上)
- 训练完之后要能支持 inference
- 保证正确性(保证分布式之后网络仍然是能够收敛的)
文中对 PS 的定义是:一个共享的键值对存储模型,同时要具备读取和更新参数的同步机制。共享的键值对存储方式能简化编程复杂度,数据同步是为了保证整个训练过程的正确性。
SSP 这种模型的重点在于像前面说的本地保留尽可能新的旧参数,这里给了个微软一篇技术报告的引用:
如果说同步可以达到更好的 quality,异步可以达到更好的 quantity 的话,SSP 是取了这两种方案的折中,最终比这两种都要有效。
规定每个 worker 运行时有个 clock 计数器(时间戳),记的是当前到了第几轮迭代。给定一个阈值 s,SSP 模型遵循以下几个规则:
- 最慢的和最快的 worker 之间跑的参数之间的 clock 差不能超过 s,否则最快的 worker 就要强制等待后面较慢的 worker 算完了赶上来
- 当一个当前 clock 值是 c 的 worker 提交一个参数更新时,那个更新的时间戳为 c
- 当一个当前 clock 值是 c 的 worker 读取参数时,根据上述规则,它读取到的更新至少会包含 c-s-1 时间戳之前的所有更新内容
- 一个 worker 读取到的更新总会比它自己产生的所有结果更新
事实上作者用 c 和 s 这两个定义就把 BSP 和异步给总结到一起了。如果 s 为 0,相当于所有的 worker 都是完全同步的,当 s 是无穷大的时候,就是完全异步的。
这个 s 就是 SSP 模型中需要 overlap 的部分,s 太小则可能经常有些 worker 需要等待,并行性提不上去,s 太大影响问题整体的收敛率。
具体实现上,作者用了一个类似 cache 页表的 SSP table,思想大致也是类似的。在多个 worker 跑在单个节点中的情况下,节点内还可以再多做一层线程间的数据 cache。
2014 ATC - Exploiting bounded staleness to speedup Big Data analytics
这篇 paper 的内容是上面那篇的后续研究(话说作者都差不多),大体上是对上篇内容作了更多的补充和提升。作者在实验中发现应用了 bounded staleness 思想的 BSP 模型到最后效果跟 SSP 是差不多的,因此对这其中的详细情况和原因也作了深入分析。
引入 bounded staleness 思想的 BSP 模型这里成为 A-BSP,BSP 是每次迭代之后一个大同步,A-BSP 就是把这个限制放开点,每 n 次迭代之后一个大同步。用上面一篇提过的归纳方式,BSP、A-BSP、SSP 都可以归到一起。
SSP 说起来确实有点像是在 A-BSP 的基础上做个流水线的感觉。当整个分布式系统中,各个线程做的任务不太平衡,有明显较慢的 worker 存在时,SSP 能更好地提高并行度(负载均衡?)。但 SSP 相对 A-BSP 的通信次数是更多的,当各个 worker 的运行速度差距很小时,可能用 A-BSP 会有更好的效果。
这里用来维护数据 cache 的数据结构叫 LazyTable,其实就是前面 SSP Table 的升级版,实现大致都是类似的。
另外这里还做了预取和容错。
2014 SoCC - Exploiting Iterative-ness for Parallel ML Computations
To be read.
2014 OSDI - Scaling distributed machine learning with the parameter server
To be read.
2015 - Distributed Machine Learning via Sufficient Factor Broadcasting
SFB。
To be read.
2015 - Efficient Machine Learning for Big Data: A Review
机器学习与大数据结合方面的一篇综述。
To be read.
2015 - Petuum: A new Platform for Distributed Machine Learning on Big Data
一种分布式机器学习的平台设计。
To be read.
2015 EuroSys - Malt: distributed data-parallelism for existing ml applications
一个叫 Malt 的库,用于把常用的机器学习应用从单机改造成分布式的。
To be read.
2015 SoCC - Managed Communication and Consistency for Fast Data-Parallel Iterative Analytics
一套叫 Bosen 的分布式机器学习系统。
To be read.
2016 EuroSys - STRADS: A Distributed Framework for Scheduled Model Parallel Machine Learning.
To be read.
2016 UAI - Lighter-Communication Distributed Machine Learning via Sufficient Factor Broadcasting
SFB。
To be read.
2017 - Machine learning on big data Opportunities and challenges
To be read.
Distributed Deep Learning System
其他资料
2012 NIPS - Large Scale Distributed Deep Networks
Google 的第一代深度学习系统 Distbelief,由 Jeffrey Dean 大佬带头,其实是 TensorFlow 的前身。
现在说的深度神经网络最初的来源就是传统机器学习里面的受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)以及多层感知器(Multilayer Perceptron,MLP)等等想法,这俩演变出来了一个叫深度信念网络(Deep Belief Network,DBN)的东西,基本跟今天的 DNN 已经很像了。Distbelief 里面的 Belief 指的应该就是 DBN 吧。
出发点基本跟后来的文章大同小异,文章的重点在于:
- Downpour SGD:前面这个单词是描述倾盆大雨的,不知道整个词组应该怎么翻译比较好;
- 基于 Sandblaster 框架实现了一个 L-BFGS,用于处理整个训练过程的数据并行和模型并行。
相比普通的 SGD + 普通的 L-BFGS 实现要快上不少。
异步 SGD 之前在机器学习领域很少被用在非凸的优化问题上,但是经过试验验证之后发现异步 SGD 用在神经网络上效果很好,尤其是配合 Adagrad 这种学习率修正算法的时候。然后在资源足够的情况下,L-BFGS 的性能不会弱于 SGD。
论文中做到的最大规模是把一个模型拆到 32 个节点上进行模型并行。
2013 ICML - Deep Learning with COTS HPC
首次把分布式机器学习里面的数据并行和模型并行引入深度学习。
主要实现在 InfiniBand 网络上,然后偏重在模型并行上。
To be read.
2014 ICASSP - On parallelizability of stochastic gradient descent for speech DNNS
这篇文章是从理论上对比了模型并行和数据并行中分布式 SGD 训练的效率,指出增大 minibatch 的大小可以提高数据并行训练的效率。
To be read.
2014 OSDI - Project Adam: Building an Efficient and Scalable Deep Learning Training System
微软在分布式 DL 训练方面做的工作。
To be read.
2014 Proceedings of the VLDB Endowment - Mariana: Tencent Deep Learning Platform and its Applications
腾讯做的一个叫 Mariana 的深度学习平台。
To be read.
2015 ACM MM - SINGA: Putting Deep Learning in the Hands of Multimedia Users
一套叫 SINGA 的分布式深度学习框架。
To be read.
2016 - Asynchrony begets momentum, with an application to deep learning
分析了异步与动量法调整的学习率之间的影响关系。
动量法是一种梯度下降里面对学习率自动调节的方法。
To be read.
2016 - How to scale distributed deep learning
用 ImageNet 对比了同步和异步 SGD 的实测结果,指出可能在更大规模下其实同步 SGD 效果更好。
To be read.
2016 SoCC - Ako: Decentralised deep learning with partial gradient exchange
去中心化(不再采用 PS-Worker 方式)的分布式深度学习思路。
To be read.
2016 Eurosys - GeePS: Scalable Deep Learning on Distributed GPUs with a GPU-Specialized Parameter Server
这篇文章很厉害了,主要内容是说做了一套叫 GeePS 的 Parameter Server 机制,主要针对 GPU 做了特别的优化和改进,克服了数据并行和模型并行,BSP 和异步这些老方法中存在的问题,最终结果性能爆炸。GeePS 还支持在卡上跑超过显存容量的网络,直接解决了对模型并行的需求。
背景介绍部分分析了一下 Parameter Server 模式存在的问题,这里也有提到前面 13 年那篇 SSP 模型方面的工作(…其实这篇论文还是同一拨人做的…)。要应用 PS 模式到 GPU 上,采用多个 worker 配合多个 ps,每个物理节点内都有 ps 和 worker 这种形式会比较合适。
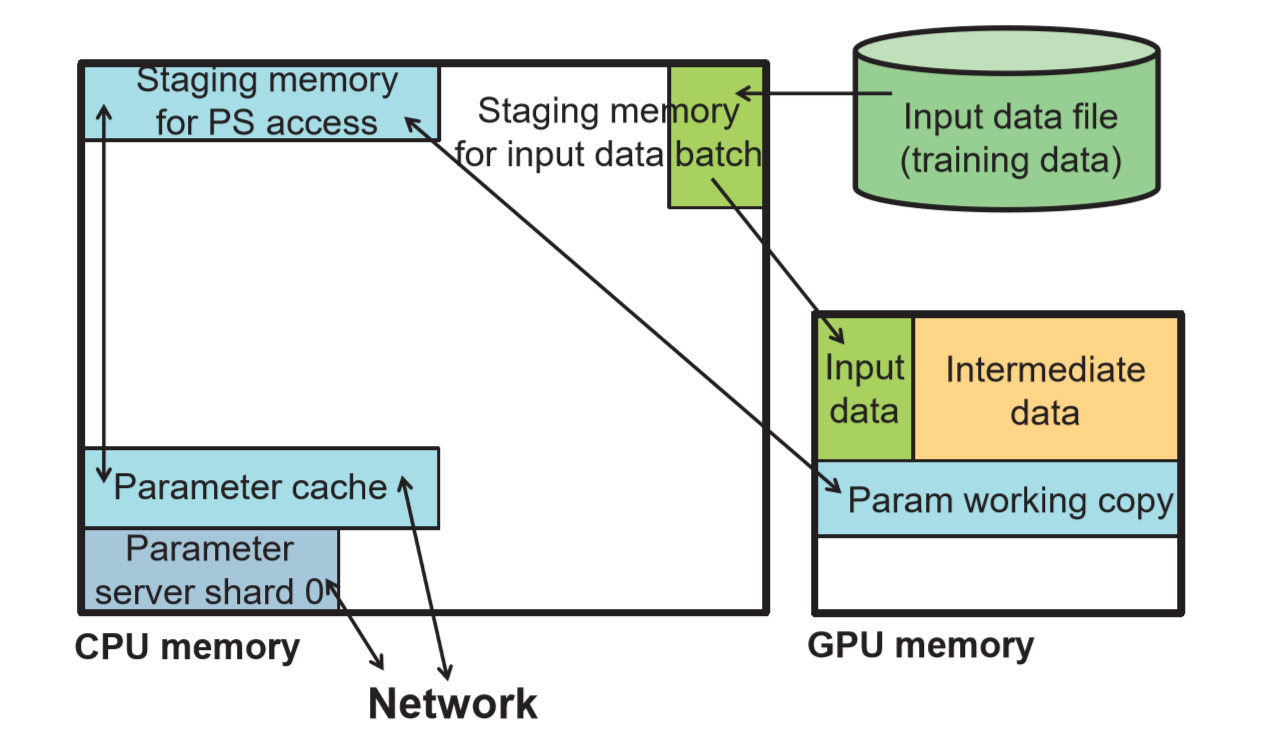
但是直接简单地把 ps 搬到 GPU 上效果非常不好,后文接下来就是讲他们如何解决这个问题,即他们提出来的 GeePS 是怎么做的。
第一个优化策略是在 GPU 上做一个参数 cache,嗯这个思想大概跟往异步 PS 里面引入本地 cache(应用 SSP 模型)是一个道理。因为前面的性能瓶颈主要在每一次推送参数更新上了,引入了 CPU 跟 GPU 之间的数据传输之后总会把整个计算过程卡下来。
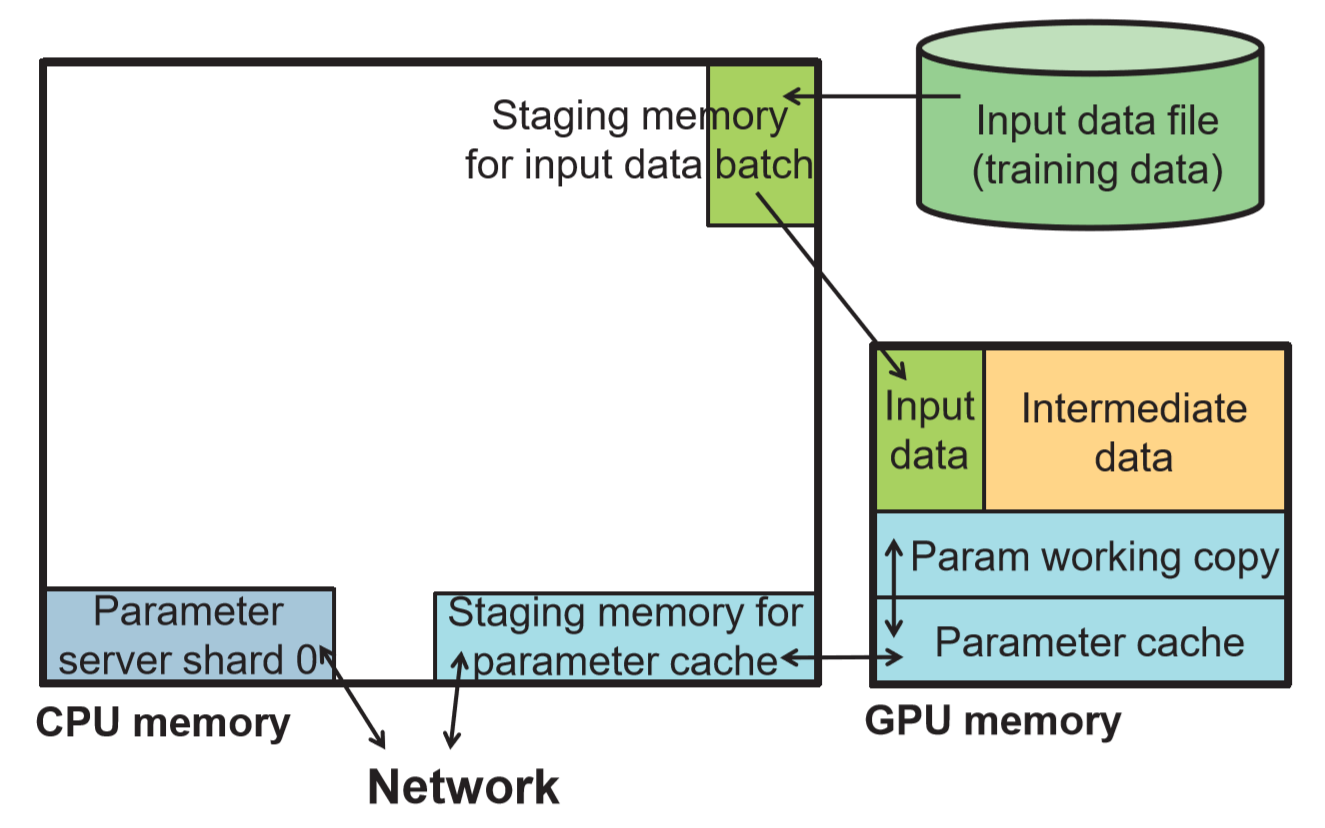
这种方法提升性能的关键在于能够成功地把计算和 CPU/GPU 的数据拷贝给 overlap 开,这样就能最大化 GPU 的使用率啦,GPU 只要拿到了新的 input 数据就能一直跑。
第二个策略是数据的输入和参数的更新都是以 batch 为单位的,利用了 GPU 的 SIMD 特性,增加了数据的吞吐量,这一块详细的要见他们前面的一篇文章(Exploiting Iterative-ness for Parallel ML Computations)。
第三个就厉害了,目测应该工作量挺大的。为了解决模型太大,GPU 上放不下的问题,他们手动维护了一个 GPU 和 CPU 之间的内存池,每次把不用的数据换到主存上,把下一波计算需要用的数据换到 GPU 上。
用手动维护的内存池完全接管整个 GPU 的内存分配、释放操作,CPU 跟 GPU 之间的数据传输用另外一个线程在后台完成,把计算时间和数据拷贝延迟完全 overlap 开。由于神经网络层与层之间的顺序性是显示存在的,因此数据在 GPU 显存上的换入换出就是完全可以做到的了。
第四点是对 PS 模式下异步方式的思考,虽说把 BSP 改成异步的可以增加计算资源的利用率,但是收敛速度会放慢是肯定的,之前的不少研究也是在这两个方面作了取舍,才能让最终训练到相同效果的总体时间更短。这篇文章在同步延迟能够保证的情况下,测试结果偏向于用 BSP 收敛效果会更好。
中间的详细实现先放着,留待之后回来看。
2017 ATC - Poseidon: An Efficient Communication Architecture for Distributed Deep Learning on GPU Clusters
emm…这篇文章跟上一篇还是同一拨人做的。Motivation、目标什么的基本上差不多,工作方向上从不同的角度出发来做。
文章首先指出了限制分布式深度学习可扩展性的两个瓶颈:
- 每次更新的梯度都可能是大矩阵,很容易就把网络带宽给占满;
- 由于神经网络运算的迭代特性,在完成一轮迭代之后才更新参数。因此其通信表现是短时间内有一个通信量的暴增,而其他时间没有通信。
本文解决问题的思路也从这两点开始出发:
- 把要更新的梯度矩阵做一定的划分,通过重新调度,在时间上把整个通信平摊掉;
- 想办法减少每次更新的梯度矩阵的大小,从整体通信量上做文章。
最后要达到的效果呢,也是分两方面:首先整个系统的吞吐量增加了,同时迭代的收敛速度并不受影响,不需要增加迭代次数就能达到一样的效果。
减少梯度矩阵大小用的是一个叫 SFB(Sufficient Factors Broadcasting)的技术,具体的文章在这里。
作者认为核心的瓶颈还是主要在通信上。
这里给出了一个对 Alexnet 的粗略分析(不是特别准确,但是基本上是同一个量级),假定计算跟通信能够完全 overlap 开,用 Taitan X 节点来分布式训练大约也要至少 26 Gbps 的网络带宽,这个压力对一般的以太网来说基本上是很难应对的。当然 overlap 计算和通信这事本身就很难做到了。
作者首先分析了整个训练过程的思路:
定义训练第 l 层网络的前后向为 $f_t^l$ 和 $b_t^l$,那么整个训练的计算部分是这样的:
$$C_t = [f_t^1, f_t^2, … , f_t^L, b_t^L, b_t^{L-1}, … , b_t^1]$$
加上通信同步部分,$O_t^l$ 和 $I_t^l$ 分别表示第 l 层网络参数的输出和输入(更新):
$$S_t = [O_t, I_t] = [O_t^L, O_t^{L-1}, … , O_t^1, I_t^L, I_t^{L-1}, … , I_t^1]$$
这样组成的一次 $C_t, S_t$ 就是一次迭代的完整过程了。
那么就提出了这里的第一个思路:
- 分层把通信和计算给 overlap 开,这里称为无等待的反向传播算法(WFBP)
通信的数据依赖关系只在同一层内,即: $b_t^l$ 结束之后就可以马上做 $O_t^l$ 和 $I_t^l$ 了,即第 l 层的参数同步可以跟第 l-1 以及以后层的后向计算同时进行。示意图如下:
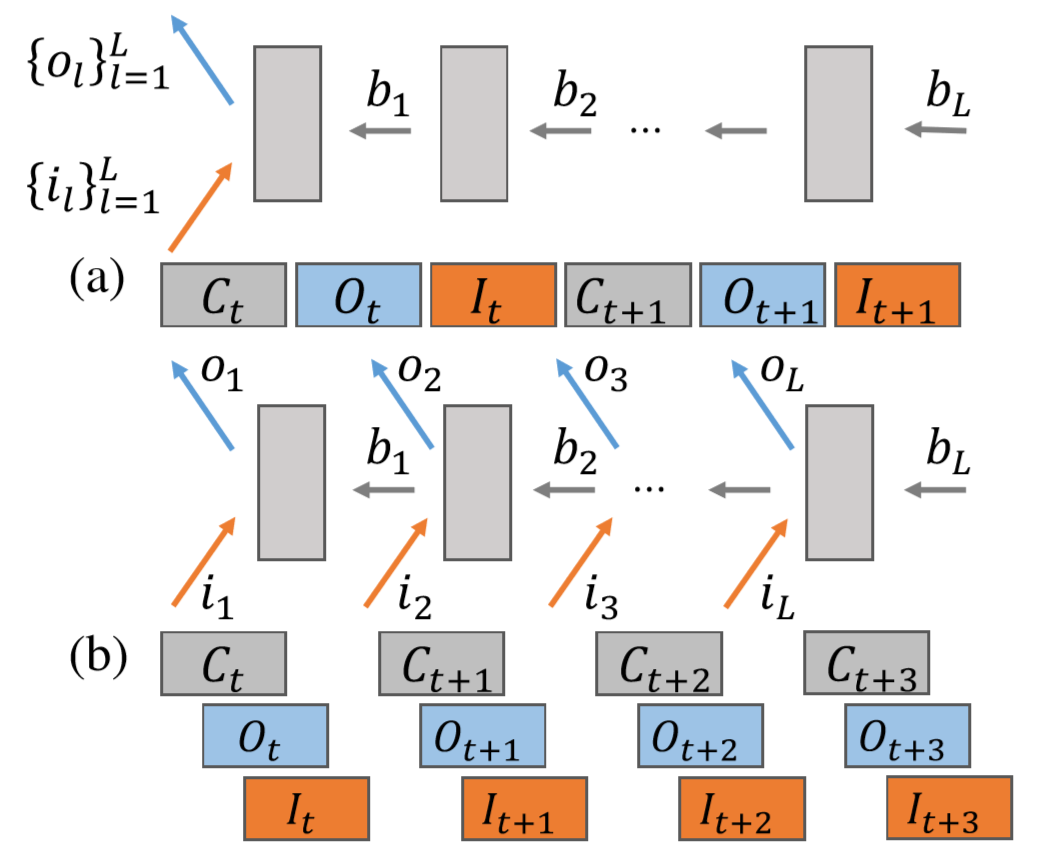
这种思路尤其适用于参数集中在后几层(例如后几层是全连接),然后计算集中在前几层(例如前几层是卷积)这样的网络(例如 VGG 和 AdamNet),这样就能把顶层的通信时间掩藏在底层的计算时间中。
大概是这种样子:
$$
\begin{align}
[C_t, S_t] = [f_t^1, f_t^2, … , f_t^L, b_t^L, &b_t^{L-1}, b_t^{L-2} … , b_t^1] \
&[O_t^L, O_t^{L-1}, … , O_t^1] \
&\qquad [I_t^L, I_t^{L-1}, … , I_t^1]
\end{align}
$$
但是这样对于带宽受限的网络来说仍然不够,所以有了接下来的第二个思路:
- 采用 PS 和 SFB 混合的通信机制
正如上面所分析的,事实上不只是神经网络不同层的计算和通信可以无关,不同层之间的通信也是完全可以独立的,因此考虑对不同层数据的特点采用不同的方式进行组织通信。PS 模式或者 SFB 模式:
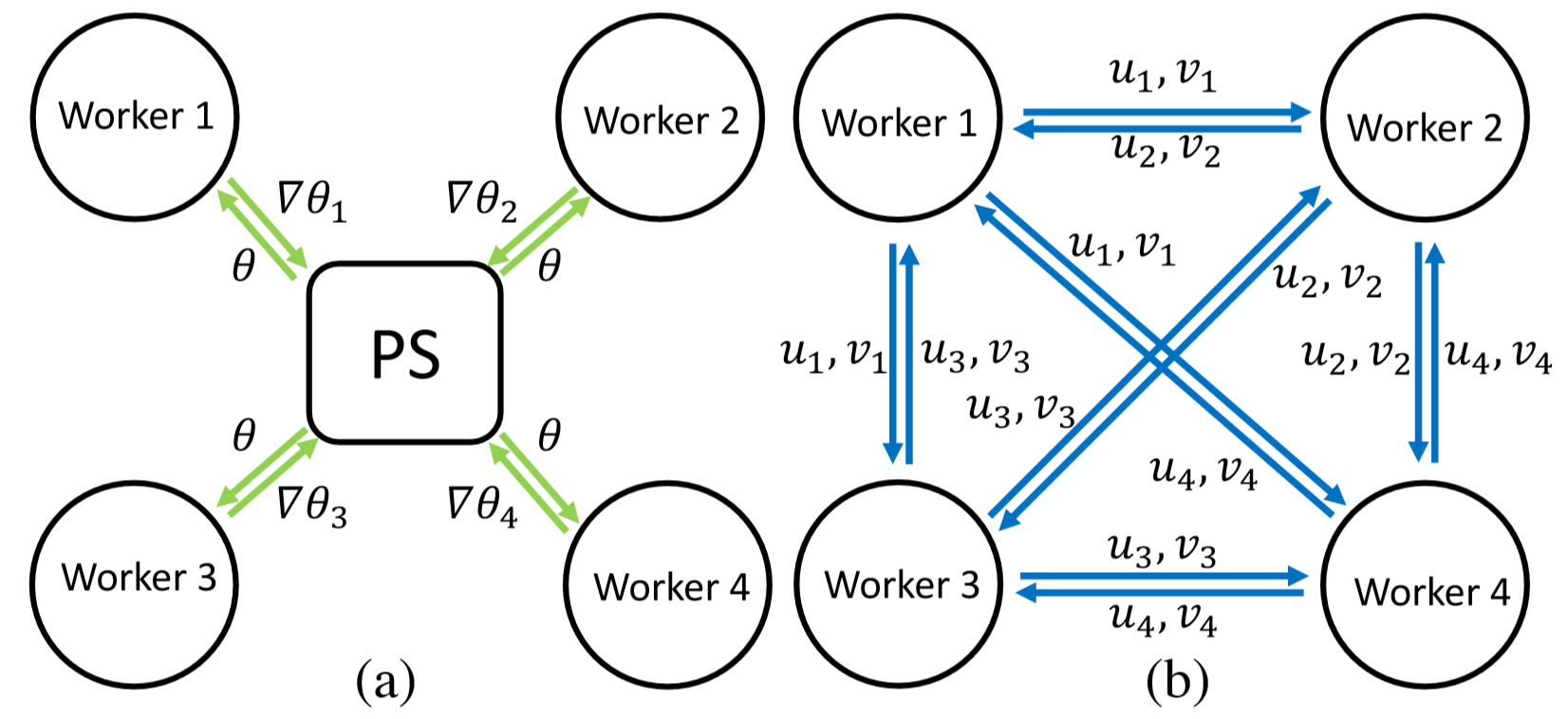
并且神经网络的结构是只要训练开始了,自始至终都不会再改变,因此可以事先算出参数的总量来估计整个网络会产生的通信开销,在训练开始前就能够选择合适的通信组织方式。
这里又举了个例子:
VGG19,假定 batch size K = 32,8 个 PS 和 8 个 Worker,参数均分在 8 台 PS 上,全连接层 M 和 N 都是 4096。2 个全连接层每一步迭代产生 2 * 4096 * 4096 = 34M 个参数。
PS 模式下:每个 Worker 每次要发送 34M 个参数,每个 PS 管 34M/8 个参数,但是要从 8 个 Worker 那里接收,所以总的通信数据量还是 34M。如果实际物理机就 8 台,每台上面跑一个 PS 和一个 Worker,那么每台机上本地更新 34M/8 的数据,每次要送出去 7/8 * 34M 的数据,再收回来 7 个 34M/8 的数据,一共 2 * 7/8 * 34M = 58.7M 的数据量。
SFB 模式下:(这种通信模式我还没细看,所以不知道为什么这么算)没有 PS,直接是 8 个 Worker 进行数据处理,每个节点需要负责的通信量只有 2 * K *(M + N)(P1 -1) = 2 * 32 * 8192 * 7 = 3.7M 的数据量。虽然收到数据之后要恢复成梯度矩阵需要额外的运算,但是这跟节省下来的通信时间相比是可以忽略不计的。
卷积层的更新梯度由于是不可分解的,并且是稀疏的,所以还是采用 PS 模式更好。
所以根据不同层的参数特性采用不同的通信机制的方法是有很大潜力的。
整个 Poseidon 系统的设计分成三个部分:
- Coordinator:用于维护网络模型和集群设备之间的配置关系
集群中 worker 和 ps 的数量,对应的 ip 地址,网络模型的结构等等。负责建立各节点之间的通信端口,分析网络模型,决定哪些参数用 PS 哪些参数用 SFB。
当然这些数据是在初始化的时候就完成了。
- KV store:一个共享内存的键值对存储部件,其实就是 Parameter Server
为什么这里的 PS 要突出”键值对“这个概念呢?
Poseidon 在这里做了一个操作,参数不是按照层来划分的(!!!),而是把所有的参数按照 2MB 划分之后再均分到各个 PS 上去,这样就能保证每个 PS 上面存储的数据量尽可能地一致,让各个节点需要的网络带宽尽可能地平均。
另外还有 checkpoint 的设计,保存多个阶段的参数用于容错恢复等等。
- Client Library:用于适配到不同的深度学习框架中
对每个层都单独创建一个 syncer 负责处理其参数一致性。
在 CPU 上维护一个线程池(用于后台处理网络通信),在 GPU 上维护一个 stream 池(用于后台处理 CPU 和 GPU 之间的数据拷贝)。
之前作者的文章里面也提到了 BSP 的收敛性相对异步来说始终还是更稳定的,有了上面那个分层同步、通信几乎完全掩藏在计算背后的设计之后,BSP 跟异步之间的延迟差距可能已经能够减少到足以忽略的程度了。
因此在参数一致性方面的维护上,Poseidon 直接采用了 BSP 同步。
worker 这边,每个 client library 维护一个长为 syncer 数的 01 向量,每次迭代开始前初始化为 0,当一层的数据同步完了之后设为 1,当整个向量全 1 时就可以进入下一个迭代了。
PS 这边,KV stroe 在每次迭代开始前维护一个值为 0 的计数器,每当有一个 KV 更新计数加一,当计数器达到 worker 的数量时,发起一次参数广播。
整个训练过程的伪代码:
1 | function TRAIN(net) |
后面是 evaluation,测试结果就是很强…各方面都很强。
2015 - Poseidon: A system architecture for efficient GPU-based deep learning on multiple machines
这篇 paper 是在上面那篇发出来之前放在 arxiv.org 上的,应该算是正篇前的一些基础工作,看完 2017 年的正篇再看下这个。
2017 - Can Decentralized Algorithms Outperform Centralized Algorithms A Case Study for Decentralized Parallel Stochastic Gradient Descent
又一篇去中心化思路的文章。
To be read.
2017 ICML - Device Placement Optimization with Reinforcement Learning
Google 做的关于模型并行中 Op 和 Device 对应关系的研究。
在多块卡上做模型并行时需要考虑把整个网络的哪些部分分在哪种设备上,这篇文章的思路是先生成一套 Op 和 Device 的对应关系,然后扔进 TensorFlow 里面跑,跑完结果再反馈到一个强化学习的网络里面去,让网络去自动重新调整 Op 和 Device 的对应关系,直到得到一套最高效的分配方案。
666666!
2017 - ChainerMN: Scalable Distributed DeepLearning Framework
下面列的那个 15 分钟跑完 ImageNet 的日本机构用的是他们自己写的框架,名字就叫 ChainerMN。
To be read.
2018 NIPS - Pipe-SGD: A Decentralized Pipelined SGD Framework for Distributed Deep Net Training
刚刚看到的一篇 NIPS 的工作,嗯,从题目就基本上可以知道写的是啥了。
Introduction 中首先讨论了一下网络层、数据量的增长带来的计算量的需求,尽管各种神经网络加速器(GPU、ASIC 等等)和并行计算的发展缓解了很大的压力,从另一方面却更加剧了多机通信的 Overhead 造成的影响,毕竟前后向的计算时间是减少了,但是通信时间不变啊,在整体一次训练迭代中占的比重就增大了。
这篇文章首先分析了神经网络训练过程中的通信时间和计算时间的关系,然后提出了一套模型来评估各方面因素对它们的影响(例如延迟、集群规模、网络带宽、神经网络模型等等),在这套评估模型的基础上接下来推出了 Pipe-SGD 框架来实现他们想要的训练机制,最终在评估测试中得到了很好的结果。
Background 部分是对神经网络以及分布式训练的介绍,值得一提的是最后提到好多人为了减少通信时间会采用压缩的方案,例如低比特量化、传输时直接扔掉某些层的梯度等等。
既然 Background 里面提到了压缩,说明后面他们的框架中也有压缩方面的工作。
下图分别是中心化的 PS-Worker 异步模式、去中心化的同步模式以及本文的流水线模式的示意图。

马后炮一下,看到 c 图的时候我惊了一下……大概去年年底的时候也想到了类似这种思路,无奈限于一直做的框架都是 TensorFlow,没想到应该怎么在 TF 里面实现,于是一直没有把想法变成实现。
另外一点是,由于 TensorFlow 本身的数据流设计,一轮迭代中的计算和通信本就能够很大程度上自动 overlap 起来,因此即使在 TF 中实现了也可能意义不大。
这里把每一次的训练迭代分成三个部分:模型更新、梯度计算、梯度传输。
在一个常规的同步训练过程中,每一轮迭代中的三个部分是相互依赖的,如果用 T 表示总的训练迭代次数,则整个训练时间可以表示成这样:
$$ l_{total \_ sync} = T * (l_{up}+l_{comp}+l_{comm})$$
Pipe-SGD 的思想呢则是把这种通信和计算的依赖关系解开,如果一个 Worker 上是多条流水线交替进行,则通信和计算的时间就有机会完全 overlap 开了,本轮迭代的数据只与前 K 轮的迭代数据相关,而相邻的两次迭代之间则完全没有依赖了。在这种方式下,总的时间可以表示为:
$$l_{total \_pipe} = T / K * (l_{up} + l_{comp} + l_{comm})$$
更进一步的分析是,由于网络中的计算和通信时间往往很难完全对等起来,事实上整个计算过程是资源受限(Resource Bound)的,则最后实际受限的结果是要看计算和通信哪部分更花时间:
$$l_{total \_pipe} = T * max(l_{up}+l_{comp}, l_{comm})$$
下面更进一步地给出了一个更详细的时间模型,把网络延迟、模型的参数量、传输带宽、worker 数量等等都包含在内了,最终分析完了给出了这样一个结论:
Pipe-SGD 选择 K=2 为最佳,整个计算过程是计算受限的,并且应该采用顺序的梯度传输原则。
这里的顺序梯度更新原则指的是把梯度计算和梯度传输这两个过程完全分开,即计算完整个网络的所有梯度之后再一次性传输完,在 TensorFlow 中默认并不存在这种分离关系,可以认为是自动的分层梯度传输,一层梯度算完之后马上就可以开始传输过程,并且这个传输并不影响后续其他层的梯度计算。
…… 话说我觉得这里的结论直接想也很容易得出来啊,可能严谨的数学模型推论就是人家为什么能中 NIPS 的原因吧。
另外还有为什么这里要特意提到压缩呢?
下图的 a 是无压缩情况下的通信和 Reduce 计算关系,可以看到即使采用了流水线的方式,Reduce 的实现序列上还是会有大量的空闲。

而如 b 图所示,梯度压缩操作减少了传输时间,但却会略微增加一些计算量,而这种增加的计算量到了流水线中反而可以很好地被隐藏掉。
。。。
最后的实验验证部分说实话我是比较失望的,4 台单 GPU 节点组成的集群实在不是个太大的规模啊……而且这里也没有给出与其他框架的对比性能来。
2018 - Beyond data and model parallelism for deep neural networks
看的时候这篇文章还在 SysML19 审稿中。
主要工作是建立了一套名为 SOAP(Sample,Operation,Attribute,Parameter)的并行方案搜索空间,设计了一个专门的模拟器来评估要训练的神经网络的性能情况,然后在这个搜索空间里面找到最佳的并行方案。听上去有点玄,不过摘要中说可以达到比 State-of-the-Art 还要大 3.8 倍的吞吐量,还是很厉害的。
Introduction 部分提了下 DNN 并行的大背景,目前市面上常见的框架中都只是提供了一些简单的并行方案,要达到理想的性能通常需要研究者自己去根据网络的特性手工调整。举例来说 Google 14 年有个把前半部分的卷积用数据并行,最后的全连接改用模型并行的方案,以及 Google 对自己机器翻译模型做的一些并行方案设计。另外还有依靠强化学习等方法去找到最佳的并行方案(例如 Google 的模型并行设备分配工作,以及这里引用了另外一个他们自己的工作)。
Google 对模型并行做的强化学习每次是试跑一遍得到实际执行时间来作为一种方案的结果(常规操作没毛病),因此当搜索空间很大的时候就不可避免地需要花费很长时间。那这篇文章的关键就在于他们模拟器的设计,用模拟器直接评估网络的执行性能自然是是要比实跑快很多的(这里说快了好几个数量级),问题是这样评估出来的结果是否可靠?
文章主要的依据有两个:
- 大多数神经网络的模型都是由常见的结构组成,只会有很少量的特殊网络层;
- 神经网络每一层的运行时间基本上只与硬件本身相关,输入规模固定之后基本不会受其他因素影响。
因此文章中的模拟器的做法是预先得到不同输入规模下各个网络层的执行时间,之后再用这些数据来评估网络模型的执行时间。相比 Google 的做法,这样可以更快,而且速度快了以后整体的方案搜索过程对硬件资源的需求也就少的多了(Google 用了 160 个 4 GPU 节点,本文只需要单个节点)。后面对优化方案的搜索采用的是马尔科夫链蒙特卡洛的方法,然后各种测试的效果都很不错。
相关工作的对比里面还有提到用网络流来优化任务调度的(666666)。
Large Scale Neural Network Training
这个分类下面主要是实际应用层面的工作。
2013 ICASSP - Building High-level Features Using Large Scale Unsupervised Learning
谷歌做的无监督学习图像分类的工作。
在一个超过 1000 个节点的集群上用了模型并行和异步 SGD。
文中的网络叫稀疏深度自编码器(Sparse Deep Autoencoder),基本上跟现在的 DNN 差不多,应该是当时深度学习这个概念还没有完全定型。
实现方面没有具体写的很清楚,主要参看前面12年NIPS的那篇工作吧。
这里的几篇各家拼 ImageNet 训练速度的笔记整理到新帖里了: