一晃又就快 1 年过去了。
1 年间感觉世界发生了很多变化,技术方面,感觉我们这边是每个月都在 rush 新东西。
前段时间 TESLA 说他们要比之前说的纯视觉方案要走的更加极致了,连近距离的毫米波雷达都要取消了。惊叹于他们对自己技术实力的自信(和他们的胆子是真的大啊)的时候,也确实挺让人好奇这两年间 TESLA 的 FSD 有了什么样的改进。
Source
YouTube 的原始直播资源在:这里。
同样,今年 B 站也是有不少人搬运的,顺便也贴一个在这里:
Join us to build the future of AI → https://www.tesla.com/ai
0:00:00 - Pre-show
0:13:56 - Tesla Bot Demo
0:29:15 - Tesla Bot Hardware | Hardware Architecture
0:34:22 - Tesla Bot Hardware | Hardware Simulation
0:39:40 - Tesla Bot Hardware | Actuators
0:45:12 - Tesla Bot Hardware | Hands
0:47:24 - Tesla Bot Software | Autonomy Overview
0:49:55 - Tesla Bot Software | Locomotion Planning
0:52:20 - Tesla Bot Software | Motion Control and State Estimation
0:55:00 - Tesla Bot Software | Manipulation
0:56:44 - Tesla Bot Software | What’s Next?
0:58:00 - FSD Intro
1:04:32 - FSD | Planning
1:12:11 - FSD | Occupancy Network
1:19:17 - FSD | Training Infra
1:25:48 - FSD | Lanes and Objects
1:34:22 - FSD | AI Compiler & Inference
1:40:34 - FSD | Auto Labeling
1:47:45 - FSD | Simulation
1:53:33 - FSD | Data Engine
1:56:50 - Dojo Intro
2:02:30 - Dojo Hardware
2:13:47 - Dojo Software
2:26:25 - Q&A
Let’s go
去年 Tesla Bot 只是相当于结尾菜单的感觉,今年的 AI Day 已经是把前半部分的大头都给了它。(TESLA 是真想把这玩意搞出来呀…)
我们还是跳过继续关注 FSD 部分吧。
FSD @ 0:58:00
开场是个比较经典的无保护左转场景的例子,这是一个没有单独做左转转向红绿灯的十字路口,对面有车辆、行人过马路,对侧车道也不断有车辆从右侧向左侧驶过:

假设目前感知得到的场景中的对象有 20 个,他们相互之间可能存在超过 100 中相对交互组合,考虑对场景中所有对象做多智能体联合轨迹规划可能会出现组合爆炸的情况。而往往在这种场景中,其他对象都是动态的,留给 planning 的时间是很短,多迟疑一会,可能之前可行的行动方案就被错过了。
FSD 采用了一套 Interaction Search 的框架去解决这个规划问题:
- 首先从环境感知结果开始,我们需要得到场景中 Lanes、Occupancy、Moving Objects 的所有信息;
- 根据感知结果,预构建出本次行动的候选目标,应该说的是从车道线以及一些非结构化的空间区域中找到可行驶的路线?看着比较像是构建一个最初的搜索空间;
- 运用一些轨迹优化方法,找到其中较优的 seed 轨迹;
- 把移动目标放进去,找到轨迹与场景中这些行动目标的关键交互点,例如有行人过马路,则可能选择加速在行人之前先过去,或者多等一会等到行人过完再过去这两种策略;
- 下一步再放入更多的目标,例如有右侧车辆经过,是选择在它之前插入,还是等待它过去之后再并道进入;
- 重复上一步的做法,继续加入更多的目标约束,最终找到可行的最优解。
对于上述步骤,每次放入一个新的移动对象所需要的开销是比较大的,尤其是当约束越来越多,传统轨迹优化的方法所需要的时间复杂度也会继续上升。FSD 的解决方案是用一个轻量化的 Queryable 的神经网络来替代传统优化器,可能思路比较类似 BEV 中用 transformer 对空间坐标转换的 query 思路。 - 最后加入碰撞检测、舒适度、判断哪种行为更像人(老司机化)等等评分来最终选择一条决策方案用。
Occupancy Network @ 1:12:11
上面的决策过程相比去年的版本已经出现了一个新的概念:Occupancy。

从演示图上,我们可以发现这个图上的概念其实看着都非常像雷达点云图了,TESLA 的思路有点像是用 8 个摄像头的图像结果中直接得到类似全向雷达的扫描效果(个人想法)了。
Occupancy network 直接从视频输入中得到一个反映了每个位置是否有物体占用的向量空间,也因为有视频时序的关系,对于被遮挡的位置也可以预测是否存在障碍物等等。同时,输出结果中也会包含物体类别的语义信息(直接也做了物体识别了?)。
跑一次 10 ms 左右,相当于最佳情况下能跑到 100 帧了。
接下来,终于可以看到整个网络的全貌了:
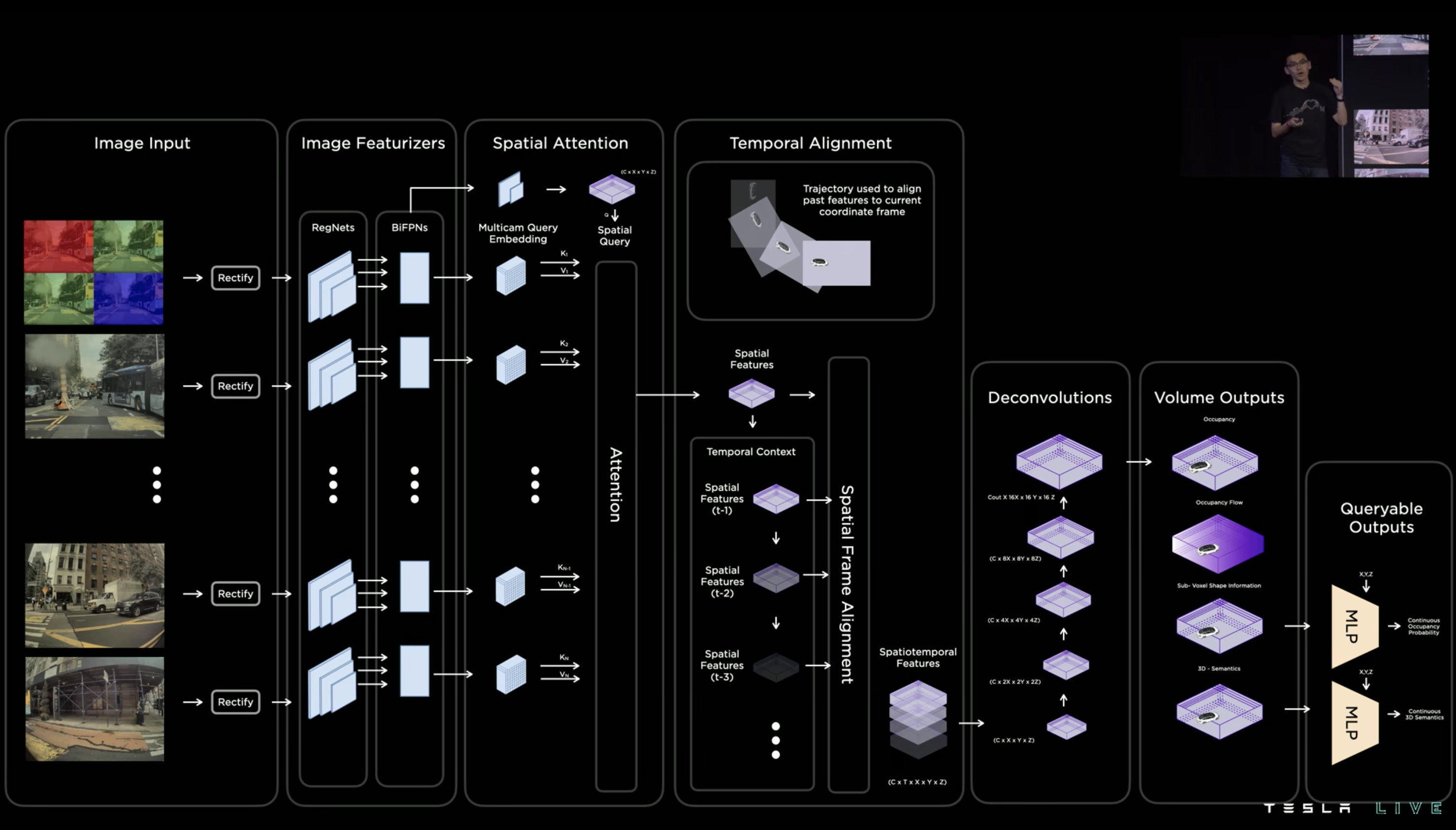
对比去年的网络结构,可以看到网络的主体部分基本上是差不多的。
去年我看的时候有个未解之谜是输入图片的 channel 是多少终于破案了!小哥今年终于提到说 12bit 的原始输入图像是 4 channel,相比常规处理后的 3 channel RGB 图像可以多一些信息,并且用原始图像的好处是不需要 ISP 了,少了这里的一个步骤之后整个流程可以更快一些。
原始图像去畸变,过 RegNets 和 BiFPNs,再到 Spatial Attention 和时序处理,这里这些都是跟去年网络中的思路完全一致。
后面的部分是今年 Occupancy Network 的改变,通过多次反卷积,把时序模块得到的 [C, T, X, Y, Z] 结果通过一系列反卷积展开成 [C, 16X, 16Y, 16Z] 的最终空间信息,即前面所说的 Occupancy 向量空间了。
为了得到更高的分辨率,最终还有两个 MLP 用于从这个向量空间中把需要的信息提取出来。输入 [x, y, z] 的空间坐标,分别可以得到每个位置的占用概率以及分类语义。可以看做是通过反卷积和 MLP 的 query 实现了去年网络中不同 task 的 head 识别的任务,网络的复杂度被大大简化了。
下面也给了个例子:

场景中右侧是一辆前后两节弯折的大型巴士,模型一开始标记是红色物体的前方有另外一个蓝色物体,随着车辆继续前行,两个物体被标记成了相同颜色,即网络识别出来了这是属于同一辆完整的车,并且巴士弯折的部分也可以在 occupancy 空间中很精确地标识出来。(想了下,如果用去年的网络处理这种场景可能确实比较麻烦,大概率还是会把这俩识别成两个不同的物体框了)
确实让人忍不住想要称赞 666 了。
本来以为这部分要结束了,没想到上面这张图的更完整版是这样的:
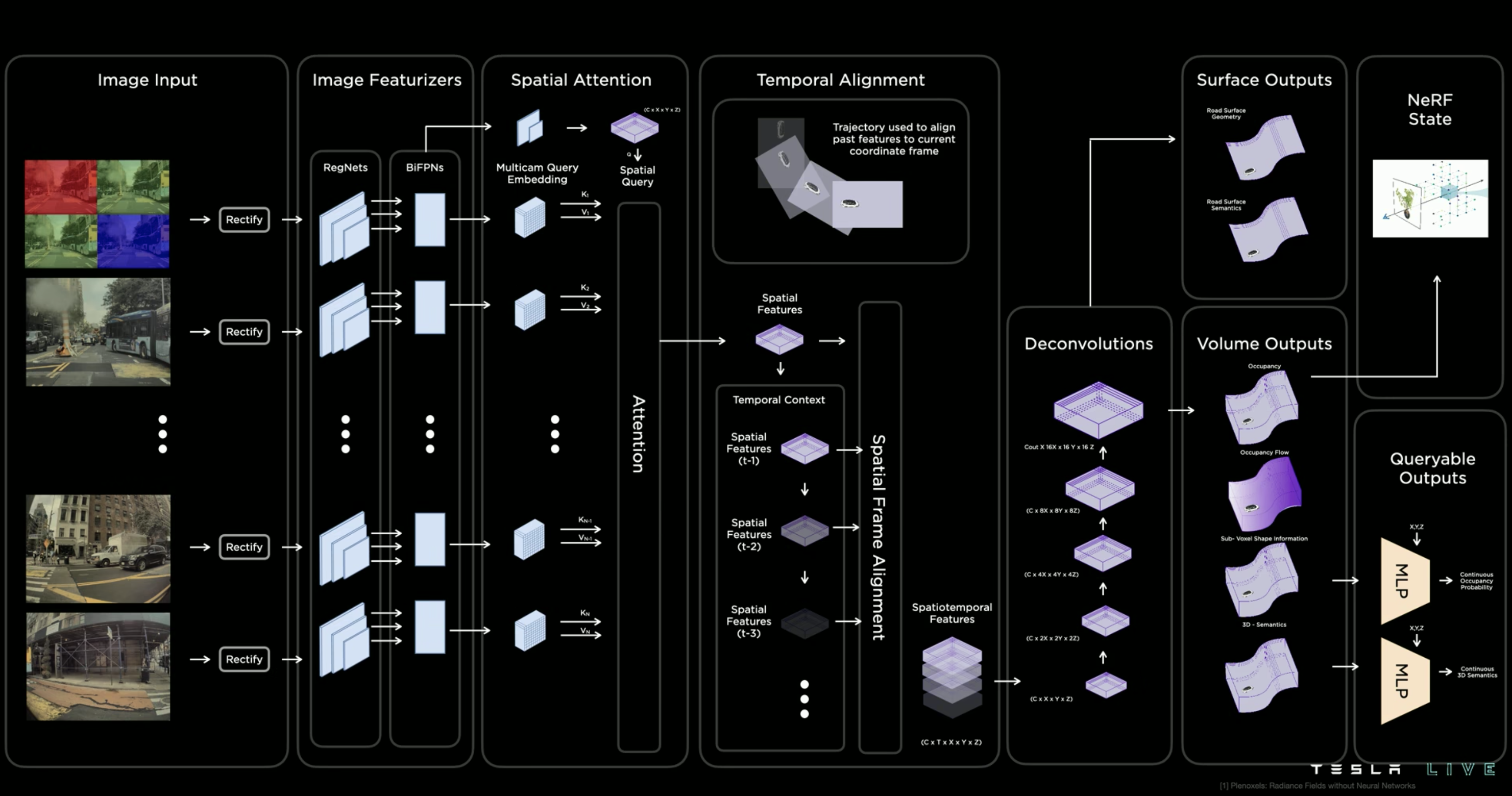
Occupancy Network 不仅是能得到物体的空间占用以及类别语义,更重要的是把地面的语义也同样带上了(事实上前面的 Volume Output 空间本身是包含地面的),这个向量空间是完整的,连地面的上坡下坡起伏的信息都能精确地识别出来,这个对于后续自动驾驶的决策而言也有非常大的实用价值。也不用再在 head 中加一个 ground 的目标或者专门用一个后处理阶段来搞这些东西了。
What’s more! NeRF States! 惊了 … Occupancy Network 的输出信息甚至可以应用到光场识别上。后续可能能进一步用作 3D 重建等 CV 任务。
Training Infra @ 1:19:17
这一节主要是介绍针对视频训练部分做的优化,做的工作也是相当硬核,虽然看起来都是比较零碎的,但是也真的可以称得上是对全链路上的每个步骤都做完充足的优化了。
都是一些工程部署上的细节,比如优化文件存储,减少 copy,甚至设置环境变量等等,这里不展开了,贴一张总结图:

另外想吐槽的一个点是,其实这里面大部分的零碎优化点通常每个优化组都会做,但是只能算是一些配置调整,单独写出来作为工作是不够 solid 的。
Lanes and Objects @ 1:25:48
接下来细节展开介绍车道线和目标识别。
回顾一下,最早的传统做法是把车道识别看做一个实时的图像分割任务,直接从输入图片的 2D 空间中识别出不同的车道线信息,然后在后融合中把这些信息带上。换到 BEV 的方案后其实本质上对于 lane feature 的获取也还是从 2D 图片中来的,只是相当于把融合位置提前了。
这样做的缺陷在于对于一些车道线非常复杂的十字路口或者根本没有车道线的情况下,这种 2D 识别的方案效果会非常不好,几乎没办法得到一个可用的结果。
以下是 TESLA 目前的 lane 模型方案:
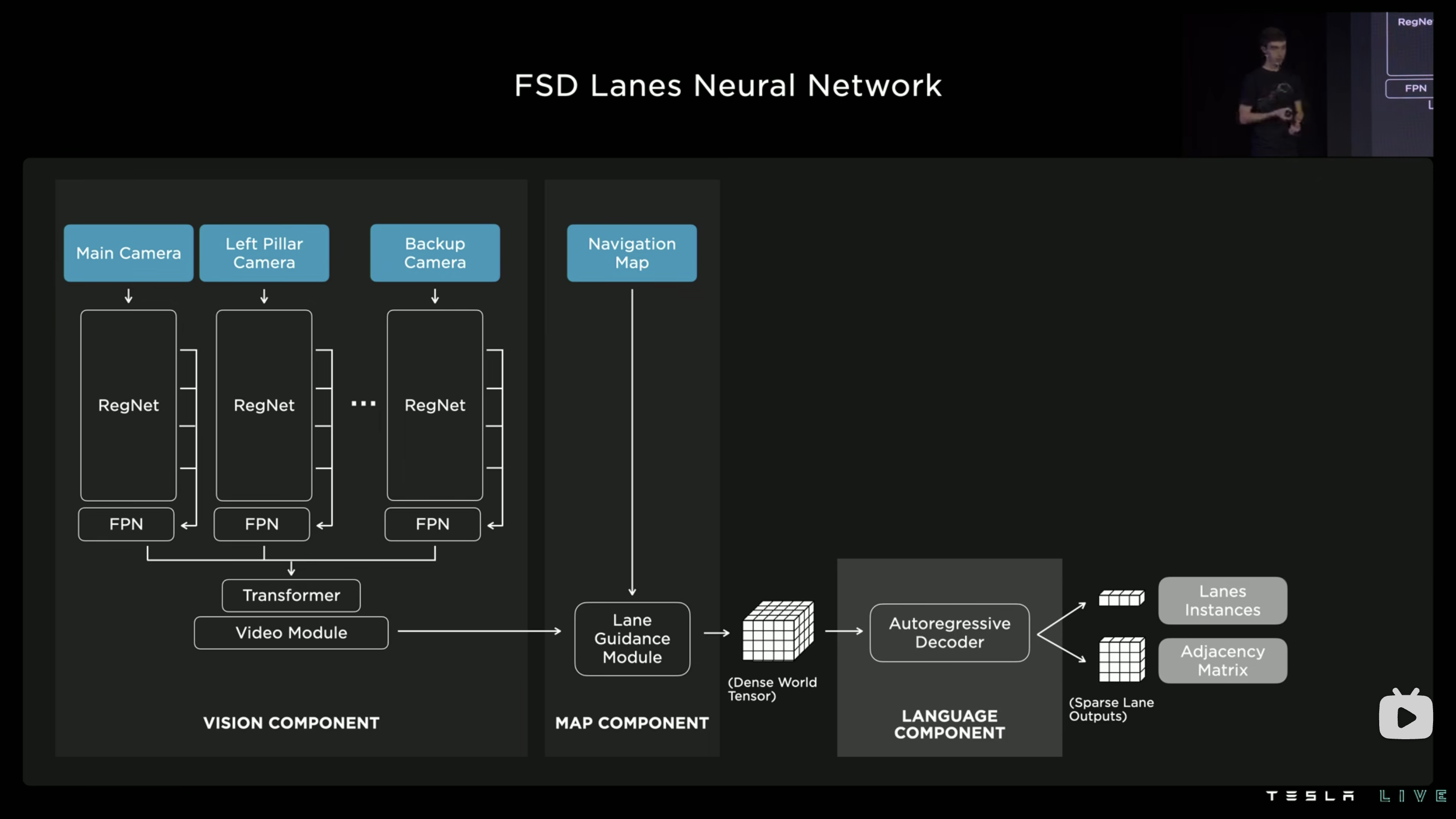
左侧是 Occupancy Network 的视觉感知输出,加上一些地图信息之后得到了一组包含更丰富的 lane 信息的识别空间。这里的地图信息可以不需要是高精地度,就是常规的导航地图提供的那一点点信息就足以。
然后是 transformer again!
用常规的方式去标记出复杂场景中的每一条可行的车道线还是过于复杂,因此 FSD 最终采用了一种看起来可能更复杂,但是对于这个问题来说其实是一种很好的抽象的“语言学”的方式去解决。他们定义了一套词法语言来描述每一条车道线的生成规则(灵感来源可能是人类例如说问路的时候可能会有的对路径点的描述方式?),然后用一个 decoder 从上一步的 dense world tensor 中把这些信息解出来。
每条车道线上的每一个点都可以视作是 decoder 句子中的一个“词”,正如一条车道线由线上的多个点构成,decoder 工作中处理的一个“句子”表征了一条车道线。
这里的“车道线”甚至其实已经不是识别出来的了,可以相当于是预测出来的可以让车辆开的路线,即使对于实际没有车道线的场景,在模型的输出空间中也能够得到对应的结果。
AI Compiler & Inference @ 1:34:22
又到了我最想看的部分,然而发现内容还是跟去年一样少,对于这个部分 TESLA 藏得还是太深了。
出大问题,这小哥的英语是真的难听懂啊…
针对前面提到的 Lane network 的 attention 部分,他们做了很多 op 上的优化以及针对 int8 准确率的优化。
而在全车部署框架的层面,有用的信息其实只有接下来两张图:
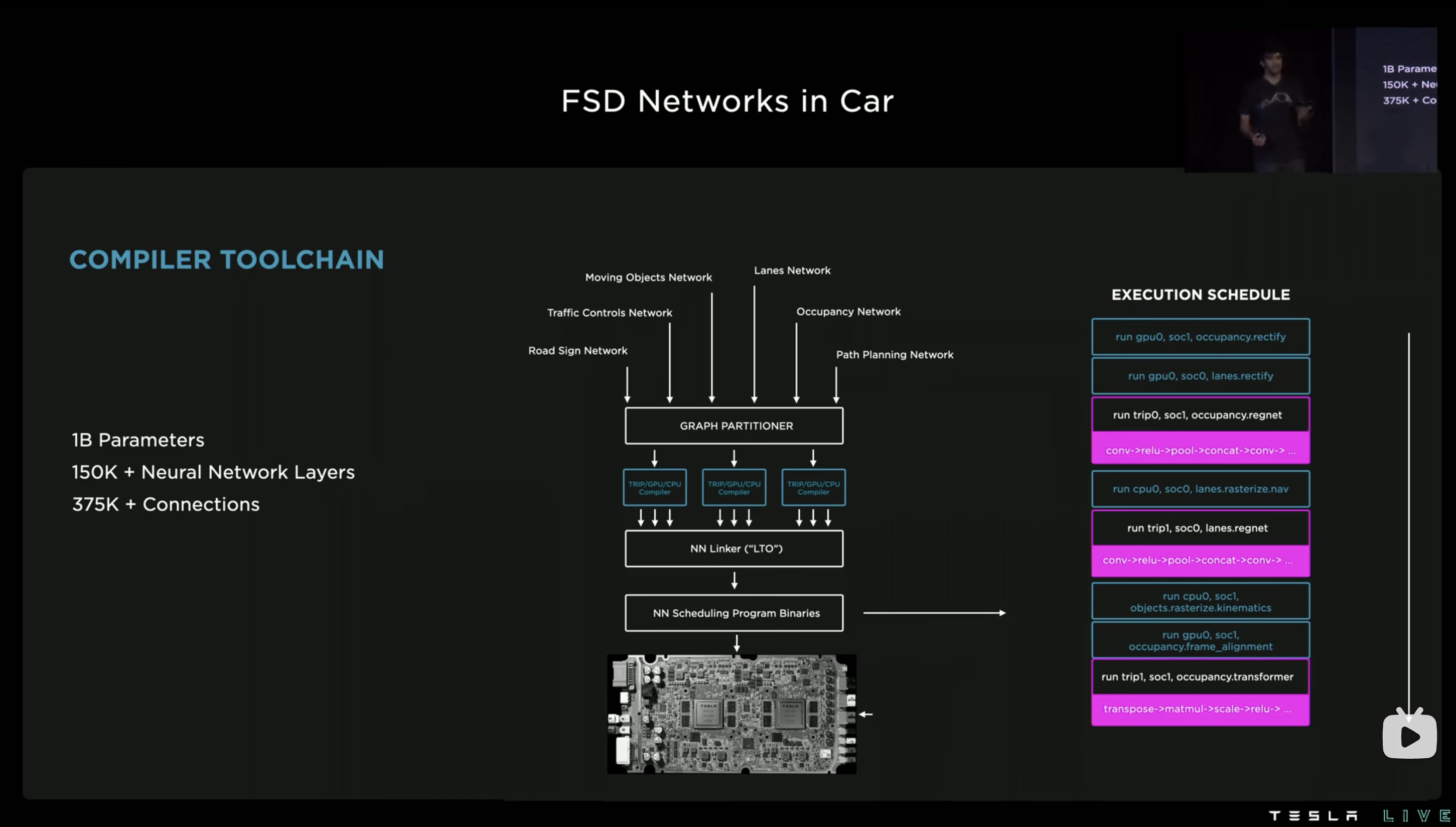
从这里基本上能比较确定地看出来是编译期把图都切分好,然后在车上做确定性调度了。编译期 graph partitioner 需要知道的是每个网络中的每个部分的依赖关系、运行时间等等信息。然后做全局的图切分和放置排布,NN linker 把切分好的所有子图都打包在一起,最终车上根据前面定制好的 schdule 去混合跑所有模型即可。
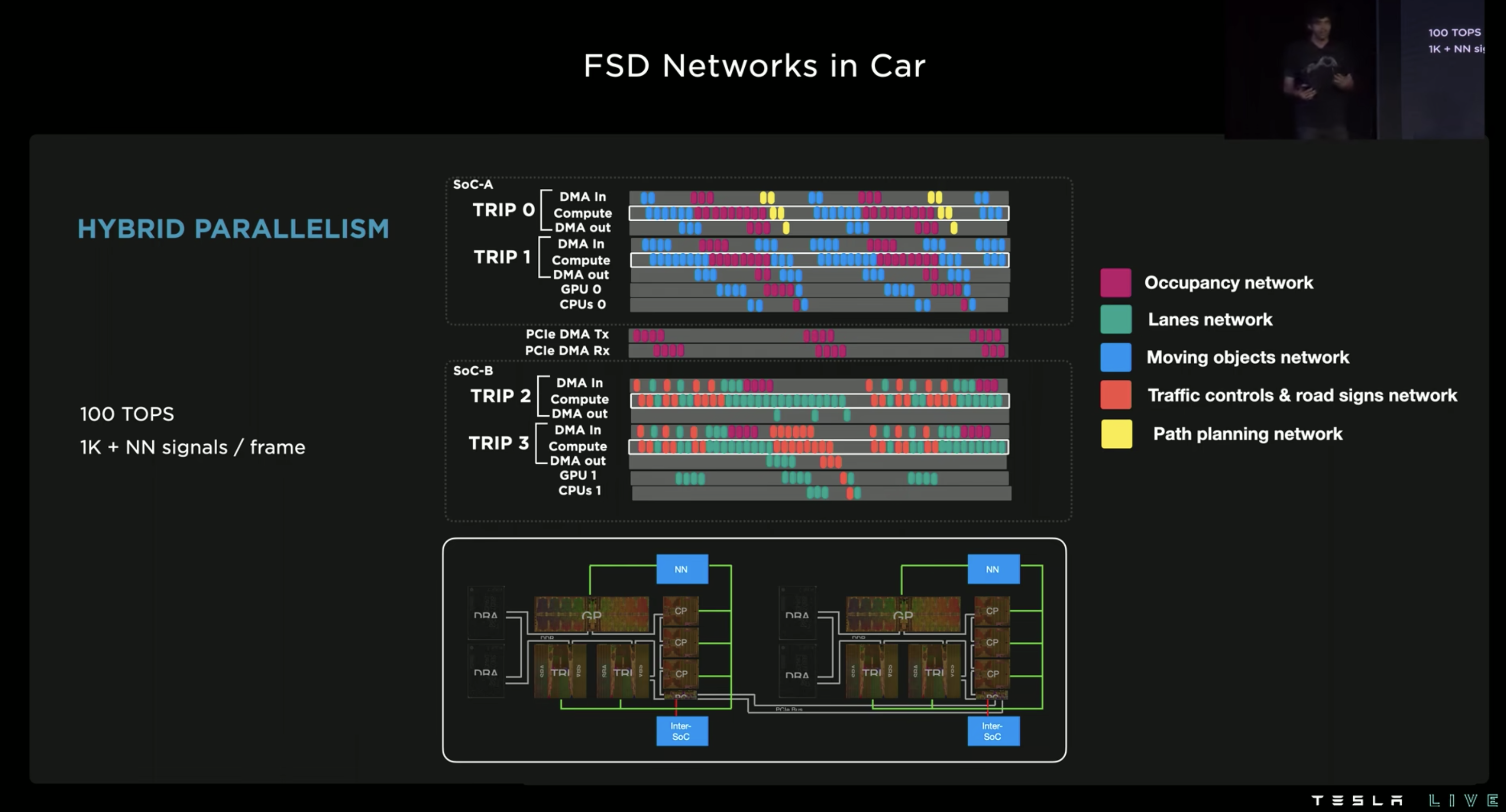
Graph partitioner 对于每个模型在什么时候用到了片上的什么资源是确切知道的,因此就能通过对模型中每个运行部分的排布让片上的硬件资源得到全局的高效利用。
图上的 partitioner 排布逻辑也比较好猜,就是尽可能地想办法把 FSD chip 上的两个 NPU 用满。
(话说对于 FSD chip 好像好多年都没见升级了?当然我猜测不升级的原因有可能是目前的硬件出货量已经太大了,即使升级了新硬件,老的一样要继续维护升级,对于 TESLA 来说维护这样很多代可能不一定划得来,成本也会增加很多)
后面展示网络可视化的部分有点搞笑了…
Dojo @ 1:56:50
后面标注和数据处理部分我兴趣不大,跳过去直接看 Dojo 超算部分的介绍。
去年的 AI Day 上主要介绍了 Dojo 的逻辑架构,有很多工程上的实现细节是没有披露的,今年直接开场就抛出来了,以证明他们不止是理论设计可行,实际做出来之后也真的能用起来。
Dojo 自研了 VRM(Voltage Regulator Module)来解决高度集成之后芯片模块的供电和散热问题,迭代了 14 个版本之后才达到了他们预期的 CTE 要求。
然后设计了一种数据传输专用的处理器(Dojo Interface Processors)来负责板间互联和高速数据传输,给 Tile 上的 640GB 内存提供超过 18TB 每秒的运算带宽,和超过 1TB 每秒的网络交换带宽。
最终交付使用的 Dojo 会是下面这个样子(预期 2023Q1):
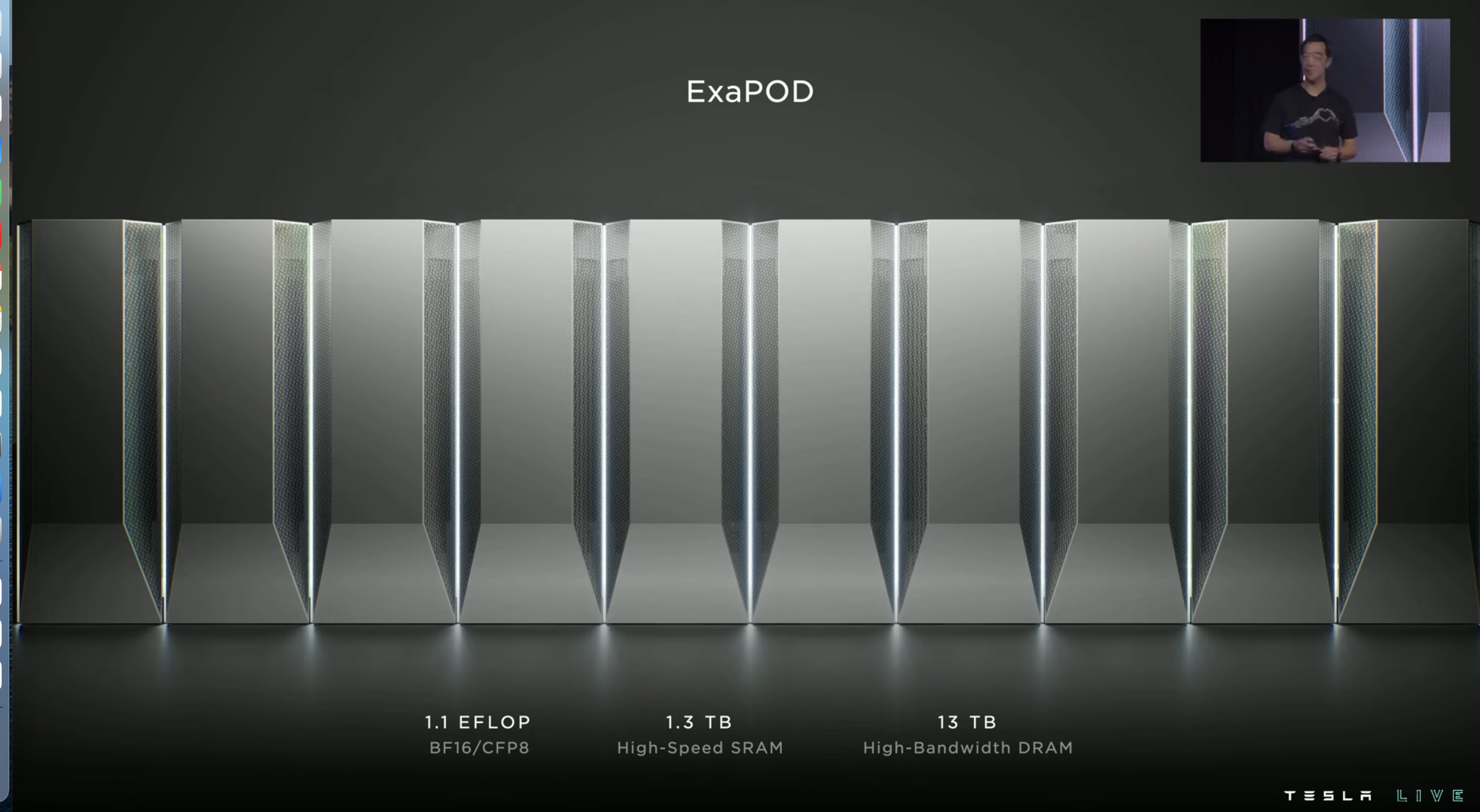
性能参数方面跟去年公布的应该差不多。
Dojo Software @ 2:13:47
软件部分主要是基于 PyTorch 开发了 Dojo 的插件,也是通过 AI 编译器来 offload 到 Dojo 上。
分布式方面的优化也是比较常规的,这里给了个基于 2D-Mesh 做 AllReduce 的例子:

最后的性能展示部分主要体现出硬件和 compiler 两方面的提升带来的加速效果:
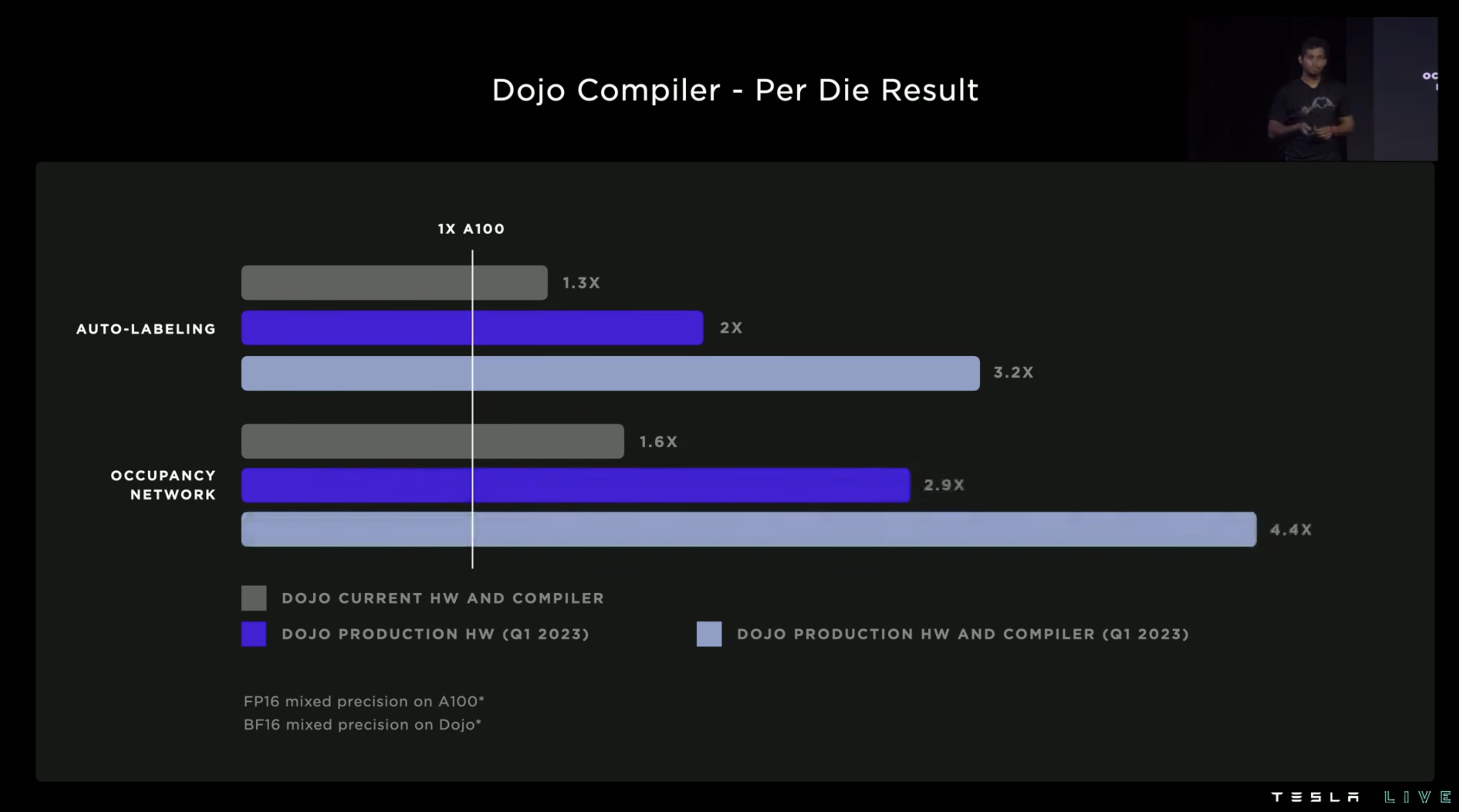
有了高度集成的 Dojo 之后,之前 6 个大 GPU 机柜可以直接用一个 75mm 高的 tile 直接代替了。真是令人惊叹…
About NIO
照例跟去年一样稍微更新下我们这边的进展。(2021 回顾里面重新更新进展的时间其实已经是到 2022 年中了,这里更新的进展是 2023 年初时候的状态)
首先是 BEV 终于已经完成上车了,而且看样子效果非常不错。NT2 平台的车主这时候应该已经都用上了 NOP+ 了吧,B 站可以找到的很多测评视频中都给出了相当好的评价。至于 NAD,我也不太清楚确切的计划,不过大概率今年是也会上的(至少测试肯定会放出来了)。
我们基于 tvm 做的自研引擎已经在车上跑了 1 年多啦!可以公开的信息是在 Orin 这块 NV 的板子上我们已经全面干掉了 TRT,从量化精度到性能等各方面全面超越。23 年 tvm conference 上分享完了之后如果有空我也会另外写篇帖子详细展开一下这段我们都做了啥。