前篇:
- TensorFlow 拆包(一):Session.Run()
- TensorFlow 拆包(二):TF 的数据流模型实现
- TensorFlow 拆包(三):Graph 和 Node
- TensorFlow 拆包(四):Device
- TensorFlow 拆包(五):Distributed
- TensorFlow 拆包(六):RDMA
- TensorFlow 拆包(七):Profiling 踩坑 & Benchmark
严格上来说本篇不应该算在拆包里面,因为记的是 TF 团队最近发的一篇论文里面的东西。
前面拆包的第二篇记过关于 TensorFlow 中的数据流模型实现,实际上这套数据流模型已经是非常完备的,只是目前大家用 Python 搭出来的简单网络形式还很难把它的真正潜力发挥出来。
正当我们往这个方向做的时候,得,Google 发论文了。
这篇 Dynamic Control Flow in Large-Scale Machine Learning 发表在 EuroSys 18 上,系统结构方向的 B 类会议。
其实文中所提到的几乎所有内容都是 TensorFlow 原有的,或者说 TensorFlow 当初设计架构的时候就已经考虑到了未来这种使用方式的需求,这篇文章只是整理了一下这部分的设计思路(内容大部分跟以前发的控制流白皮书是一致的,见 TF 拆包第二篇),然后做了一定的测试,从实践上证明给大家看这样做是有效的。
Introduction
首先提了一下深度学习中对控制流的需求,主要是像 RNN、MoEs 这样的任务中会明确地需要一些控制流的支持。但从更宏观的角度来看,使用动态控制流对任何应用都是有用的,理论上可以比较好地地把计算和通信部分给 overlap 开,尤其对提高异构系统(CPU、GPU、TPU等等)的计算效率是有很大的好处的。
目前常见的一些机器学习框架基本上都是用数据流图的方式来组织计算。
关于如何实现数据流的控制部分,主要有两种方式:
- in-graph 方式:例如 TensorFlow 和 Theano,控制流部分可以作为一个 op 嵌入到计算图中;
- out-of-graph 方式:这也是大多数框架的常规方式,包括 MxNet、torch、Caffe 以及 TensorFlow 的常规用法,控制流部分由更上层的 host 语言来完成(主要指 Python)
除了 TensorFlow 以外,别的框架似乎都很少用数据流这个词来指代自己的设计,可能原因就在这里?其他框架虽然整体计算还是以数据流图的形式做的,但并不是真正用一套数据流的运行时去支撑的。
用 TensorFlow 来举例,方式 2 的写法通常是:
1 | python for i in range(xxx): |
多轮控制是写在 Python 层的代码中,每一次循环只跑训练的一步。
恐怕我们见到的大部分 TF 代码都是这个样子的吧。
方式 1 则是控制部分已经是图的一部分了,那最后我们只要 sess.run(total_train_step) 一次,就能够达到跟前面一样的训练效果。
单一的计算图更便于进行全图的优化,且这种实现能保证整个计算过程都停留在运行时里面(而不是像原先那样,跑一轮进退一次运行时,再跑一轮再进退一次运行时),减少很多不必要的开销。
数据流运行时的特性是一旦某个 op 的依赖都满足了,它就马上可以被调度执行了,在 out-of-graph 方式中,这种数据流的调度粒度只限定在一次 step 中,而 in-graph 方式甚至能把并行性扩展到多次 step 间,这样就能够最大程度地挖掘数据流异步、并行的能力了。
最初的 TensorFlow 白皮书中也有介绍过关于数据流部分的实现,但是并没有给出详细的设计方案以及测试结果,这篇文章就是把这部分补上。
总的来说,本文的内容包括:
- In-graph 动态控制流的设计,包括自动求导部分
- In-graph 动态控制流在 TensorFlow 中的具体实现,包括在多种异构设备上分发的能力
- 对动态控制流性能的测试,并且分析多种不同选择带来的影响
- 关于如何用好动态控制流的使用经验
话说前两部分都是 TensorFlow 原有的。。。。。。
Design and Implementation
2、3、4、5 章的大部分内容与 TensorFlow 拆包(二):TF 的数据流模型实现 中记录的类似,就不多重复了。
需要额外提一下的是,由于跨 step 的 op 有可能被并行执行,这也就意味着可能要用上更多的内存。TensorFlow 的控制流中也考虑了内存的问题,建立在 GPU 上的 frame 如果使用的显存超过某个上限则会自动做与 CPU 的内存切换的动作,把不用的部分数据换出去,把接下来要用的数据换进来。
例如 tf.while_loop() 的函数接口中就有个 swap_memory 的参数。
6666666666….
Evaluation
说实话,这篇文章的测试结果部分我觉得写的有点乱。
前面都是搬以前原有的内容,然后在本文的重点部分又写的这么乱,Google 的大佬们你们是认真的吗?
测试的系统配置是 Intel 服务器配上 K40 和以太网,每个节点一块卡,某些例子中用到了 8 卡的 DGX-1 V100。
一开始的两个测试用的是构造出来的模拟算例。
图 11 的结果感觉有点迷。
图 12 是模拟 RNN 的结构,把一个类似 8 层的 RNN 计算分布在 8 块卡上,把 tf.while_loop() 支持的并行 iteration 数从 1 调到 32,可以发现并行性发挥出来之后效果确实是挺好的,最高大约有 5 倍左右的性能提升。并行 iteration 数为 1 的时候其实就相当于跟 out-of-graph 一样。
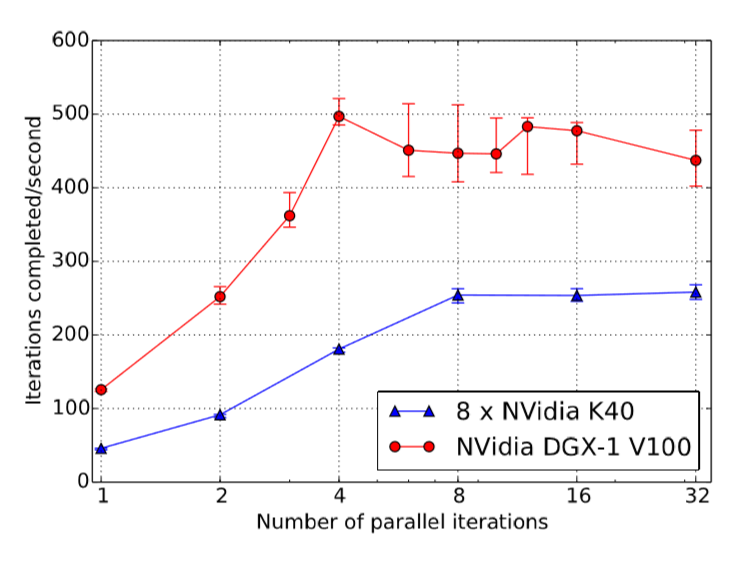
后面模型并行的测试是把一个实际的 8 层 LSTM 分布在 8 块卡上,具体的并行方式与图 12 的测试类似。在 1~8 块卡上分别测试,加速比也还可以。
接下来对一个单层 LSTM 的测试是对比是否开启内存交换。不开内存交换时,序列长度加到 600 就出现超内存的现象了,而开启内存交换则可以在保证能跑的前提下还不会损失性能。
从追踪出来的 profiling 结果中也能看到,在这种计算模式下内存拷贝和 GPU 计算 overlap 得比较好,这也是性能不受影响的重要原因。
再下一个测试是固定 LSTM 的序列长度为 200,调整 Batch Size 的大小来对比动态 RNN 和手动循环展开的效果。动态 RNN 稍微损失了一点点性能,但是差距不大。
另一方面动态 RNN 比手动做循环展开在内存方面有更大的优势,类似上一个测试,动态 RNN 开了内存交换之后可以跑更大的 Batch Size。
最后是对 DQN 强化学习网络的测试,尽管 DQN 现在已经不用了被其他更好的方法替代了(???),还是希望能从它的测试中展现一下动态控制流的效果。
DQN 中包含了多个网络,根据不同的情况需要做出许多不同的操作。使用动态控制流的方法把所有的操作都包含在一个计算图中之后,最终能够比原始情况得到 21% 的性能提升。
Summary
总结来看,这篇文章重新整理了有关 TensorFlow 中控制流部分的实现思路,证明 in-graph 方式的纯数据流实现是有意义的。但是我对它的测试部分并不太满意,用到的是模拟的 workload,说服力不够,并且感觉测试的内容还是偏少。