终于要开始往博客里面写点跟我现在去的新行业相关的东西了。
回顾一下今年特斯拉的 AI day。
Source
直播的原始视频发在了 YouTube 上,这里。
发现 B 站刚好有人把完整的 3 小时都搬过来了,就拿过来贴在这里:
顺便 YouTube 评论区置顶的这条贴了视频的几个关键时间点目录:
Join us to build the future of AI → https://www.tesla.com/ai
0:00 - Pre-event
46:54 - AI Day Begins
48:44 - Tesla Vision
1:13:12 - Planning and Control
1:24:35 - Manual Labeling
1:28:11 - Auto Labeling
1:35:15 - Simulation
1:42:10 - Hardware Integration
1:45:40 - Dojo
2:05:14 - Tesla Bot
2:12:59 - Q&A
Let’s go
正片差不多 38 分钟左右开始,一开始上来就放了一段自动驾驶片段。应该是辆 Model 3 或者 Y,可以在中间的中控上看到实时的环境识别和规划路径的可视化效果。左边红色的线是道路边缘,白色和橙色的应该是识别出来的车道线,绿色的是规划出来的目标路径。不得不说视频里面的效果还是很流畅的,中间也经过了一些复杂的交汇车和等待行人的十字路口等等场景。
46 分钟马斯克上来招了一波人 …
Vision @ 48:44
之前演示的视频就是目前特斯拉在车上采用的纯视觉方案,8 个摄像头通过神经网络处理后构建出一个 3 维的向量空间,然后所有的识别和规划都在这个空间中完成。
他们用了 ResNet 作为 Backbone,输入是摄像头采集过来的 1280 * 960 的 12 位原始图像。这里用的直接是摄像头的 RAW 数据,可以减少一些视觉处理算法的预处理等等,理论上能最大限度地保留信息?1280 * 960 这个尺寸不知道是不是他们摄像头的原始尺寸,感觉分辨率偏低,不过输入尺寸太大了确实也影响推理性能。
接下来过一个 BiFPN 去对 Backbone 中的多层数据做一个特征融合。融合后的特征最后再被拿过来做具体的识别和分类。视频里有一页给了 cls 和 reg 的输出尺寸分别是 640 * 480 * 1 和 640 * 480 * 4,猜测 1 大概是描述某个像素点是不是有物体,如果有物体的话输出的 4 则是物体的分类属性。
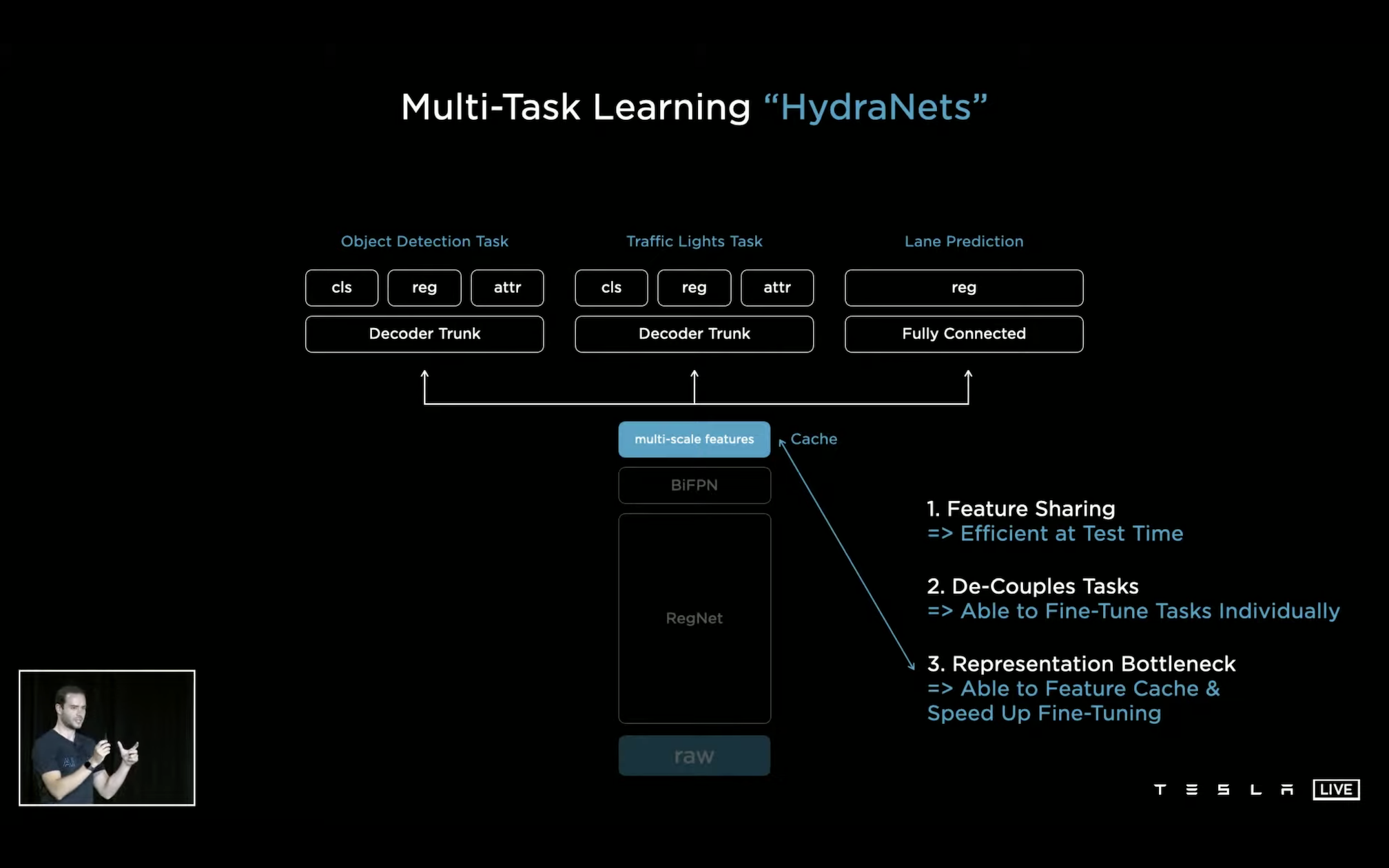
这里有个重要的点是前面到 BiFPN 为止的数据和特征都是被接下来不同的分类任务共享的,后面接上不同的检测头就可以从原始的图片数据里面分别检测出物体(可以是车、人、其他障碍物等等)、车道线、红绿灯等等。每个检测头都是独立的,比如这里给出的细节是 lane 只用了个简单的全连接,其他的目标识别则是用了更复杂一些的网络。这种 one model + multi task heads 的方式:
- 所有任务共享完整的同一组视觉 feature,实际 inference 的时候就很高效了;
- 后面用不同的检测头再去做具体类别对象的识别,可以针对每一个不同的对象独立做检测头的 fine tune;
- 训练做 fine tune 的时候也可以从下面 cache 住的 feature 开始。
后面出结果的时候也是一帧图片进去,跑完整个网络直接就能同时出来所有不同类型对象的检测结果。
单摄像头拍到的视频帧会少了个很重要的深度信息,因此每个摄像头得到的结果是没办法简单地直接放在一起用的,且单独一个摄像头检测出来的结果也很容易会产生偏差,也会有一个对象可能同时出现在多个摄像头的画面里面的情况。所以接下来是一个叫 occupancy tracker 的部分,需要把所有摄像头识别出来的车道线、物体等等根据它们的空间关系融合到一起去(就是前面视频里面提到的 3 维向量空间)。
“It’s very easily said much more difficult to actually achieve.” Emm … 这句话好像在哪里听过的样子,不过确实这个想想就很麻烦。
模型先放到后面说,首先第一个技术点是不同车上摄像头的位置会有偏差,每个摄像头拍到的画面也都会有一定的畸变,每个画面到最后提取完 feature 再去做调整就不太好操作了,效果可能也不好。所以他们直接采用的是前融合的方式,在摄像头的 raw 数据后面加了一个 Rectify 层,在获取到图片数据的时候就用上相机的标定数据等等信息,对图像做去畸变矫正以及变换到一个标准的 virtual common camera 的视角上去。
这样是不是不同车上的数据在最后训练和识别的时候都能够完全统一到一起去了?666

然后回到这个融合模型上,说实话细节部分我还没有完全理解(惭愧…),他们用了个 transformer 来做多目 image 到 BEV(Birds’s-Eye-View?) 空间的转换和 fusion。不同摄像头图片上提取到的 feature 通过 context summary 和 positional encoder 合到一个网络里面去,得到这个 transformer 里面的 Q。每一张图片和它们的 feature 分别变成了 K 和 V。
一开始我想了好久也没理解他这里说的 Query 和 Key/Value 是啥,后来一看这不就是 transformer 结构里面的 QKV 吗,希望应该不是我理解错了。
如果 do all the engineering correctly(听起来确实挺麻烦),Transformer 的最终结果就可以拿来做融合后的最后识别了。输出的 multi-camera features 的尺寸是 20 * 80 * 256。
后面的演示结果里面 Multi-Cam 前融合得到的车道线和物体检测结果都确实要比做后融合的效果要清晰和稳定的多。
下一步是对所有视频帧的数据进行时序融合,只有这样才能进一步确定下来每个检测对象的速度、方向、被遮挡等等的信息。
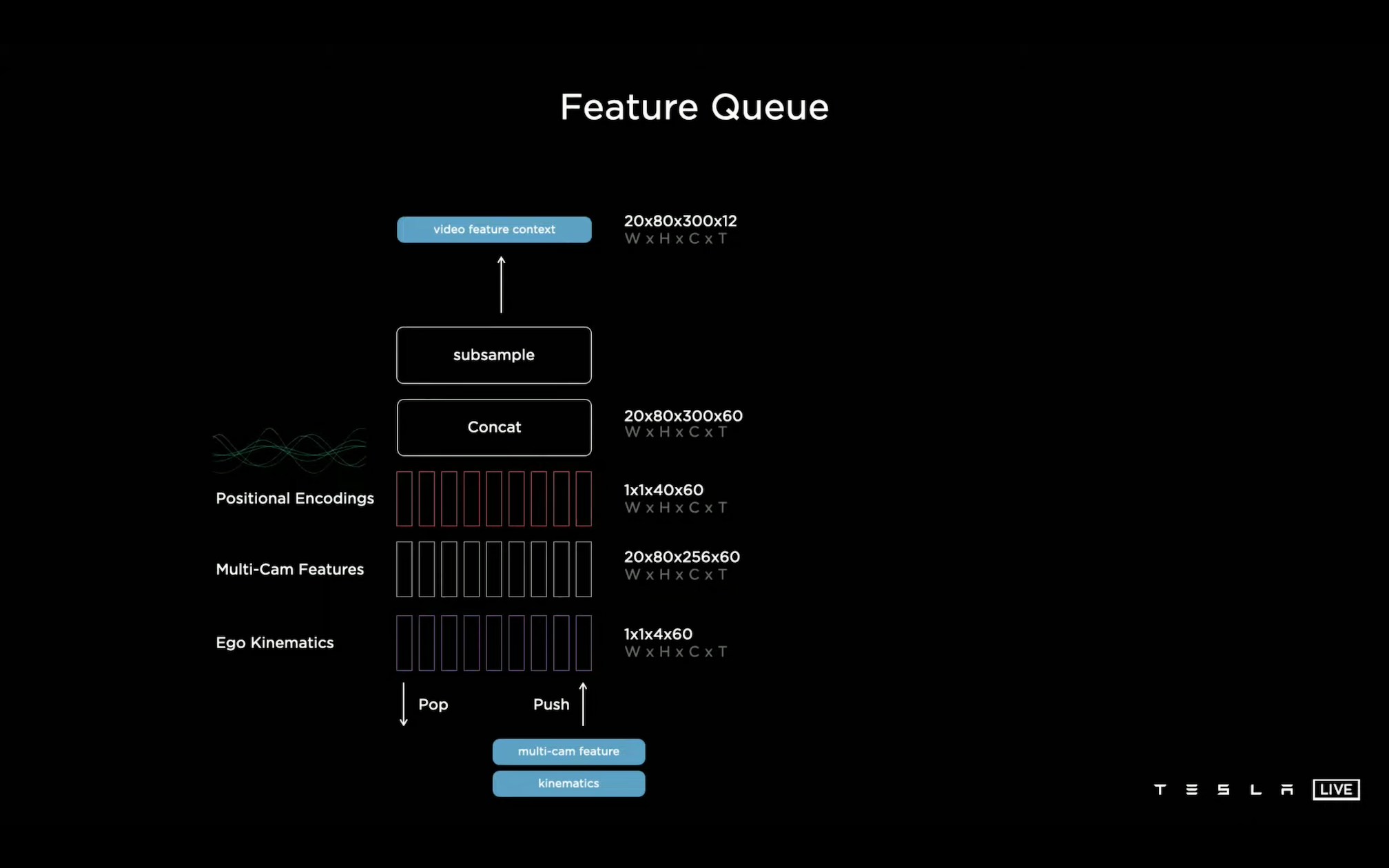
每一帧的 feature(20 * 80 * 256 * 60)加上 IMU 中得到的车本身的姿态信息(1 * 1 * 4 * 60)再加上位置编码(1 * 1 * 40 * 60)下采样后得到的 video feature(20 * 80 * 300 * 12)会存放到一个 feature 队列中。Feature 队列中数据的出入队需要同时基于时间和距离信息决定,时间很好理解,太久之前的信息就没有用了。距离信息这里举了个例子是如果在一个路口之前提前看到了车道上对这个路口的车道标识,那后面在路口等待红绿灯时之前的车道标识信息也是可以用上的。
在视频信息融合上他们尝试过 3D Conv、transformer、RNN 等等,最后选了个空间 LSTM。车在每一个时间点上的感知能力是有限的,如果把整个感知空间定义成一个很大的二维平面(W * H * C),其实每一次只需要更新车周围的平面位置的数据就好了,车周围平面的 feature 尺寸是 20 * 80 * 256,用 IMU 参数修正之后对应到大二维平面上,每个点都是一个 RNN(???)。(RNN 的详细细节也没完全看懂,后面再细看…)
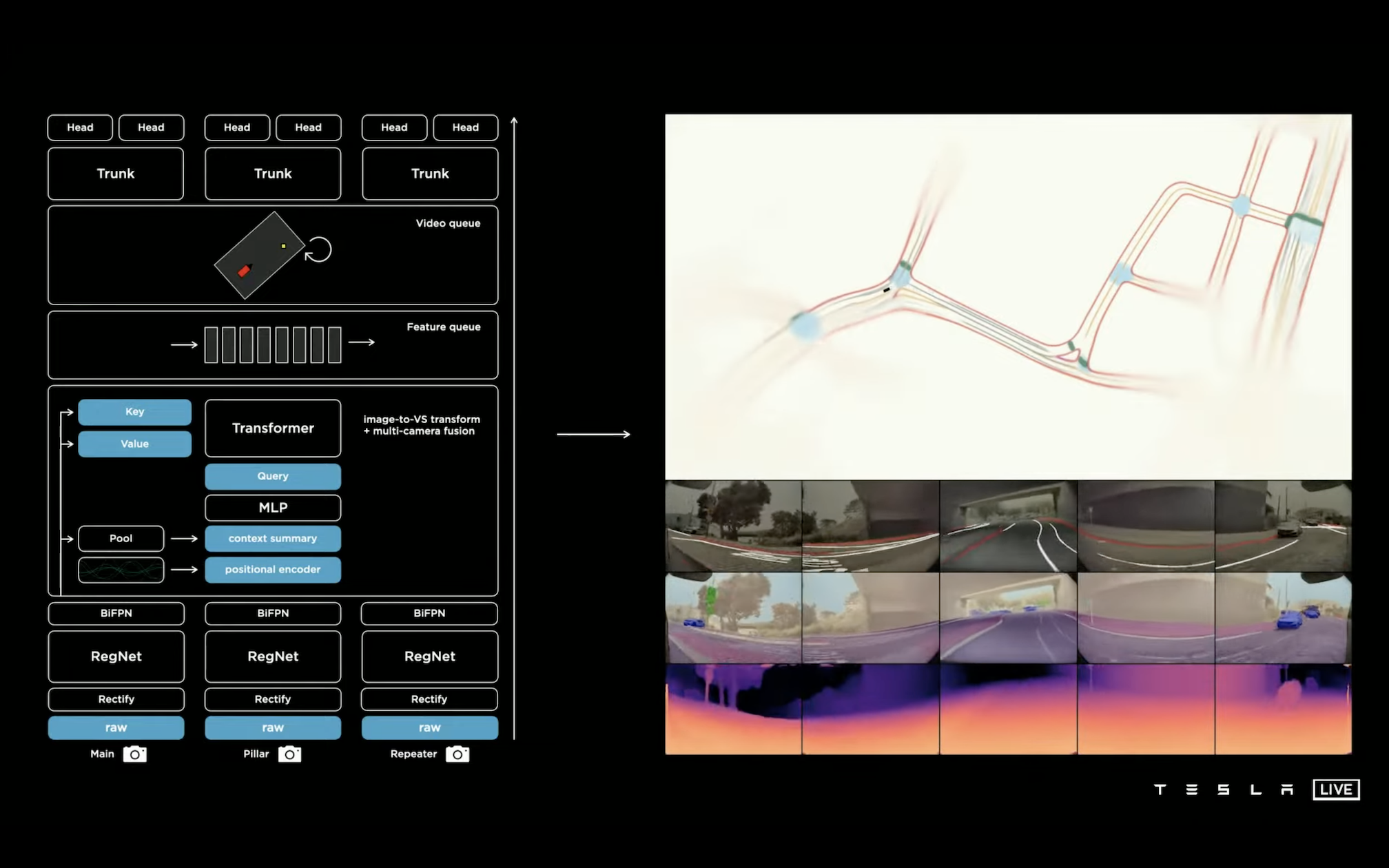
回顾一下整个网络的结构(假设是所有都放在一个 batch 里面的实现,大胆推测一下每个部分的输入输出):
- 8 个 12bit 摄像头原始输入(尺寸应该是 [8, 1280, 960, ?] 不知道是多少 channel,常规 AI 任务中的图像通常都是经过简单处理之后的 RGB 3 channel,不过这里既然强调了是 12 bit 的原始输入,有可能 channel 数量会更大以保留更多图像信息?)
- [8, 1280, 960, ?] -> camera 矫正(大胆猜测尺寸没变,还是 [8, 1280, 960, ?])
- RegNet 各个部分输出 [8, 160, 120, 64],[8, 80, 60, 128],[8, 40, 30, 256],[8, 20, 15, 512]
- RegNet 输出接 BiFPN,尺寸信息 ppt 里没看到
- 图像转 BEV 视角以及 transformer 多摄融合,这里出来之后我理解应该就没有摄像头的数量信息了,输出尺寸直接是 [20, 80, 256],代表的是鸟瞰图里面车周围 20 * 80 单位上的信息
- [20, 80, 256] -> 接下来用时间信息和距离信息保持 feature 队列,一次出 60 个单位(帧?)的数据用来作为视频模块的输入,尺寸是 [20, 80, 256, 60]
- feature [20, 80, 256, 60] + IMU [1, 1, 4, 60] + position [1, 1, 40, 60] -> 视频队列 [20, 80, 300, 60] -> 下采样 [20, 80, 300, 12]
- [20, 80, 300, 12] -> RNN 输出 [20, 80, 300]
- 最后接各种检测头到不同的分类任务上
Planning and Control @ 1:13:12
规控这部分咖喱味口音略重,有点不太容易听清楚。
规划上主要的矛盾点在于:
- 决策空间是非凸的,适合用离散搜索,连续函数优化(常规的梯度下降等迭代数值求解法等)容易陷到局部最优解里面去
- 决策空间又是非常高维的,离散搜索在计算上不好实现(复杂度可能是高维指数级的,计算量爆炸),只能用优化方法做
那折中可行的方案就是把这两种结合起来。首先用粗粒度的搜索从整个决策空间中搜出最优解所在的一个小范围空间(Convex Corridor),然后在这个局部空间里面用优化方法求最优解。
Vector Space -> Coarse Search -> Convex Corridor -> Continuous Optimization -> Smooth Trajectory
这里举了个例子,导航给的路径是过了这个路口之后在下个路口左转:
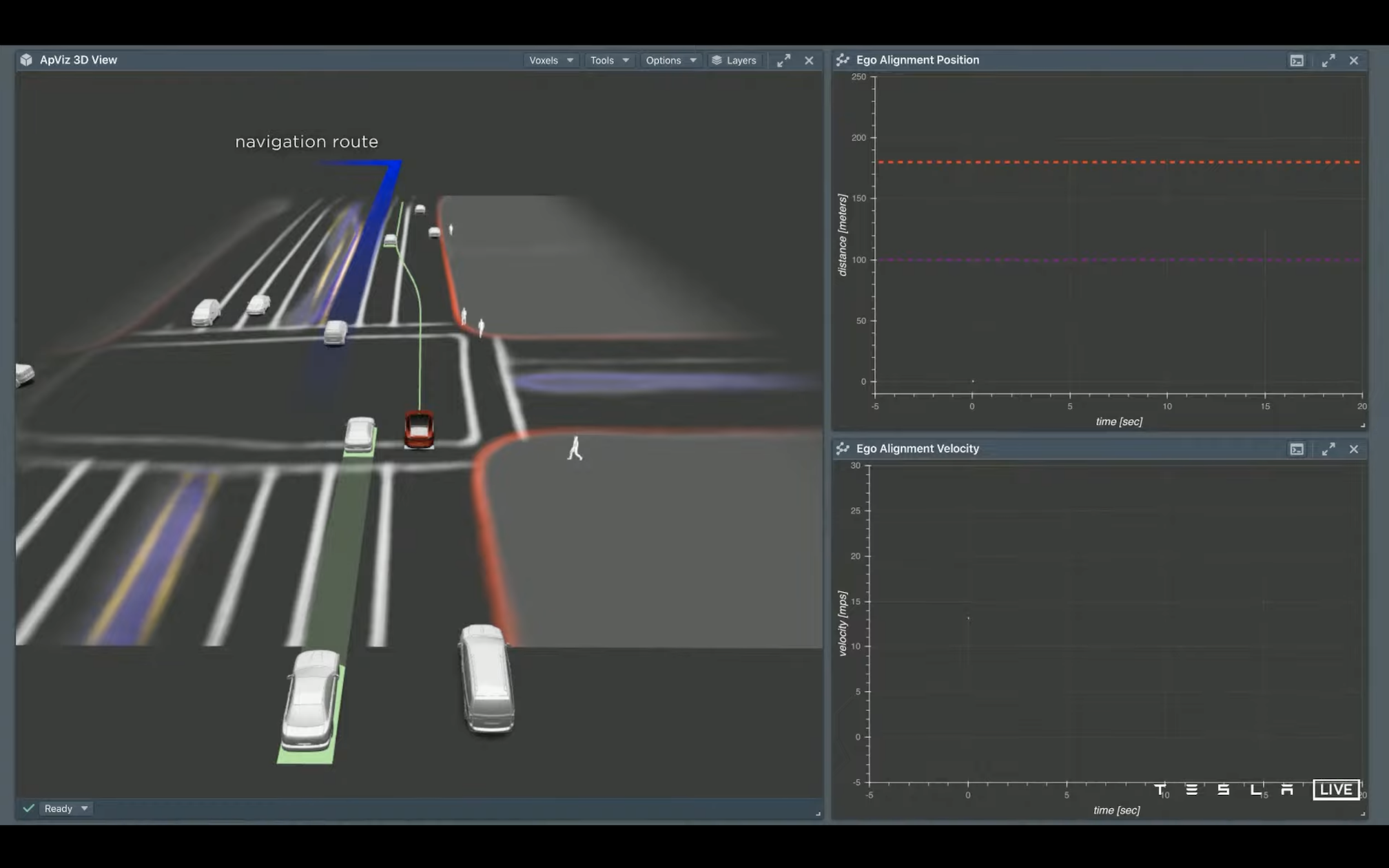
方案一:过路口后减速,提早左转,可能会需要插到别的车队中去,too uncomfortable(需要过路口后迅速刹车,break pretty harshly)
方案二:过路口后加速冲过去,在左侧的车之前左转,这样会有充足的距离和时间,但是也有错过左转窗口的风险
对这两种方案之间做搜索优化后就可以找到一条特别平顺的路径来完成这个左变道的动作。目前他们的算法可以提前规划 10 秒的决策,实际执行的效果基本上也是非常贴合规划路径的。
下一个例子用来说明的是规划算法除了自身规划以外,还需要给环境中的其他对象的行为也做一个预测。窄道交汇车:
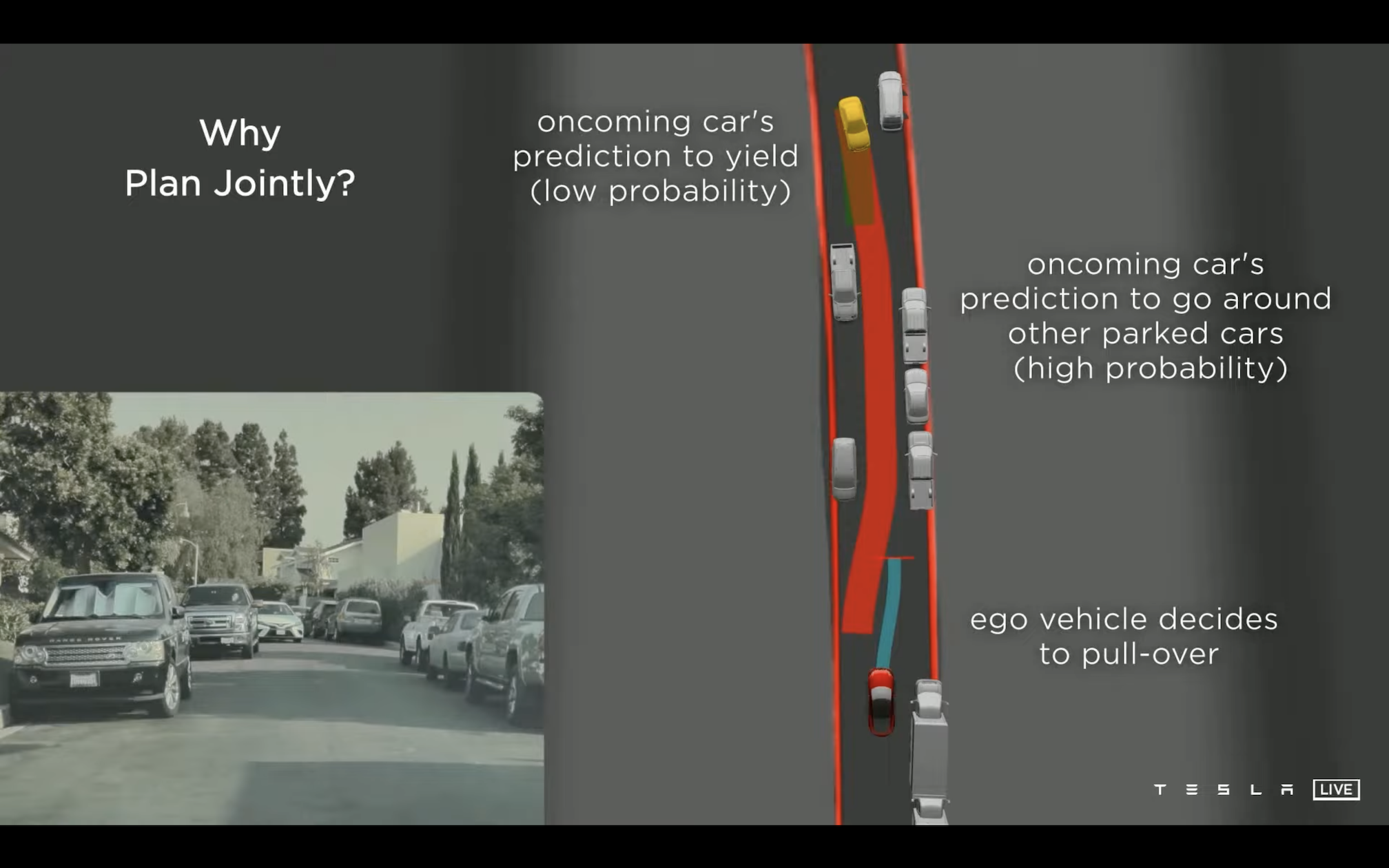
发现前方车辆时,预测出对方车辆的行进路线有大概率会卡死整条道,因此在这里的规划上选择我方向右侧避让(这里是右侧刚好有空间,有点好奇如果没有避让空间会怎么样)。等到后面发现对向车辆停住时,修正对对方的预测,此时中间的路可以通行,因此看到视频里面我方停顿了一下之后马上流畅地继续开过去了。
这个例子感觉做的非常漂亮,已经很像人类老司机会做的判断了。
下面这个才终于是前面提到的粗粒度搜索 + 细粒度优化的例子。视频里面首先搜出一个灰色的凸空间作为接下来路径优化的硬约束,之后再在这个小空间里面去做连续平滑路径的规划。
再往下是搜索算法的选择,给的是一个停车场泊车的例子,蓝框是目前的位置,绿框是最终目标要停到的位置:
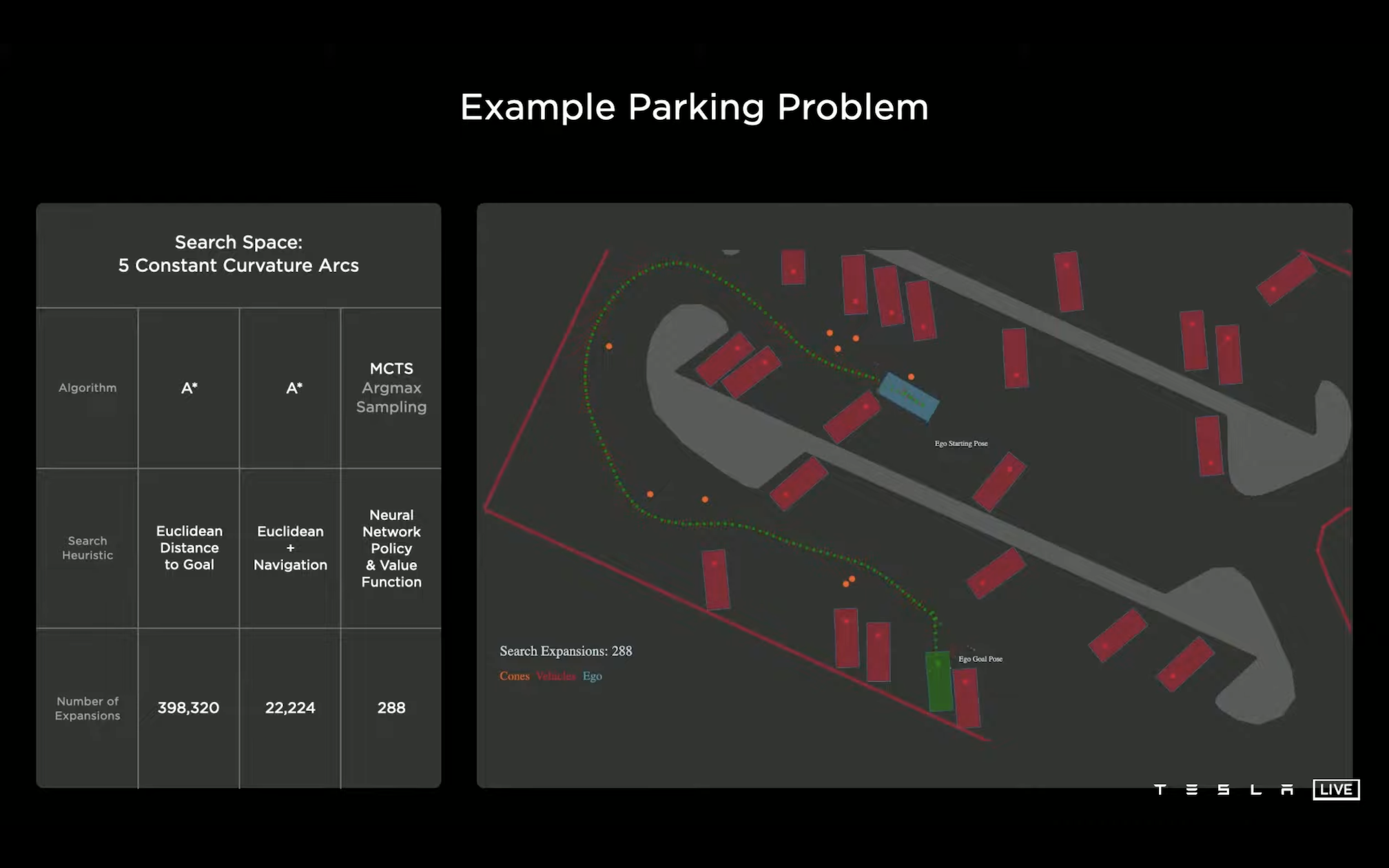
启发式搜索(A*)是比较常规的选择,首先对比了两种 A* 的方案:
- 基于目标欧式距离的 A*:搜到目标路径一共需要 398320 次,搜索过程中非常容易陷到局部出不来,这种搜索效率基本上不太可用;
- 在欧式距离基础上再加上导航信息的 A*:相当于用地图的导航路径做了很大程度的搜索剪枝,效率提高了很多,只需要 22224 次就能够搜到结果了,但是还是不够高效,而且从搜索过程看就会发现其实浪费了很多时间在处理路中间出现的障碍物(行人、桩桶等等)上
他们发现 Heuristic 信息在搜索过程中非常重要,需要一种比导航路径更加有效的全局信息来指导搜索过程,于是他们想到了神经网络。
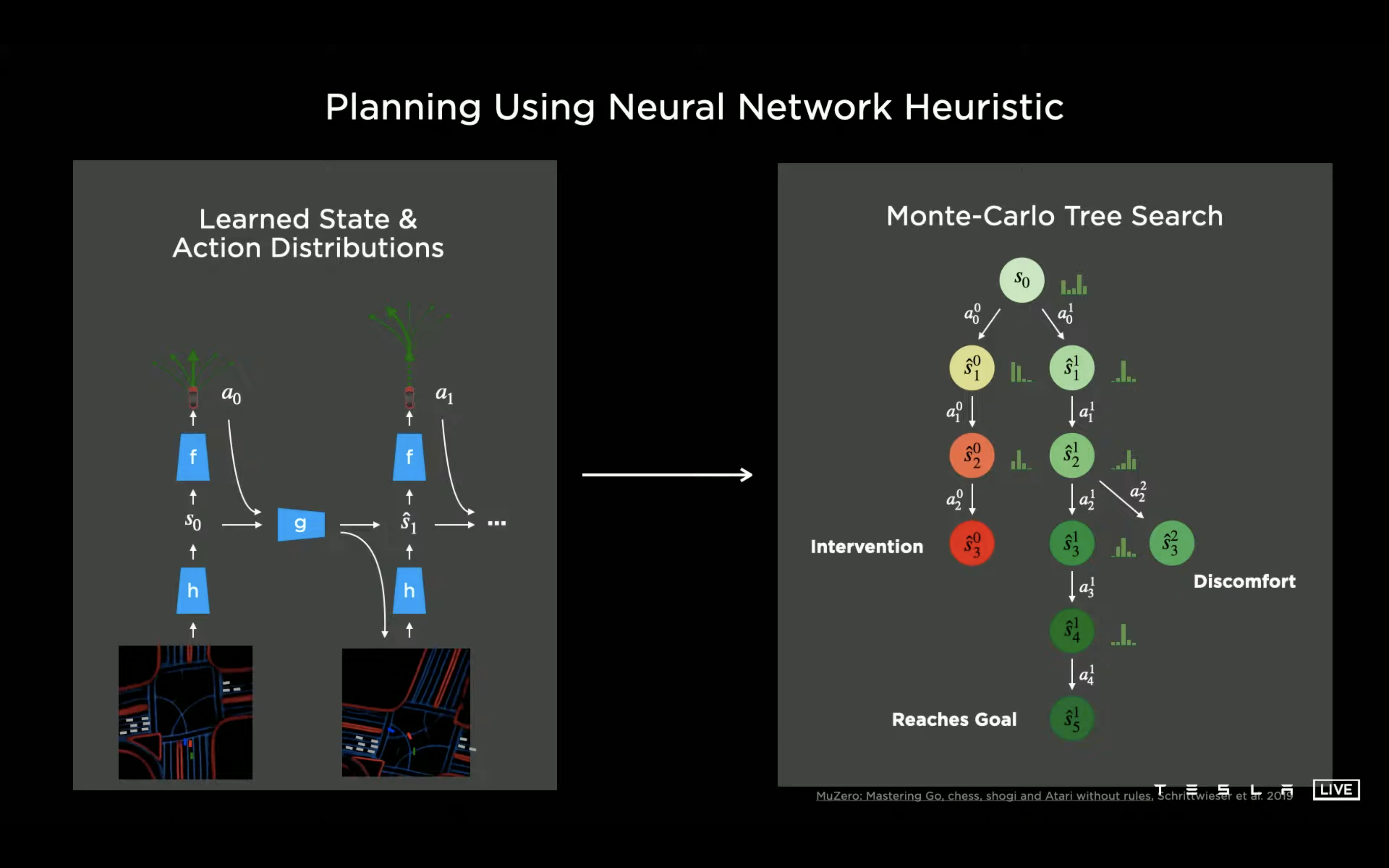
如果把整个规划抽象成全局信息、决策、更新全局信息后再继续决策的过程,本质上就跟 alpha go 要解的是一样的问题了,因此也可以用类似的成熟方案去实现,直接上 NN + 蒙特卡洛搜索。(666666…)其他比如人工干预信息、距离、时间以及某些决策是否会让乘客舒服之类的都可以作为额外的 cost function 加到蒙卡树里面去。
甚至都还没把地图信息加上,就只需要 288 次搜索就能够找到非常好的结果了。(换句话说如果再在这个基础上加上高精地图是不是就更有效了?)
最终的系统架构如下:
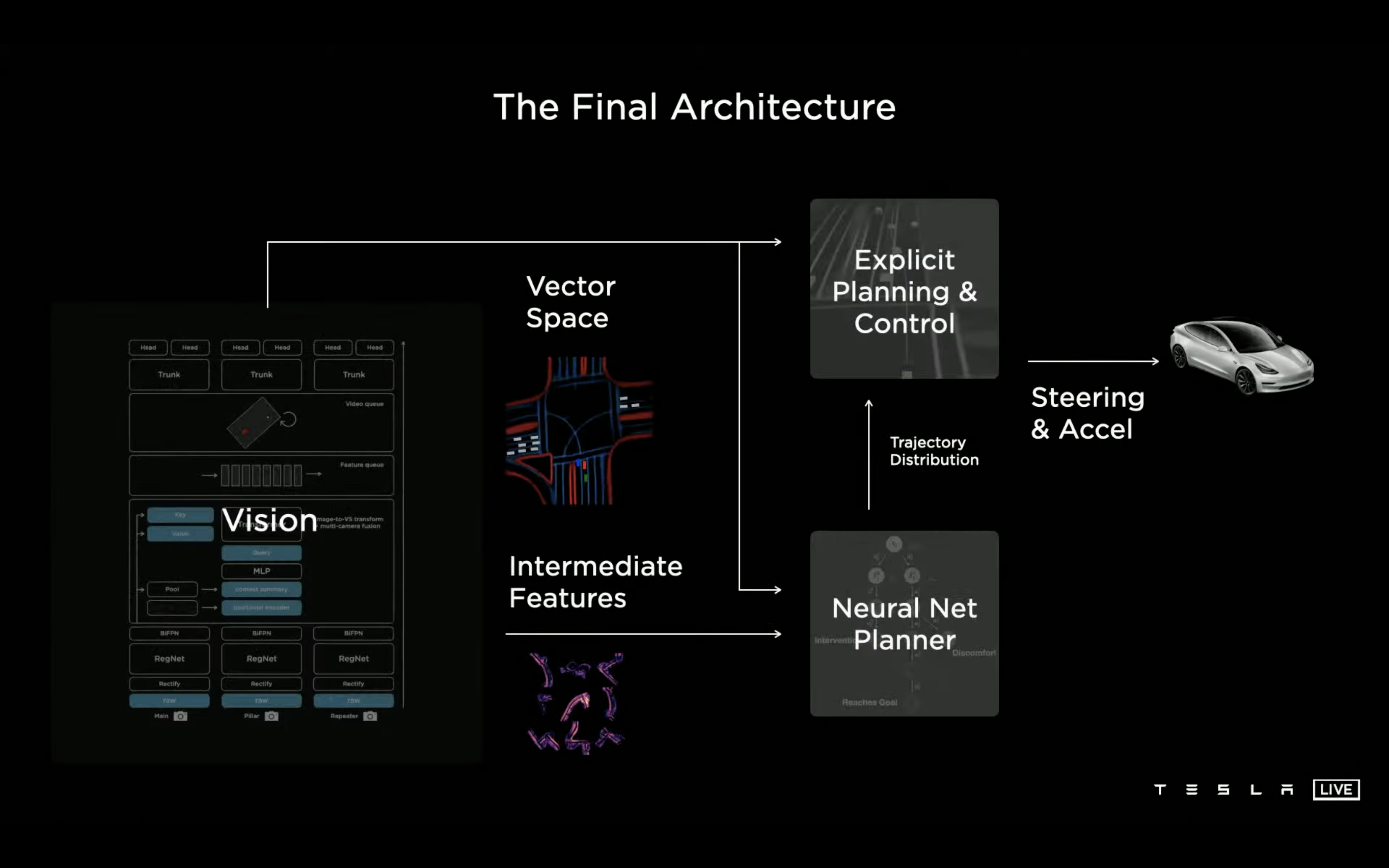
本身感知模块产出的环境信息(基于摄像头得到的鸟瞰图)以及识别出的特定目标就是给规控做路径规划和决策的,现在就是相当于在下面多加了一个 NN Planner 部分,输入是感知 NN 里面某个中间层的 feature 用作 MCTS 的全局信息。
Labeling & Simulation @ 1:24:35
接下来这一段是我关注比较少的部分,主要是介绍 TESLA 如何标注数据以及通过模拟器来生成大量的训练数据。其中涉及到的自动化标注以及自动化场景重建等也都是相当硬核的工作。
这里就先略过了…
Hardware Integration @ 1:42:10
接下来跟硬件部署相关的终于到了我自己的工作领域了。
模型和算法部署上车的目标是最小化延迟以及最大化帧率,车上部署的是一块叫 FSD Computer 的板子,集成了两块自研的 SOC。
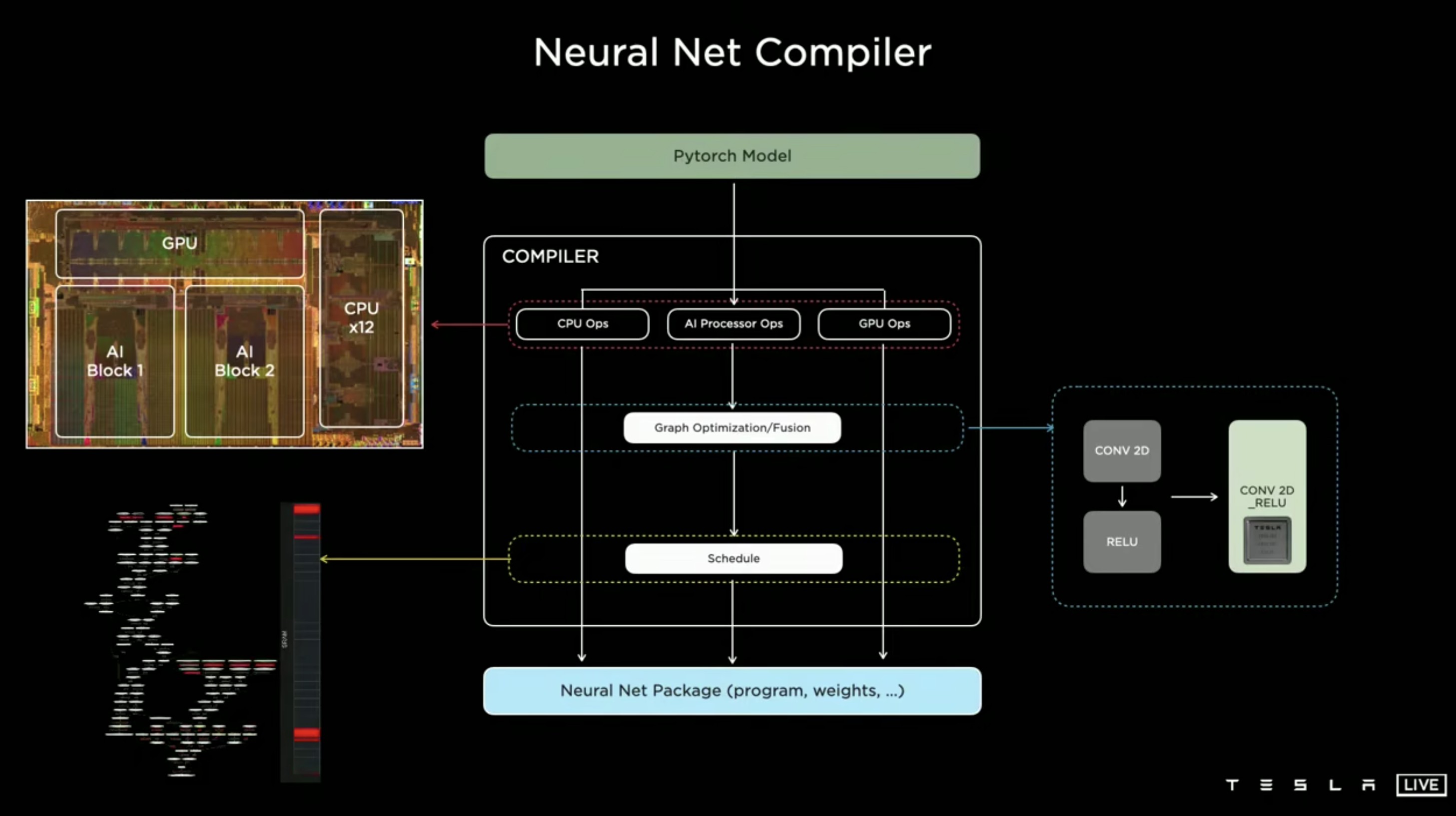
每块 SOC 看起来应该就是他们在 19 年发布的 FSD Chip,片上 3 个 ARM v8 A72 cluster 一共 12 个 CPU 核,一个 Mali G71 GPU 以及两个 NPU 单元。
这里面 Mali GPU 的算力比较低(FP32/FP64 600 GFLOPS),基本上只是用来跑一些基础的预处理用,主要的网络计算还是要放到单块 (INT8 36.86 TOPS) 的 NPU 上跑。
整体部署链路看起来比较常规,也是采用了 AI Compiler 的方式去做图优化以及 kernel fusion,再 schedule 到 NPU 上。关于这里的 schedule,视频里面介绍得偏少,看左下角的动图很像是编译期就决定好的静态调度?
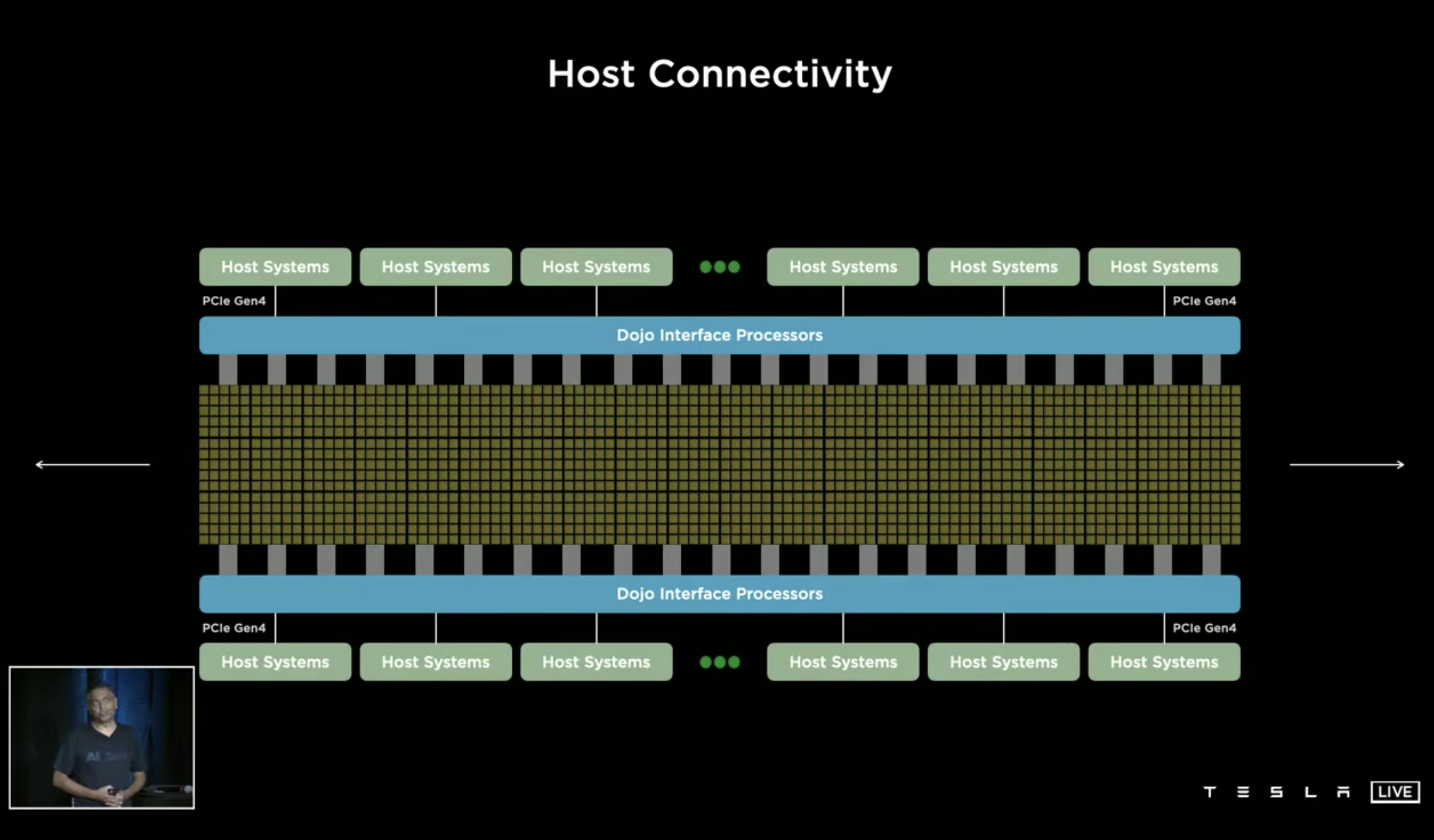
Dojo @ 1:45:40
比较可惜的是我想了解的更多的还是他们车上的部署部分,但是 AI day 上很快就跳到下一个 HPC 训练部分的环节了。
TESLA 之前使用的也是比较传统的 NVIDIA GPU 集群的方案,他们目前已有的规模是:
- 自动标注集群:1752 GPU + 5 PB
- 训练集群 1:4032 GPU + 8 PB
- 训练集群 2:5760 GPU + 12 PB
然后…That’s not enough!
常规 HPC 集群能用的最灵活的分布式架构就是下面这种 2d mesh 的方式了:

每个计算单元可以是一台多卡 GPU/NPU 的服务器,然后通过 Infiniband 的高速网络互联。但是问题在于这样 scale up 计算的规模是很容易的,但往往受限于节点间的数据传输带宽,全局同步等等,就比较难 scale up 全局的 throughput 以及 latency 了。
Dojo 的基本架构还是这种 2d mesh,但是达到了 extremely high bandwidth & low laytencies,然后通过软件层面的 AI Compiler 做到各种灵活的模型配置以及数据的 locality。
对于 mesh 中每个计算单元尺度的选择上:如果太小则每个单元的计算能力会很小,大量计算单元之间的 sync 代价会很高;如果太大(例如比较常规的 8 GPU 卡甚至更大尺度的服务器),计算单元之间的传输带宽又会受到限制(比如在这种尺度上就只能通过网络来通信了)。
他们定位出的核心矛盾是 bandwidth 和 latency,因此计算单元的设计也是极致的 laytency 导向的:
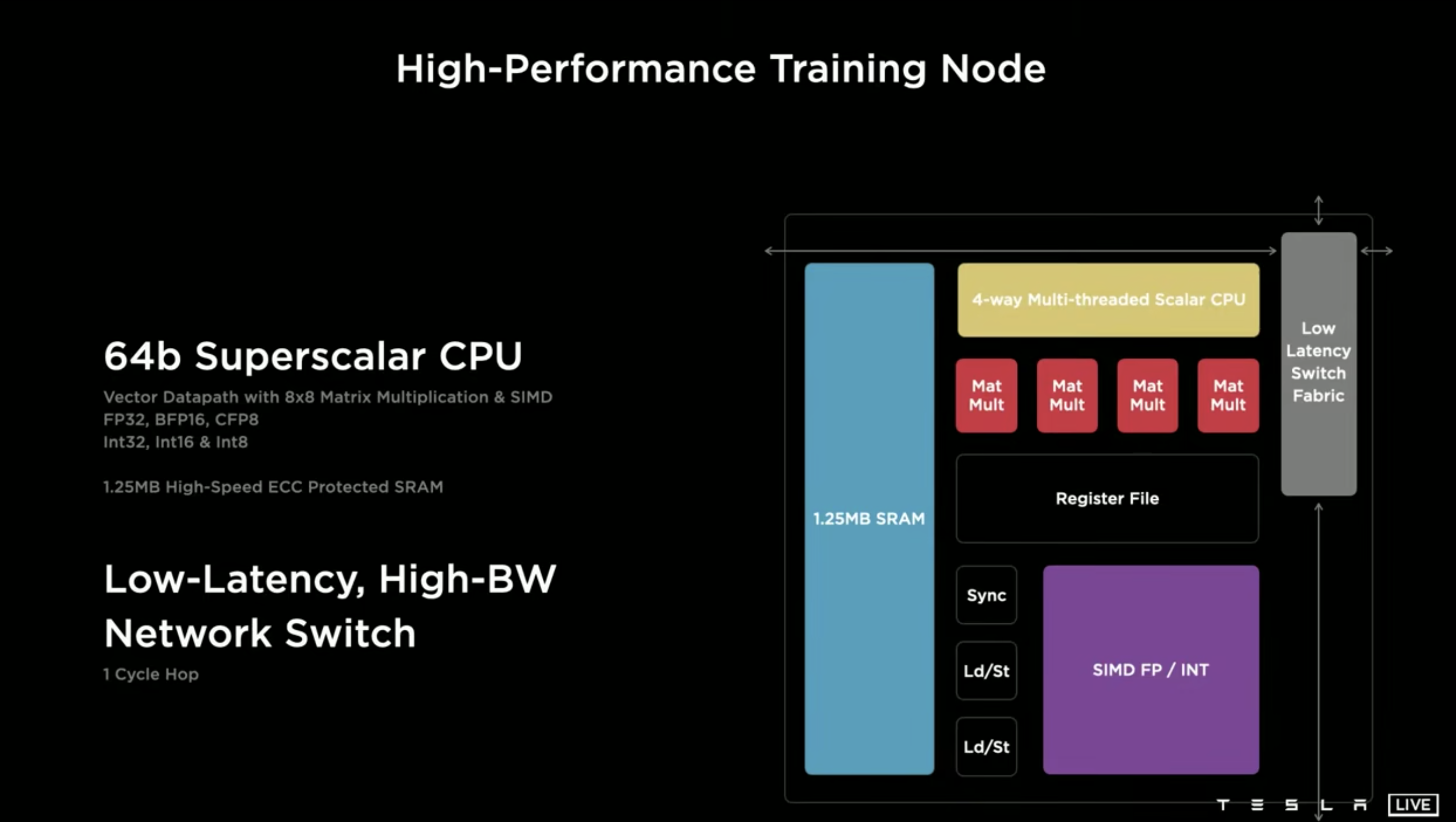
Dojo 最终架构中的 training node 单元是一个单核 4 路超线程的超标量 CPU,CPU 和 CPU 之间通过 1 cycle latency 的 mesh 互联。
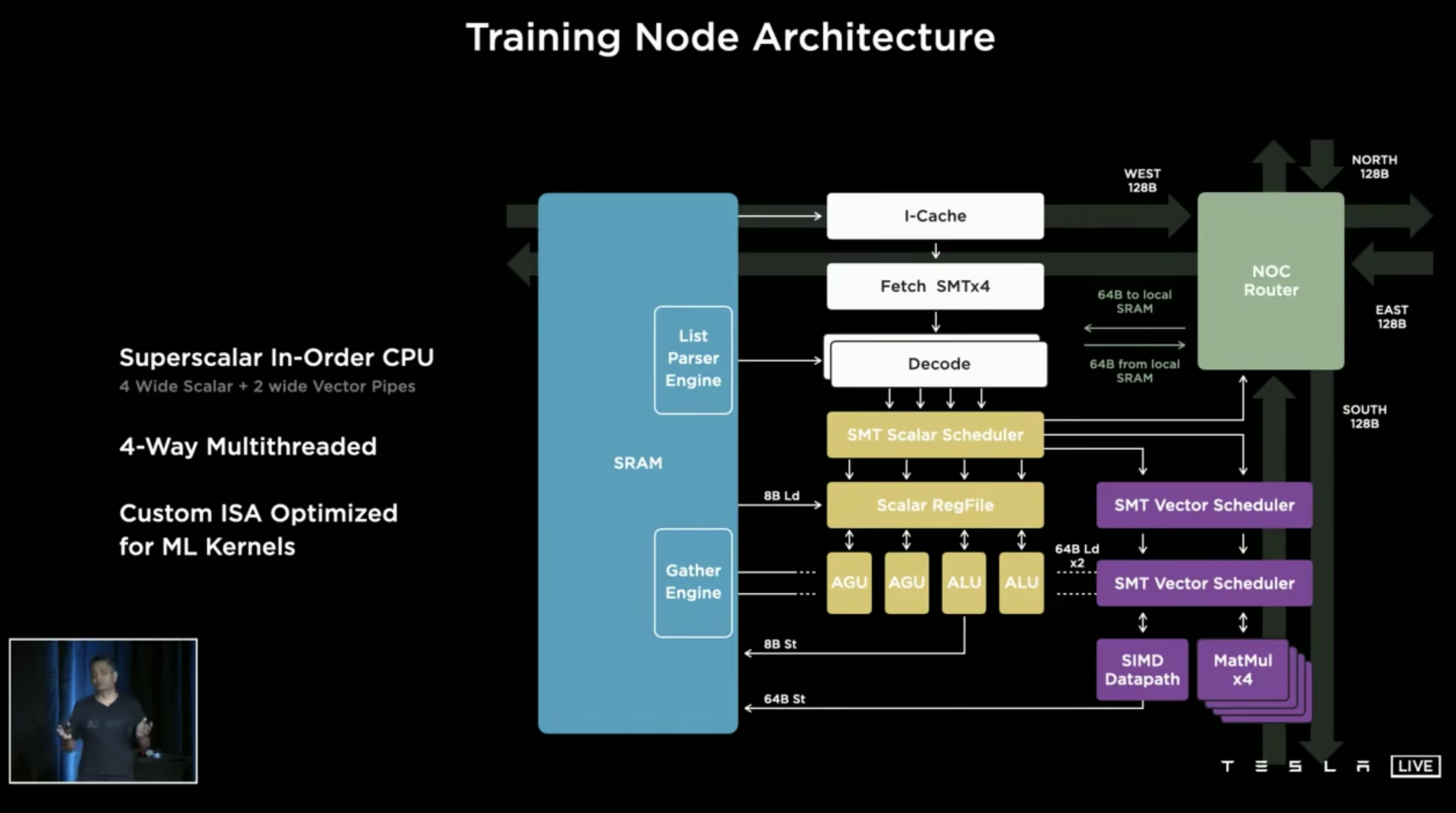
单 CPU 的算力数据是峰值 1024 GFlops 的 BF16/CFP8 (2Ghz * 4 个 Matmul 单元 * 8 * 8 * 2FMA)和 64 GFlops 的 FP32。
最终集成的 D1 chip:
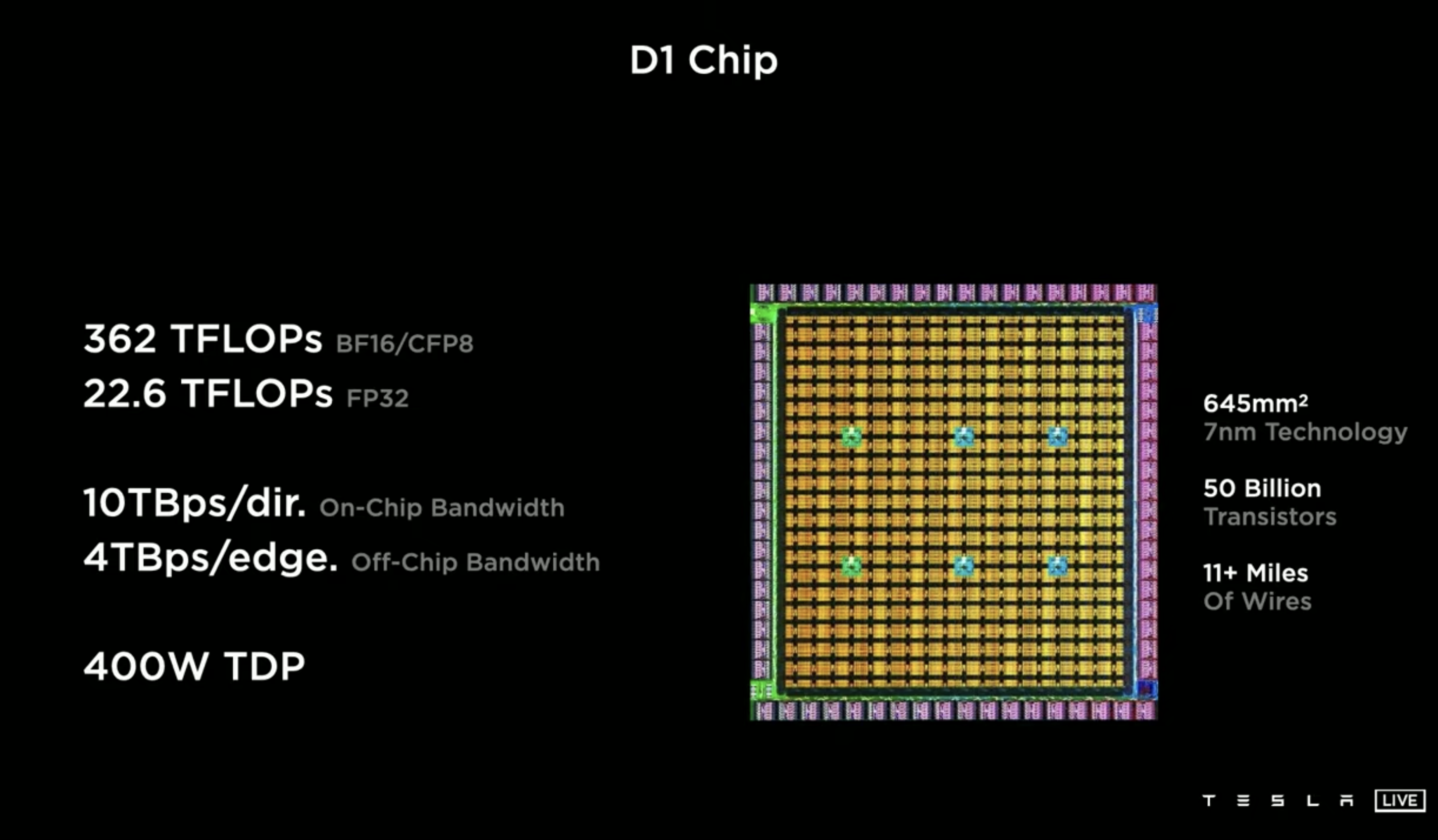
362 TFlops(前一页 PPT 上说一块芯片上是 354 个 nodes,如果照单 CPU 的算力算应该是需要 362 个 nodes,不知道是不是哪里没对上…),巨大的访存带宽。但从一块 D1 的算力性能来说基本上是 GPU/NPU 的级别了,但是他们这里还是强调这玩意是 CPU 的架构,应该可以算是个众核 CPU 芯片了。
恐怖点在于在这么高的片上、片间互联带宽下,这玩意的扩展性可以说是吊打 NV GPU 啊。
D1 system 图中的每一个小黄块都是一块 D1,在这种架构下,可以非常轻松地扩展到 50W 个 CPU(50W TFlops?)
再以上面这个图中的 D1 system 作为一个基础 unit,进一步可以构建出下面这样的 trining tile:

可以达到恐怖的 9 PFlops BF16/CFP8 以及 36 TB 访存带宽。
由 120 个 Training Tile(3000 块 D1 芯片,超过 1 M 个 CPU nodes)组成的 ExaPOD 可以达到 1.1 EFlops 的算力。
可以 … 这么简单粗暴就达到超算 top 500 第一名的水平了。(更正一下,想起来超算 top 500 的算力应该是 linpack 的 fp32 实测结果,这里 Dojo 给的 1.1 EFlops 是 BF16/CFP8 的理论峰值性能,那还是要差不少的)
About NIO
NIO 从 2021 年开始针对 NT2.0 这一代的自动驾驶平台全栈自研。截止本次更新(2022 年),目前我们自研的感知算法 + orin 硬件平台已经在 ET7、ET5、ES7 上交付。
目前主要体现的地方就是方向盘后仪表盘上实时显示的感知结果:

包括车道线、车辆、行人等等。这些是综合了车上激光雷达、各个视觉摄像头等多种传感器的融合感知结果,其实显示在仪表盘上的只是目前开放的一小部分,完整的结果会被用于紧急刹车等安全功能以及未来开放的 NAD 这些辅助/自动驾驶功能中。
据我所知目前国产自动驾驶参赛选手好像只有理想官宣已经用上了 BEV,目前 NIO 这边的 BEV 进度应该是在 2022 年内可以完成,等达到足够的路测里程后就可以 OTA 更新给目前 NT2.0 的所有用户了,可以预见之后感知的效果也会比目前的软件版本更上一层楼。