
把去年 7 月的那篇 TF 删掉了,重新开一篇。
- 2016.07.10
初次接触 TensorFlow,当时主要是面临 RDMA 竞赛,题目的目标是 TensorFlow 的 RDMA 优化。
分析之后发现这玩意有点大,不确定是否能够来得及整个剖析一遍,只好关注于 TensorFlow 里面的通信模块(gRPC)的 RDMA 化了。
只是对 TensorFlow 的分布式版做了一些很小的测试,更多的还不太了解。
- 2016.11.07
写了个:
未来可能要花很长时间在这玩意上了。
初步确定之后有个大方向是围绕 TensorFlow 展开。
- 2016 学年末
TensorFlow 这艘大船搭上了实验室的很多人,主要是实验室看上了 TensorFlow 的数据流框架:
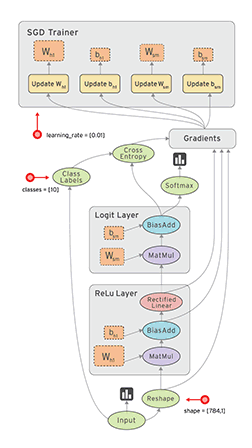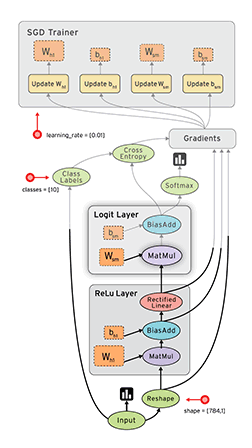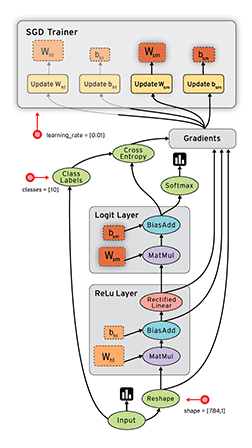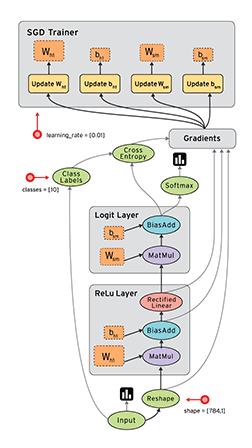
深度学习是一方面,另外的想法是是否可以以 TensorFlow 为基础,用数据流来支持其他类型的计算,如并行科学计算等等。
按之前 RDMA 优化下来的感觉,TensorFlow 的并行性能还是受 gRPC 限制,我的任务方向是着手考虑是否能够把整个 gRPC 都拿掉,用例如 MPI 等等的办法来替代其中的通信交互。
期间也见过一些其他人改出来的 “MPI 版 TensorFlow”,都是在外面跑一个 MPI 的调度框架,然后里面跑单节点版的来避开 gRPC 的影响。
Example
其他的介绍啥的暂时不写了,直接记一些干货吧。
以下是一个来自 github 的例子。
该例做的是一个简单的线性回归,即给出一些已知点来拟合一条直线。在 TensorFlow 里面可以直接视作一个训练的过程。
1 | import tensorflow as tf |
这个例子得益于优化算法完全由 TensorFlow 里面自己来实现了,所以写起来非常简单。
TensorFlow 在深度学习中的使用方法就这么简单,类似上面这个例子:
- 建立数据流图
- 在 Session 中启动数据流图,把数据喂进去
然后数据跑完一遍,留下的参数就离最优解更近一步。
之后的重点就是看看 Session.run() 以及内置的这些 tf.train.xxx 函数在代码里面是怎么实现的了。
TensorFlow Unpacking
- 2018年新年启动
开始 TensorFlow 比较完整的源码分析记录: