之前那篇整理到了 Ampere,内容已经挺长了,重新开一篇新的继续。
后面每一年再有新的更新也会继续补充到后面。
Ada Lovelace
Compute Capability: 8.9(RTX 40x、L40、L20、L4、L2)

SM 结构:
- 4 个 16384 x 32bit 寄存器
- 4 个 Warp Scheduler,4 个 Dispatch Unit(与 A100 一致)
- 64 个 FP32 Core(4 * 16)
- 64 个 FP32/INT32 共享 Core(4 * 16)
- 4 个 TensorCore(4 * 1)
- 16 个 LD/ST Unit(4 * 4)
- 4 个 SFU(4 * 1)
- 128 KB L1 Data Cache/Shared Memory
- 4 个 Texture Units
- 1 个 RT Core
每个 Process Block:
- 16384 x 32bit 寄存器
- 1 个 Warp Scheduler,1 个 Dispatch Unit(与 A100 一致)
- 16 个 FP32 Core
- 16 个 FP32/INT32 共享 Core
- 1 个 TensorCore
- 4 个 LD/ST Unit
- 1 个 SFU
相比 Ampere 主要的提升还是光追部分,计算方面通过 4nm 提升了能效比,更多的还要看下一代的大版本更新。
这里 TensorCore 和后面的 Hopper 一样是第四代架构,也支持了 FP8 这样的新数据类型。
Hopper
Compute Capability: 9.0
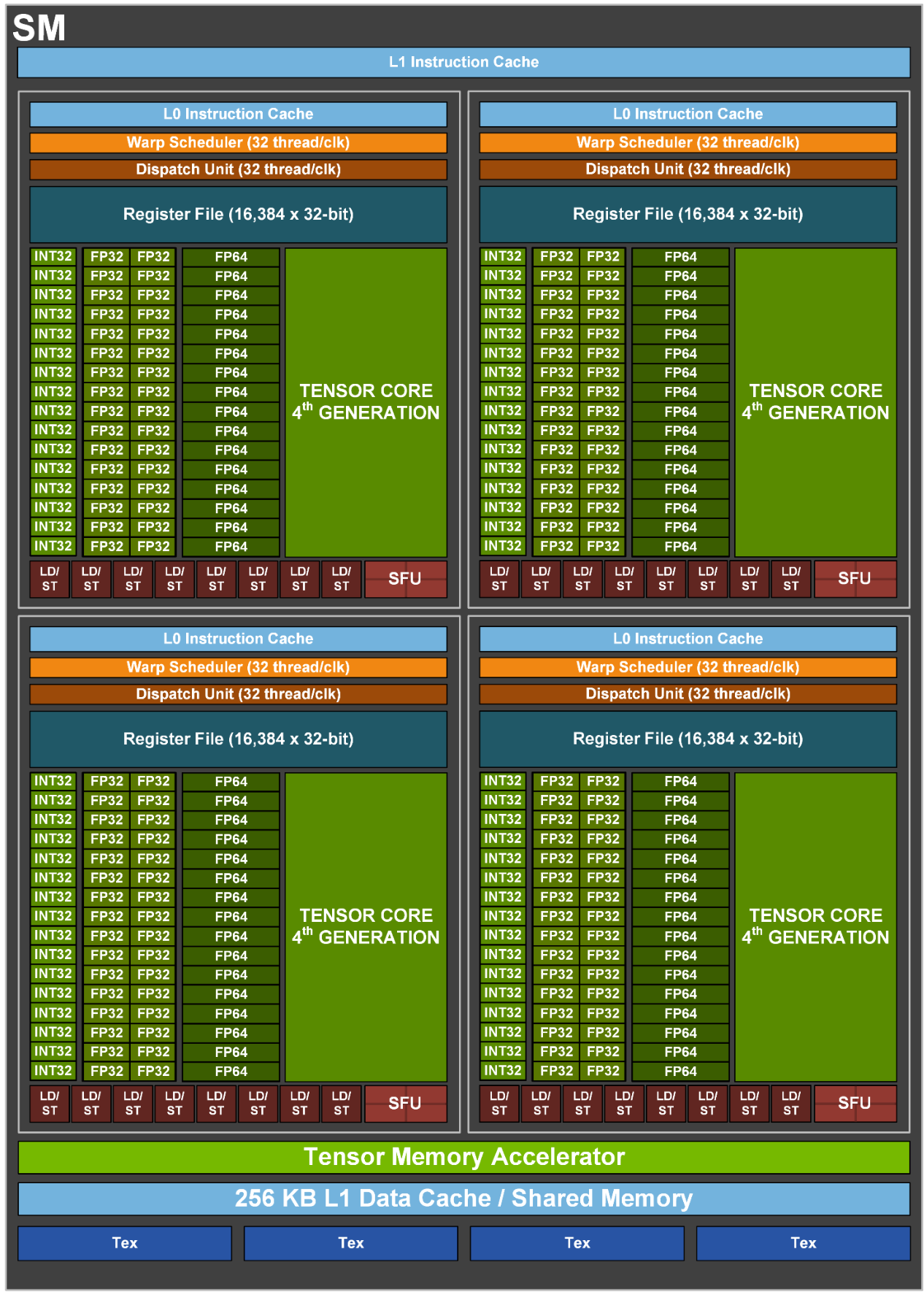
SM 结构:
- 4 个 Warp Scheduler,4 个 Dispatch Unit(与 A100 一致)
- 128 个 FP32 Core(4 * 32)(相比 A100 翻倍)
- 64 个 INT32 Core(4 * 16)(与 A100 一致)
- 64 个 FP64 Core(4 * 16)(相比 A100 翻倍)
- 4 个 TensorCore(4 * 1)
- 32 个 LD/ST Unit(4 * 8)(与 A100 一致)
- 16 个 SFU(4 * 4)(与 A100 一致)
- 相比 A100 增加了一个 Tensor Memory Accelerator
每个 Process Block:
- 16384 x 32bit 寄存器
- 1 个 Warp Scheduler,1 个 Dispatch Unit(与 A100 一致)
- 32 个 FP32 Core(相比 A100 翻倍)
- 16 个 INT32 Core(与 A100 一致)
- 16 个 FP64 Core(相比 A100 翻倍)
- 1 个 TensorCore
- 8 个 LD/ST Unit(与 A100 一致)
- 4 个 SFU(与 A100 一致)
比较显著的改动是 FP32/FP64 Core 的数量翻倍了,加上 H100 主频相比 A100 更高,以及 SM 数量的增加,体现到最终 H100 单卡可以达到相比 A100 做到 3 倍的浮点性能。
这代 TensorCore 的单 cycle 吞吐相比 Ampere 再翻了一倍,反映到单卡上也是 3 倍多 A100 的同类型运算性能。
更进一步能让数据上更好看的是 TensorCore 增加了 FP8 数据类型支持(可选 4 位指数 + 3 位底数或者 5 位指数 + 2 位底数),相比自己的 FP16 是两倍性能,与 A100 的 FP16 比就是 6 倍性能了。
软件层面加了个 Transformer Engine,专为 transformer 结构做的优化,估计也是通过加速库 api 的形式提供。
SM 里面多出来的这个 TMA 相当于是把之前针对 TensorCore 上做的一些软件层面的 memory 搬运优化固化到了硬件上,进一步优化了 TensorCore 的数据访存效率。
感觉 TensorCore 上真是能搞的都搞了:计算提升主要靠工艺堆料和新的数据类型,Sparse 和这次这个 TMA 都是针对访存的提升。
有点好奇 TensorCore 现在在 GPU 上的芯片面积能占到多少了?
感觉会不会已经像是一小部分通用计算部件挂一个巨大 NPU 的结构了,与一众新兴 AI 芯片公司的设计殊途同归了属于是。
看 NV 明年还能再往 TensorCore 上整点啥。
DPX Instruction
编程模型方面,Hopper 新增了一种 DPX 指令,主要用于动态规划算法的优化。白皮书中的举例是生物 DNA 序列匹配上的 Smith-Waterman 算法(算不算蹭最近几年因为新冠火起来的生物信息方面研究的热点,AI 上搞得差不多了,NV 继续往其他有可能突破的方向上发力)。
直接看到这个我还真想象不到动态规划和 GPU 是怎么能联系在一起,这里也没有给指令的 api 和更多实现细节。
Blackwell
Compute Capability: 10.0(B200、B100),10.x
白皮书还没出 … 待续