这个月十几号的时候索尼发了篇论文,224 秒跑完了 ImageNet……想想大概去年的这个时候还是 Facebook 和 UCBerkeley 在 ImageNet 的大规模方面你争我赶,不得不感叹时间过得真快。
去年毕业开题大概开的也是这个方向,然后前段时间面试的时候:
面试官:你最近做了什么?
我:我 follow 了 FB 和 UCB 他们在 ImageNet 上做训练的工作,大概试了下他们论文里面的想法。
面试官:哦,那你最多用到多少卡?
我:e……最多跑到 16 块 V100。
说完这句自己突然感到一阵尴尬,人家工作多少块卡我多少块卡?真好意思说复现……(捂脸)
然而我也没办法啊,实验室资源已经算不少了,我还想拿一块卡假装模拟两块卡用呢。0.0
Anyway,趁着正好要读大法的论文,把之前其他人的东西都理一理。
前面这几段笔记还是去年的时候写的,看了下过了这么长时间,有的已经正式发了论文了,有的是 arXiv 上有了新版,那就下新的重新看一遍吧。
还是留下 OneDrive 的链接:
要说其他更多的材料的话,其实这几年在 ImageNet 上面冲分的有很多,Stanford 做过一个 DAWNBench,上面也记录了好多研究者跑 ImageNet 的最短时间、最小开销等等:
Papers
2017 Facebook - Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Facebook 做的大规模 GPU 集群训练,顺便推一波 Caffe2。
256 块 GPU,1 小时内跑完整个 ImageNet 的数据集训练,想想都可怕。
这篇文章主要是从一个“炼丹师”的角度来写的,主要关注在学习率、minibatch 等等之间的关系,以及它们对训练带来的影响。文章的主要工作是提出了一种根据 minibatch 大小调整学习率的扩放规则,以及一种在训练时预跑的机制。
这些可能大多都是训练中总结出来的一些 tricks 吧。
随着网络模型和数据规模的不断增长,训练时间也跟着增长了,为了保证训练时间能够保持在一个有意义的限度之内,需要一些额外的工作。
文章的立足点是通过增大训练时的 batch size 来加快训练速度。例如 ResNet-50 这个网络通常大家采用的 batch 大小是 256,在 8 块 P100 上大约需要 29 个小时才能跑完整个 ImageNet 数据集(应该指的是原始的 ResNet 论文)。
但是如果加大 batch size 呢?改变 batch size 会影响到最终的收敛和训练结果的正确率。
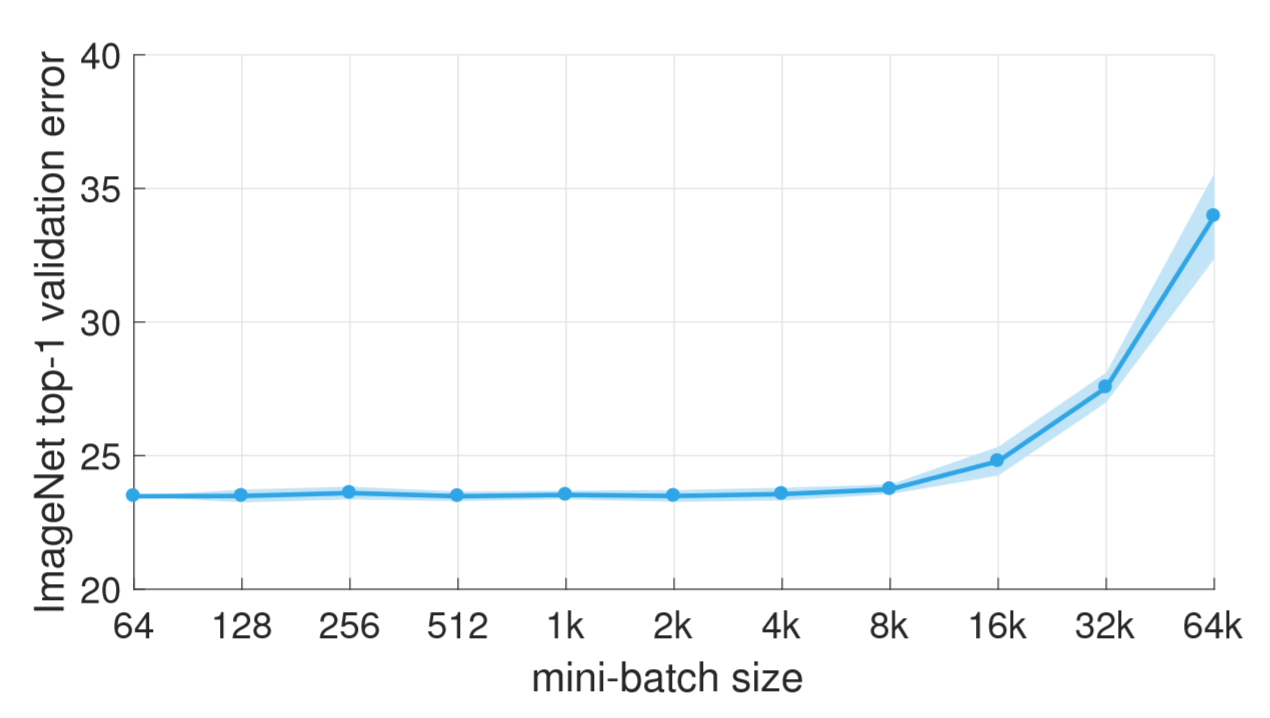
文章接下来的工作就是通过调学习率等等其他的一些方法,把加大 batch size 带来的影响控制在一个可接受的范围内,最终做到 8192 个 batch 训出来的结果跟原本的效果持平。当然最重要的,batch size 增大了 32 倍,总的训练时间也能够降下来,用 256 块 GPU 在 1 小时内训完了整个 ImageNet!
为了维持训练结果的准确率,他们在过往积累的大量经验上得出了一个令人难以置信地简单却又有效的规则:
- Linear Scaling Rule:minibatch 扩大 k 倍,学习率也扩大 k 倍。
其他超参数维持不变就好。
多次测试之后,可以发现应用了上面这个规则时,不同 minibatch 的 SGD 不仅最终准确率非常接近,而且训练的收敛曲线都是非常相似的。
但是在两种情况下,前面讨论的一些假定会有问题:
训练初始的几个 epoch 可能会引起网络参数巨变
在某些网络中,如果一开始设的学习率太大,初始的几个 epoch 会产生过大的梯度,上面这条规则就可能不太适用了。为了解决这个问题,文章于是提出了预热训练的阶段。
minibatch 的大小不能无限增长
就拿前面 ResNet-50 为例,这个规则只够保证 minibatch 在增长到 8192 的时候能维持训练效果,再大就保证不了了。
接下来是训练预热的机制:
- Gradual warmup:预训练时先用一个比较小的学习率,然后爬坡增长,逐渐增加到目标需要的 k 倍
经过实践调整之后,他们的实现里面是经过 5 个 epoch,学习率逐渐从$\eta$增长到$k\eta$。
分布式 SGD 在具体实现上还有很多细节的地方,可能稍微变动一下就会影响到整个模型的超参数,这里提了几个注意点吧:
- 权重衰减:交叉熵 loss 的扩放并不等价于学习率的扩放(?)
- 动量修正:如果用了像 Momentum SGD 这种方法,需要在改变学习率之后再应用动量修正
- 梯度聚合:用整个 minibatch 的大小 kn 来均一化每个 worker 的 loss,而不是每个 worker 负责的 n
- 数据清洗:先对训练数据做 shuffle 再把他们放到不同的 worker 上
关于我最关心的梯度聚合的实现,他们没有采用 Parameter Server 的形式,而是所有 worker 直接做 allreduce。
Allreduce 分成 3 个阶段:
- 每个节点的 8 块 GPU 的数据合并到同一个 buffer 上
- 所有节点对数据进行汇总做 allreduce
- 每个节点的梯度更新完之后再广播到各自的 8 块 GPU 上
1、3 两个阶段的操作,如果数据量大于 256 KB 则用 NVIDIA 的 NCCL 库来完成,否则就简单地各自把数据传回 CPU 再做汇总。
阶段 2 用到了递归二分倍增算法以及令牌环算法……嗯,基本上也没有什么特别的,就是想办法高效实现 all_reduce 和 all_gather。
软件栈用的是 Facebook 自家开源的 Gloo,具体的通信方面都是靠这个通信库来完成,就不涉及到具体的实现了(……)。以及 Caffe2。
硬件是 Facebook 的 Big Basin GPU 集群。每个节点是 8 块 NVLINK 的 P100(DGX-1),50 Gbit 的 InfiniBand。
预估一下 ResNet-50 的数据量:大约参数量是 100MB 左右,单 P100 跑完一次大约 120ms,也就是峰值带宽大概要在 100MB * 2 / 0.125s = 12.8 Gbit/s 的程度,加上一些额外的 overhead 应该不会超过 15 Gbit/s,对这套 IB 来说完全不是问题。
后面的训练设置描述得很详细,包括很多超参数要怎么取值,卷积层和全连接层参数的初始化分别采用不同的方法等等。
单节点的 baseline 是 8 卡(k=8),每块卡的 BatchSize 是 32(n=32),相当于单机一轮的 BatchSize 是 256,90 个 epoch 之后得到了 23.6% 的错误率,表现可以说是非常不错了。
多机训练的时候上了 32 个节点,一共 256 块卡,总的 BatchSize 达到了 8k,相较单机扩大了 32 倍。如前面所描述的,单机训的时候学习率选在 0.1,这里则是从 0.1 开始经过 5 个 epoch 逐渐增长到 3.2,即原来的 32 倍。用了这套 Gradual warmup 的预热机制之后,最终网络收敛在了 23.74%,几乎与单机一致了,并且从测试结果中可以看到后期甚至是连 error 的下降曲线都是基本一致的。
效率方面,他们使用的这套 Allreduce 算法得到了非常好的效果,基本上已经可以看到线性的性能表现。
做大规模训练的话,这篇论文基本上可以说是教科书级别的示范了。
2017 - Extremely Large MinibatchSGD Training ResNet-50 on ImageNet in 15 Minutes
上面 Facebook 用 256 块 P100 做了大 minibatch 的 ImageNet 训练之后,感觉军备竞赛就开始了。
这是日本的一个研究机构,用 1024 块 P100,更大的 BatchSize!!15分钟跑完了 ImageNet。
完成这个任务主要有两方面的挑战:
- 算法层面,使用更大的 BatchSize 之后,要想办法防止精度的损失;
- 系统层面,需要设计一套方案来有效地利用上可用的硬件和软件资源。
这里给了个表,对比了一下目前用 ResNet 跑 ImageNet 的几个工作:
| Team | Hardware | Software | Minibatch size | Time | Accuracy |
|---|---|---|---|---|---|
| MSRA(ResNet作者) | Tesla P100 * 8 | Caffe | 256 | 29 h | 75.3% |
| Tesla P100 * 256 | Caffe2 | 8192 | 1 h | 76.3% | |
| SURFsara | KNL 7250 * 720 | Intel Caffe | 11520 | 62 m | 75.0% |
| UC Berkeley | Xeon 8160 * 1600 | Intel Caffe | 16000 | 31 m | 75.3% |
| This work | Tesla P100 * 1024 | Chainer | 32768 | 15 m | 74.9% |
嗯…话说,本来以为 UCB 最发的文章是在 KNL 上跑的,刚刚才发现他们当时最新的工作是用居然是 8160(这可是通用处理器啊???害怕,下面那篇真得好好看看了)
具体的实现,这里说是参照 Facebook 的工作做的,比较额外的就是加大了 BatchSize,然后软件方面换了他们自己写的 Chainer 框架,因此这块写的比较简略。可能还有个差别是这里用了 RMSprop 吧,另外也提供了他们所使用的 RMSprop 的 Warm-up 方案。
NCCL 和 OpenMPI 意味着他们写的这个框架是基于 MPI 做的通信,而且还做了卡间数据传输。主要还是用的同步模型,然后做 Allreduce。
训练用的单精,然后划重点,为了减少通信的数据量,数据传输的时候用的**半精浮点**!!测试之后发现对结果影响不大(666666….)。
硬件方面,双路 E5-2677,8 块 P100 的配置,应该是没有 NVLINK 的,IB 用的 FDR(56 Gbps)。
2017 UC Berkeley - 2018 ICPP - ImageNet Training in Minutes
2018 年更新,这篇已经发在了 ICPP 上,也增加了很多内容,基本上已经是一篇新的文章了
接下来上台的是 UC Berkeley。
最早看到他们 arXiv 上的论文版本写的是 24 分钟跑完,可能被同期其他同行的工作刺激了一下,后来更新把标题里面的 24 去掉了,最终实现里面确实也是把这个时间缩短到了 10 分钟的量级。
他们家应该是跟 Intel 合作,用的是 Intel Caffe 和 Intel 的计算设备。
17 年的论文中使用了两种硬件方案:
- Xeon Platinum 8160(Skylake 的 Xeon 通用 CPU)
- Intel Xeon Phi 7250(KNL)
18 年的正式版本还额外增加了 P100 的测试内容。
基本的结果是:2048 颗 8160 用 11 分钟跑完 100 个 epoch 的 AlexNet,准确率收敛在 58.6%;2048 块 KNL 用 20 分钟跑完 90 个 epoch 的 ResNet-50,然后 14 分钟跑到 64 个 epoch 的时候就已经收敛到 74.9% 了。
他们不出意外地也用了同步的更新策略,这里给的理由是同步可以保证整个计算过程的确定性,并行实现与串行实现的行为是一致的,这一点在设计和调试以及优化网络的时候尤其重要。有一些前人的工作也证明了异步的方式是不稳定的(例如 Revisiting Distributed Synchronous SGD 以及前面 Facebook 的工作等等)。
异步策略会引入更多的影响因素,而且由于各个 worker 上的参数存在延迟,对整体的算法收敛也会有影响。话说前面几篇论文里面提出的优化方案也是,在异步训练的时候完全是不同的表现,不能直接适用过去。
Introduction 最后点了一下这篇论文的一些要点:
- 本文证明了大规模的 CPU 集群也能跑的很好,面对 GPU 并不是没有一战之力(Skylake 这一代的 Xeon 是真的强啊)。这篇文章应该也是当时使用 Intel 的硬件达到的最好结果。
- 本文使用的名为 LARS 的优化算法在 AlexNet 和 ResNet-50 上都表现得非常好,目前大部分效果比较好的新网络都是类似 ResNet 这种特征(言下之意 LARS 同样能在那些网络上跑的很好)。然后轻点一下同行 Facebook 的工作,说 LARS 比他们的要好!
嗯……Related Work 里面把前面两篇文章都提了一下,还是很有趣的。
第三章分析了一下大 Batch 训练的好处。理论上改变 BatchSize 是不会影响到一个 epoch 的总浮点计算量的,但是随着单个 step 的 BatchSize 的增长,一个 epoch 需要的迭代次数就减少了,整体通信的次数也减少了。
总之整体的运行时间可以减少,最理想情况当然是可以做到线性。表中给的总时间应该是以 GPU 数量取 log 来作为一次通信的 overhead 影响因子,因为这里考虑的是 Allreduce 同步的通信方式,log 级的估算基本上还是可以接受的。
话说我觉得这个问题还得换个角度更深入考虑一下,一个 epoch 中通信的次数减少了,但是如果增加节点数就意味着单次通信的总数据量要增加,最后还是反映在带宽上。
另一方面 BatchSize 变大之后单个 step 的计算时间也增大了,说起来通信这部分的 overhead 可能也更容易被 overlap 在计算时间之后。这里还只是一些比较模糊的定性讨论,数据并行能不能达到线性增长还是得看通信带来的 overhead 有多大和实际跑的结果。
另外一个原因是说大 Batch 可以提高 GPU 的利用率。
我觉得本来跑满一块 GPU 应该是基本吧。
其实像前面 Facebook 的工作,单块 P100 能够支持的 ResNet-50 的 BatchSize 应该远不止 32,不知道他们最后训的时候 P100 的使用率大概是个什么情况。当然他们也有实际收敛效果方面的考虑,以他们当时的优化策略还并不能够保证 BatchSize 再大以后的收敛性能。
在模型的选择上,他们提出了一个扩放率的概念,即计算和通信的比率,对比 AlexNet 和 ResNet-50 这两个网络:
| Model | Communication # parameters |
Computiation # flops per image |
Comp/Comm Scaling Ratio |
|---|---|---|---|
| AlexNet | 61 Million | 1.5 Billion | 24.6 |
| ResNet-50 | 25 Million | 7.7 Billion | 308 |
ResNet-50 的扩放率大概是 AlexNet 的 12.5 倍,所以 ResNet-50 的可扩放性更好,能达到更高的弱扩放效率。
但同时大 Batch 也会带来一定的问题,比如 BatchSize 不能无限往上加,大到一定程度之后,准确率就降下来了。所以后面的重点就在于怎么调整学习率这些超参数来保证增大 BatchSize 之后的训练效果(LARS 登场预告)。
基本的原则跟 Facebook 提出的观点一致:
- Linear Scaling:BatchSize 增大多少倍,学习率也要增大到相应的倍率;
- Warmup Scheme:初始的学习率不能太大,要在开始的几个 epoch 里逐渐增长到目标的学习率为好。
但是比 Facebook 的工作有了更深入的研究:
他们发现不同层参数和梯度的二范数比值($\frac{||w||_2}{||\nabla w||_2}$)差距可能会很大,例如 AlexNet 中第一个卷积层和第一个全连接层的比值可能会差上千倍,猜测这个会成为影响大 BatchSize 训练精度的一个重要原因。
于是他们提出了 LARS(Layer-wise Adaptive Rate Scaling)算法来分别控制每一层的学习率。
666666
整体算法如下:
- 分别计算每一个参与训练的参数的学习率:$\alpha = l * \frac{||w||_2}{||\nabla w||_2+\beta||\nabla w||_2}$,这里 $l$ 是一个缩放系数,$\beta$ 用于控制权重衰减;
- 分别计算每一层的学习率:$\eta = \gamma * \alpha$,$\gamma$ 是一个用户控制的超参数,按照线性缩放设置就好了;
- 对梯度应用权值衰减:$\nabla w = \nabla w + \beta w$;
- 最后的更新量:$a = \mu a + \eta\nabla w$,$\mu$ 是扰动量
- 更新参数:$w = w - a$
把一个算法扩大规模到更多的处理器上时,通常通信都会成为最大的 overhead。
所以这里从两个角度分析了通信比计算慢这一点,首先是硬件运算力(每个 flop 需要花费的时间,例如 P100 的峰值性能是 11TFlops 左右,$\frac{1}{11TFlops}$大约是$0.9*10^{-13}s$左右)会远小于理论传输速度(这里用的是$\frac{1}{Bandwidth}$,例如 56Gb/s 的 FDR,大约是$0.2*10^{-9}s$的水平),远小于延迟:
$$Time-Per-Flop << \frac{1}{Bandwidth}<<Latency$$
去年的论文中还分析了在 45nm 工艺的 CMOS 处理器上,通信消耗的能量也会比计算更大:
| Operation | Type | Energy(pJ) |
|---|---|---|
| 32-bit Int Add | Computation | 0.1 |
| 32-bit Float Add | Computation | 0.9 |
| 32-bit Int Multiply | Computation | 3.1 |
| 32-bit Float Multiply | Computation | 3.7 |
| 32-bit Register Access | Communication | 1.0 |
| 32-bit SRAM Access | Communication | 5.0 |
| 32-bit DRAM Access | Communication | 640 |
能量这个角度比较神奇,感觉应该体现的不是很明确,正式论文中已经删掉了这一段。
设总的 epoch 数为 E,图片数为 n,BatchSize 为 B,网络参数为 |W|。
当 E 和 n 保持不变的时候,总的计算量是固定的,总的迭代次数是 $E* \frac{n}{B}$,通信量是$|W|*E*\frac{n}{B}$。当 BatchSize 增大之后,总迭代次数减少,那么通信次数也减少了,通信量减少。
感觉这里再加一个 worker 数量等等这样的参数会更好一点。
更大的 BatchSize 有利于增大计算通信比,因此更大的 BatchSize 有利于网络向大规模进行扩展。
后面的测试都得到了非常好的结果。
2018 - Highly Scalable Deep Learning Training System with Mixed-Precision: Training ImageNet in Four Minutes
这篇是腾讯和香港浸会大学合作的成果,话说 HKBU 的这几个作者之前还发过一个叫 DLBench 的各个深度学习框架性能测试的文章,没想到又看到了他们的名字。
这篇文章主要做了三件事:
- 他们在训练的时候采用了一种混合精度的方法,增大吞吐量的同时不影响最终的收敛效果;
- 比前人的工作用了更大的 BatchSize,达到了 64k,保证最终收敛精度;
- 提出了一套高效的 Allreduce 算法。
最好的成果是 2048 块 P40 在 6.6 分钟把 ResNet-50 跑到了 75.8% 的准确率,以及 4 分钟跑完 95 个 epoch 的 AlexNet。
他们搭了一套名叫 Jizhi 的训练系统(机智?):

- Input Pipeline 负责准备下一个 step 的训练数据,在上一个 step 的运算阶段准备完成以尽可能地减少 CPU 和 GPU 之间的数据传输延迟;
- 训练模块包括了模型的搭建和参数管理等等,他们对这部分增加了 fp16/fp32 混合精度训练以及 LARS 的支持;
- 通信模块包含了 Tensor 聚合和他们设计的混合 Allreduce 算法来提高整体的数据传输效率。
他们整体采用 fp16 来完成整个训练以提高整体运算的吞吐量,在额外应用 LARS 进行优化时遇到了半精范围溢出的问题。于是最终做了这么一件事:
- fp16 做完前向
- 把参数和梯度转换成 fp32 做 LARS
- 用梯度更新参数
- 把参数和梯度重新转换成 fp16
- 用 fp16 做完后向
这……
使用这套方案之后,最终在 64k 的超大 BatchSize 下 ResNet-50 能够收敛到 76.2% 的准确率。
通信方面,首先是 Tensor 聚合,由于某些卷积层的参数量特别小,直接应用 Ring-Allreduce 等等算法去发送大量的小参数可能很难把带宽性能发挥出来,所以采用一个 buffer 池来收集完成前向运算的参数,当池中的参数量达到某个阈值时,再一次性发送出去。
我倒是比较好奇这块是怎么在 TensorFlow 中实现的。
根据参数量的大小,也分别采用不同的 Allreduce,并且在多级硬件框架中采用分级的 Allreduce 方法。
基本上就是这些。
2018 Sony - ImageNet/ResNet-50 Training in 224 Seconds
再是索尼的这篇文章。
他们的成果是 2176 块 V100 在 224 秒中达到 75.03% 的准确率,以及 1088 块 V100 下达到 91.62% 的扩展效率。
为什么是这么奇怪的两个数字…
基本的思路还是跟前面的工作大同小异,他们采用了动态调整 Batch Size 配合 LARS 来作为超参数的优化策略,并且同样配合使用了 fp16/fp32 混合精度,并且在通信方面采用了 2D 环网的 Ring-Allreduce 模式(日本的研究者真是喜欢在网络拓扑上做文章,之前他们那台超算 京 也是在网络方面有独特的设计)。
2018 - Second-order Optimization Method for Large Mini-batch: Training ResNet50 on ImageNet in 35 Epochs
NIPS 2017 上有一篇论文从数学层面分析过神经网络收敛方面的问题,得出的基本结论就是训练时间更久才能填上收敛的 gap(…嗯,虽然这个从经验上早就能得出来了)。前面的各位都是在考虑怎么把随机梯度下降的 BatchSize 提上去并且同时又把训练精度控制住,比如说各种花式处理学习率,花式改 BatchNorm,动态调整 BatchSize 等等。
这篇 11 月底的新工作则是换了个思路:大 Batch 带来的问题会不会就是 SGD 本身的限制,无论是 Momentum 还是 RMSprop 本质上都只是对 SGD 的优化修正算法,那如果干脆就不用 SGD 呢?
于是这里改用了 K-FAC(Kronecker-factored approximate curvature) 这个二阶的优化方法,配合 Allreduce 和半精来做分布式训练,测试结果是要比一阶的 SGD 收敛更快,仅仅 35 个 epoch 就可以把准确率收敛到 75%。同时,使用这种方法在 1024 块 V100 上也能够在 10 分钟就把 ResNet-50 收敛到 74.9%。更进一步的优化策略(针对 K-FAC)还能再减少计算量和内存的占用量。相关工作中也说这里更多的是对 ICLR 2017 上的一个 K-FAC 工作的改进。
K-FAC 是利用各层参数得到的费希尔信息矩阵(Fisher Information Matrix)计算一个系数,再乘上参数的梯度来进行更新。数学部分先跳过了,大致的过程跟 SGD 差不太多,只是 Kronecker 系数的计算涉及到了更多的东西,相对 SGD 来说,这部分计算是额外的 overhead。
软件方面,他们的工作是在 Chainer 上完成的,这个框架平时完全没接触过,但是前面 2017 年那篇日本的工作用的也是这个,猜测应该是作者是日本的研究者或者在日本这个框架更流行吧。
以 3 层网络为例,基本的流程如下:

Stage 1、2 分别是网络的前向和后向计算,之后的 3、4、5 是 Allreduce 计算 Kronecker 系数,最后 Stage 6 用每层计算出来的系数进行梯度更新。
其他诸如学习率的调整和预热的方法这里也有用。
Conclusion
Facebook 的工作是我看到的最早在大规模训练实现这块引路的了,之后 UC Berkeley 提出的优化方案又把整个效果往前推进了一步,其他人后来的文章都是集合了当时各种高效方案的实现,最近看到的索尼的那篇应该算是这个方向的集大成了。
总结下来,基本的参考点大概有几个:
想办法增大计算吞吐量、减少通信的 overhead
- 使用同步而不是异步
- 全系统采用 Allreduce 并且针对逻辑拓扑结构设计最适合的 Allreduce 策略
- fp16/fp32 混合
应用各种调超参的 trick 加速收敛
- SGD 算法相关的各种改进和调整
- 扩放学习率到 k 倍或者动态调整 BatchSize 到 k 倍
- 动态调整学习率,LARS 分层分别使用不同的学习率
- 其他一些加快收敛的方法例如改进 BatchNorm 等等