import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv) import dicom import os import scipy.ndimage import matplotlib.pyplot as plt
from skimage import measure, morphology from mpl_toolkits.mplot3d.art3d import Poly3DCollection
# Some constants INPUT_FOLDER = '../input/sample_images/' patients = os.listdir(INPUT_FOLDER) patients.sort()
CT 数据用的是一个叫 Hounsfield 的单位,表示身体的某个部分对于 X 光的不透光性(这个好神奇…)。
根据维基百科上的数据:
|Substance|HU| |-| |Air|−1000| |Lung|-700 to −600| |Fat|−120 to −90| |Chyle|−30| |Water|0| |Urine|-5 to +15| |Bile|-5 to +15| |CSF|+15| |Kidney|+20 to +45| |Liver|60 ± 6| |Lymph nodes|+10 to +20| |Blood|+30 to +45| |Muscle|+35 to +55| |White matter|+20 to +30| |Grey matter|+37 to +45| |Soft Tissue, Contrast|+100 to +300| |Bone|+200 (craniofacial bone), +700 (cancellous bone) to +3000 (cortical bone)|
# Load the scans in given folder path defload_scan(path): slices = [dicom.read_file(path + '/' + s) for s in os.listdir(path)] slices.sort(key = lambda x: float(x.ImagePositionPatient[2])) try: slice_thickness = np.abs(slices[0].ImagePositionPatient[2] - slices[1].ImagePositionPatient[2]) except: slice_thickness = np.abs(slices[0].SliceLocation - slices[1].SliceLocation)
for s in slices: s.SliceThickness = slice_thickness
return slices
defget_pixels_hu(slices): image = np.stack([s.pixel_array for s in slices]) # Convert to int16 (from sometimes int16), # should be possible as values should always be low enough (<32k) image = image.astype(np.int16)
# Set outside-of-scan pixels to 0 # The intercept is usually -1024, so air is approximately 0 image[image == -2000] = 0
# Convert to Hounsfield units (HU) for slice_number inrange(len(slices)):
# not actually binary, but 1 and 2. # 0 is treated as background, which we do not want binary_image = np.array(image > -320, dtype=np.int8)+1 labels = measure.label(binary_image)
# Pick the pixel in the very corner to determine which label is air. # Improvement: Pick multiple background labels from around the patient # More resistant to "trays" on which the patient lays cutting the air # around the person in half background_label = labels[0,0,0]
#Fill the air around the person binary_image[background_label == labels] = 2
# Method of filling the lung structures (that is superior to something like # morphological closing) if fill_lung_structures: # For every slice we determine the largest solid structure for i, axial_slice inenumerate(binary_image): axial_slice = axial_slice - 1 labeling = measure.label(axial_slice) l_max = largest_label_volume(labeling, bg=0)
if l_max isnotNone: #This slice contains some lung binary_image[i][labeling != l_max] = 1
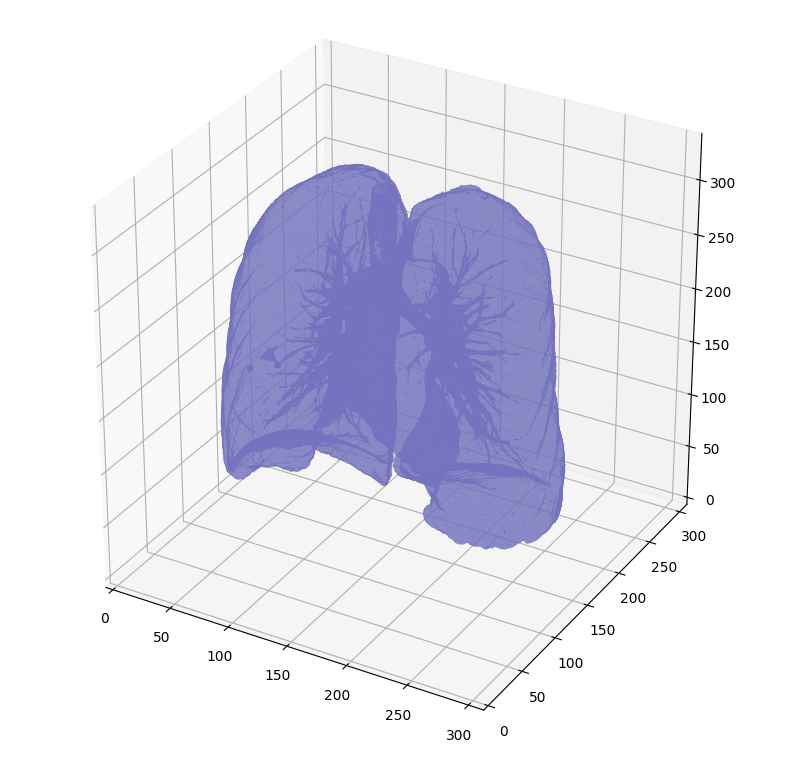
binary_image -= 1#Make the image actual binary binary_image = 1-binary_image # Invert it, lungs are now 1
# Remove other air pockets insided body labels = measure.label(binary_image, background=0) l_max = largest_label_volume(labels, bg=0) if l_max isnotNone: # There are air pockets binary_image[labels != l_max] = 0