接上篇:
先来拆一下第一篇里面 DirectSession::Run 里面跑的那个 graph 里面到底都是些什么内容。
DirectSession::GetOrCreateExecutors
前面分析到 Executor 的时候,中间看到 DirectSession::GetOrCreateExecutors 这个函数生成了一堆 Executor,其中 CreateGraphs() 做的就是根据输入的 op 名建图的过程。
函数调用在:
1 | direct_session.cc: 1131 |
这个调用很有意思,ek 和 graphs 这两个东西都是现场创建的,传地址进去其实用来作为函数的输出结果,所以实际的输入只有 options 和 run_state_args。
run_state_args 里面保存的是一些额外的运行信息,用于调试等等。options 的 feed_endpoints 和 fetch_endpoint 分别表示的就是当前运行中的输入点和输出点。
然后看一下 CreateGraphs() 的具体实现:
1 | Status DirectSession::CreateGraphs( |
创建一个
GraphExecutionState* execution_state用于保存当前次运行真正要用到的运行图。DirectSession 对象中的 execution_state_ 成员保存的是环境中的完整的图信息。若当前次运行需要用精简的图,则从 execution_state_ 中提取出需要用到的一部分内容放进前面创建的 execution_state 中,如果不需要精简,则直接复制 executor_state_ 到 execution_state 中。
完成的图会输出到 client_graph 这个结构中。
检查输入输出的数量跟准备好的 client_graph 的输入输出是否对应
保存 Stateful placements(??不知道是干嘛用的)
用
tensorflow::Partition()把运行的图切分到当前可用的 device 上,返回的是一个std::unordered_map<string, GraphDef>的结构,放在 partitions 这个变量中对 partitions 中的每一组 GraphDef,用
ConvertGraphDefToGraph()转化成 Graph,存入前面的std::unordered_map<string, std::unique_ptr<Graph>>结构,也就是 outputs 这个指针中对图进行一定的优化,然后通过 outputs 指针返回到上一层去
Graph & GraphDef
其实 Graph 本身实现的思路还是很容易接受的,但是加上 Protobuf 定义之后就变得…
贼复杂!!!
有的地方用 Graph,有的地方又是转成 GraphDef 然后重新提取信息用。
GraphDef 是 TensorFlow 中对图的 Protobuf 定义结构,主要方便保存啊、传输啊等等,真正运行的时候要转成 Graph 这个结构用。
我原本还奇怪为什么 TF 里面的很多东西都要用字符串来唯一标识,本来我觉得对象解析这种事情应该在比较高的层次上比如 Python 那层就做完,结果这里是到底层还要用字符串。
大概很大的原因就是为了方便 Protobuf 的序列化?
下面这个链接中给出了 GraphDef 和 Graph 这两个结构的简单关系:
引用一下:
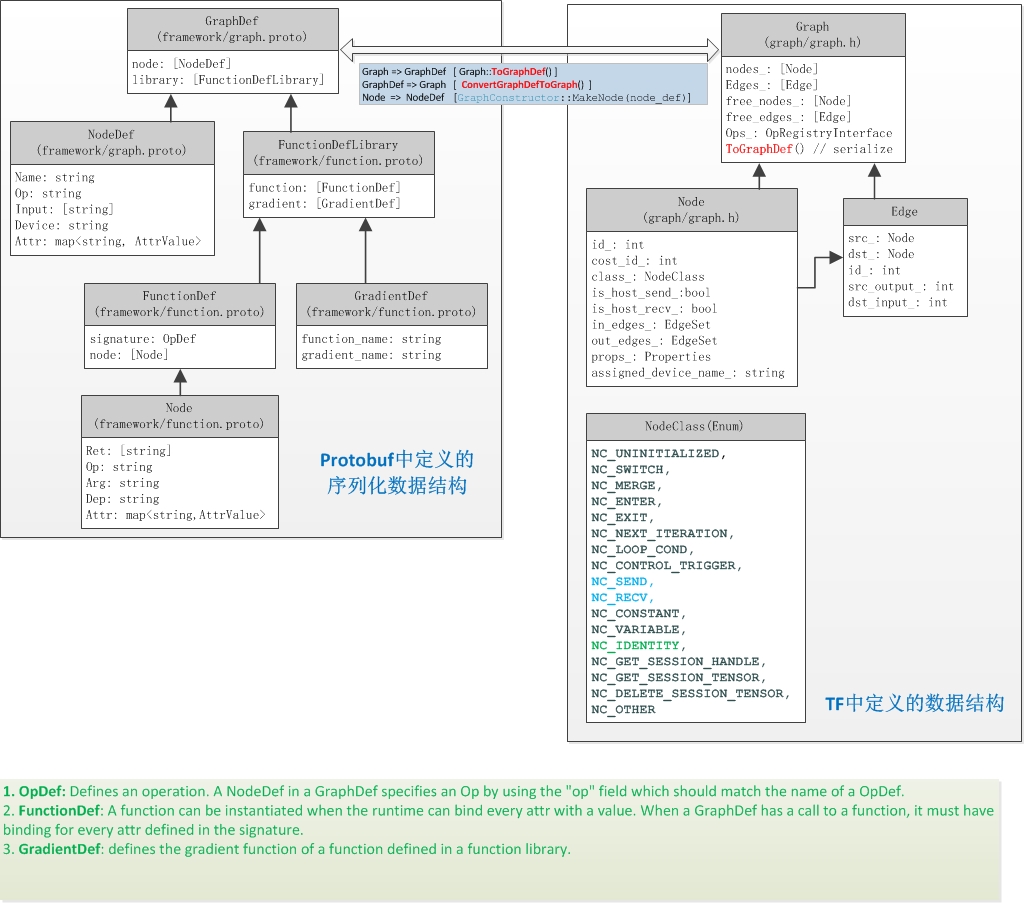
Graph in C
有关 Graph 的定义,基本上都在 tensorflow/core/graph/graph.h这个头文件里面,几个类都分的比较清晰:
Graph:表示计算图的一个大类,里面有整个图的完整结构,这里的图的定义是唯一起点和唯一终点,以及可用的计算设备表
Node:计算图中的节点,定义里面包含了当前节点的详细信息,以及输入输出的信息(输入节点、输出节点、输入边、输出边)
节点类型里面,switch、merge、enter、exit、next_iteration 这五个在上一篇里面讲了是 TF 的控制流部分,其他的也基本上是 TF 中的一些特殊用途的类型。
有关计算内容的定义似乎是要配合 Graph 中注册好的 Ops 表来完成的,这里还不是很明白这个过程具体是什么样的,猜测计算用的节点应该是属于 NC_OTHER 这种类型,具体的计算内容的定义写在 props_ 这个 NodeProperties 结构中。
Edge:计算图中的边
其他还有几个 iter,重载了运算符用来方便对 Graph 中的 Edge 和 Node 进行标识、对比什么的
用 Graph 中定义的一些函数例如 AddNode、RemoveNode、AddEdge 等等就可以轻松地把整个表示出来了。
这里的实现上很多地方是 Protobuf 的 Def 结构和非 Def 结构混用的,比如 AddNode 这个函数的输入参数是个 NodeDef,感觉很难受啊。
剩下的实现倒是没什么特别的。
Graph & Op in Python
Python 层的 Graph 定义在 /tensorflow/python/framework/ops.py 中,这个类的结构本身算是比较简单,主要就是一堆 Op 和 Tensor 的集合(_nodes_by_id和_nodes_by_name 两个dict() , _unfeedable_tensors和_unfetchable_ops两个set(),还有几个关系标识)。往 Graph 中添加 Op 的函数_add_op即把 Op 或者 Tensor 加到dict()中。
TF 中的 Python Op 有两种定义方式,在 Python 层中直接定义的 Op 函数的核心部分是:
1 | with ops.name_scope(name, default_name, value) as name: |
这个类封装。由它来找到 Op 的输入所在的 Graph,处理依赖关系以及把当前 Op 加入到 Graph 相应的列表中去。
……在代码里面搜with ops.name_scope这组关键词可以找到很多的 Op 定义。
另外一种 Op 建立方式是通过load_library.load_op_library()来载入编译好的 C 层的 Op 函数,然后包装成 Python 层的 Op。
How to organize the Op to Graph
TF 官方有个创建自定义 Op 的教程:
先通过这个来了解一下 Op 的完整运行过程。
Adding a New Op
教程中的示例是要创建一个输入一串 int32 的数组,把除了第一个数字以外的其他数字变成 0 后输出的 op。这里的创建从 C 层面开始,创建一个 zero_out.cc 文件:
1 |
|
REGISTER_OP 是一个宏,这套注册的过程是所有 op 首先要做的,打开 tensorflow/core/ops/目录下的每一个自带的 op 文件中也都是这些内容。
这个宏注册的内容是给上层的 Python 层构建 Op 封装的时候用的。
.SetShapeFn()定义了输出的形状。
然后要写的是上面这个 Op 的 OpKernel,即 C 层实际运算的部分,从 OpKernel 继承出一个新的类,重写它的 Compute 函数,Compute 就是到时候扔到 TF 运行时里面跑的内容。从 OpKernelContext 里面可以获取到这个 OpKernel 在执行时的上下文信息:
1 |
|
之后再用一个宏,把这个注册好的 Op 和 OpKernel 关联在一起,C 部分的实现就完成了:
1 | REGISTER_KERNEL_BUILDER(Name("ZeroOut").Device(DEVICE_CPU), ZeroOutOp); |
这个宏中 Name()里面是前面注册的 Op 名,Device()定义了当前这个 Kernel 函数的运算设备,最后是需要注册的 Kernel 函数名。
tensorflow/core/user_ops/fact.cc中也是一个自定义 op 的示例。
把 C 实现编译成动态链接库之后,在 Python 中调用tf.load_op_library()方法,把前面注册好的 C 层面的 Op 以及它的 OpKernel 封装成一个 Python 层的 Op 对象。
之后这个 Op 就可以像 TensorFlow 中其他自带的 Op 一样使用了。
如果需要让这个 Op 支持自动求导,只需要在 Python 中注册好它的梯度函数即可:
1 |
|
C 层还有另外两个名字很像的注册梯度函数的宏(……谁起的这名字!!!):
1 | REGISTER_OP_GRADIENT("OpName", OpGradientDef); |
到这里为止,我们对 TensorFlow 中 Python 层与 C 层的 Op 结合过程有了一个大体的印象。

那么 C 层的 Graph 构建是什么时候发生的呢?回到前面创建 Executor 时的CreateGraphs()函数,可以看到此时DirectSession 对象中的 execution_state_ 成员已经保存了当前 Session 环境中的完整的图信息了,那么 execution_state_ 中的图是哪里来的?
Back to TF_Run()
之前在TensorFlow 拆包(一):Session.Run()篇中已经对 TF_Run() 关于执行图的计算的部分进行了分析,现在需要把关注点放回到这里,看一下 Python 层中的 Graph 与 C 层中的 Graph 是如何联系在一起的。
以下是 Python 层的调用栈:
1 | #8 File "dbg_mnist.py", line 62, in simple_dnn |
从栈底开始逐步往内部看:
#8、#7、#6
Operation.run():通常我们的用法可能都是sess.run(Operation),在设置好默认的 Session 之后,Operation 类中的run()方法就是调用默认 Session 的run()方法#5
BaseSession.run():fetches 是需要得到的输出目标,feed_dict 是喂进去的输入数据#4
BaseSession._run():检查 session,设置 feed_dict,创建一个 _FetchHandler,这个结构会根据 fetches 和 feed_dict 生成一个需要得到的 Tensor 列表和需要运行的 Op 列表(大概是遍历图?),final_fetches 中存放为了运行当前 Op 所需要得到的 Tensor,final_targets 中存放为了运行当前 Op 所需要运行的前置 Op#3
BaseSession._do_run():……贼多层 API 封装,_run_fn()和_prun_fn()是两种运行方式,跟参数一起传入下一层的函数#2
BaseSession._do_call():这层封装是用来处理异常的,其实要执行的是前面传进来的两个运行函数之一#1
BaseSession._run_fn(): 准备进入 C 层的运行库,Python 层到这里结束。在执行
TF_Run()之前,这里还有一个_extend_graph()的过程,初次执行时,C 部分的运行时会为 DirectSession 初始化一个 GraphExecutionState 结构,即前面所提的保存了环境中初始的图信息的 executor_state_ 。!!关键在这里!!#0
tf_session.TF_Run():这就是tensorflow/c/c_api.cc中 C 层运行时的入口函数了。
整理一下上面的部分,Python 层的 API 要做的只是根据输入数据和输出目标找到整个图中的所有依赖项(包括 Tensor 和 Op),然后把这些内容传入 C 层。
那么最后再把前面的整个运行过程整理一遍:
- 用 Python 层的接口构建出计算图
- 如果不定义新的 Graph 结构,则所有的 Op 都会放在默认图中
- 调用
Session.run(...),Python 层遍历计算图,整理出为了执行目标所需要提供的前置数据(Tensor)以及得到这些数据所需要执行的所有 Op 列表 - 首次运行
_extend_graph()时,为 C 层的 DirectSession 对象初始化 GraphExecutionState 结构,这里面保存了 C 层的完整计算图定义 - Python 层整理完的 feed_dice、fetch_list、target_list 通过
TF_Run()接口传入 C 层 - 接下里是
DirectSession::Run()中的内容,详细可见TensorFlow 拆包(一):Session.Run()篇,为当前需要执行的部分创建 Executor、线程池等等,完成整个计算图的执行
Output the C level Graph!!!
在环境变量中加上TF_CPP_MIN_VLOG_LEVEL等于 2 以上的级别时,TensorFlow 运行时会输出比较详细的运行 log 来。其中就包含了 C 层面的建图相关的信息,于是用了几个 awk 脚本把这部分内容抓出来了:
get_graph.sh
1 |
|
get_graph_filter.awk
第一步从 log 中抓出图部分的信息之后,用这个删掉其中的重复信息。
1 |
|
get_graph.awk
最后用这个脚本生成 GraphViz 的图。
1 |
|
稍微修正一下最终的输出图,我们就可以得到:
Simple DNN

Simple DNN Distributed

Simple CNN Distributed

为了比较好的视觉效果,上面输出来的图中或多或少被我删掉一点不重要的内容,有的在相同变量上也还没做整合。ApplyGradientDescent、ApplyAdam、Assign 这些有多出来的虚线我加的也不一定对,暂时先批判地看待上面这几张图吧。
C 层面的图结构比 Tensorboard 里面的 Python 层要稍微多点东西(比如跨设备的 send/recv 等),然后有的地方信息又不太全(比如上图中最右侧的部分,对照 Tensorboard 才知道是 adam 中两个值的平方,从 C 层面这些 node 本身的信息上体现不出来),不过大致上还是一致的。
Assign、Identity
关于图中的 Assign 和 Identity 这两个 op,可以见这里的一些介绍。
简单来说,Variable 持有一个内存中的 Tensor 实例,Assign 是对这块内存中的数据进行修改的操作。
Stack Overflow 上对 Identity 有个讨论,然而我感觉高票答案的 tf.control_dependencies() 的例子其实引的不好,根本说明不清楚问题。
从官方文档里面只能看出来是做了一个别名引用,下面做一个简单的测试:
1 | import tensorflow as tf |
得到的输出结果是:
1 | a: 0 |
这里 a_i 和 b_i 分别是对 a 和 b 的 tf.identity() 操作。
首次输出的 a 和 a_i 都是 a 的初始值 0,a_i 在这里就是对 a 的直接引用。
接下来,输出 b 之后,再次输出 a 和 a_i,得到的结果与前面相同,都是 a 执行加一之后的 1,可见tf.assign_add() 是直接对 a 所代表的 Tensor 数据本身进行的操作。
然后再测试 b_i,结果与前面运行 b 一致。
后续: