接上篇:
- TensorFlow 拆包(一):Session.Run()
- TensorFlow 拆包(二):TF 的数据流模型实现
- TensorFlow 拆包(三):Graph 和 Node
- TensorFlow 拆包(四):Device
- TensorFlow 拆包(五):Distributed
本篇分析 TensorFlow 1.6.0 中的 RDMA 以及其他的传输优化的实现。
虽然我前面一篇论文做的工作也是这个,在当时 Yahoo 实现的 RDMA 版还没有收录进官方 Repo 的时候稍微做过一下对比,现在来看看收进官方库之后的具体实现是什么样的。
之前对 GPU Direct 的 API 不是很了解,后来才发现这里的 RDMA 实现其实也是直接支持 GPU Direct 的。
VerbsServer
TensorFlow 分布式环境中的 Server 结构通过 ServerFactory 构建,这个工厂模式会根据传入的 protocol 选项创建不同的 Server。
当选择 protocol = grpc+verbs 时,tf.train.Server()创建 VerbsServer。
在代码里面搜
public ServerFactory可以找到 4 个继承类,除了 verbs 之外,其他分别是:
protocol = grpc对应GrpcServer,即原本默认的 gRPC 通信方式
protocol = grpc+mpi对应MPIServer,用 MPI 来完成通信
protocol = grpc+gdr对应GdrServer,即 GPU Direct 支持
从 protocol 的名字上也可以看出来,这几个新增的通信方式实现都还需要依赖 gRPC,例如 RDMA 一开始的 IB 卡配置、连接建立什么的都还需要先用 gRPC 来完成。
VerbsServer()在构造时直接初始化了一个GrpcServer(),之后的Init()、Start()也都是先启动 GrpcServer 中对应的方法。同时创建一个 VerbsService(重载的 ServerCompletionQueue 类)。
然后创建一个 RdmaMgr() 用于管理 RDMA 底层的连接,RdmaRendezvousMgr()用于管理数据存储。
RdmaMgr
RdmaMgr 中维护了 RdmaAdapter 和 RdmaChannel 这两个结构,RdmaAdapter 负责维护 RDMA 通信需要的底层结构(rdma device context、protection domain、事件 channel、完成队列等等),RdmaChannel 则是代表每一个独立的 RDMA 连接。
RdmaMgr 初始化时对所有不在本地的 worker 创建一个 RdmaChannel(创建和设置 queue pair,初始化 buffer),插入到 channel_table_ 中,。
VerbsServer 启动时,首先启动 GrpcServer(GrpcServer::Start()),再通过 RdmaMgr 来建立 rdma 通道之间的链接(rdma_mgr_->SetupChannels()),之后在rdma_mgr_->ConnectivityCheck()中,分别测试各个 rdma 链接的连通性,然后用rdma_adapter_->StartPolling()启动 RdmaAdapter 中的守护进程,等待后续 RDMA 传输信息,后面 Grpc 的传输通道应该就不需要再用了。
RdmaRendezvousMgr
RdmaRendezvousMgr 继承于 BaseRendezvousMgr,具体的实例类是从 BaseRemoteRendezvous 继承过来的 RdmaRemoteRendezvous,整个 RDMA 的传输过程由 RdmaRemoteRendezvous::RecvFromRemoteAsync() 开始。
基本上做 RDMA 优化的想法都是一致的,跟我们之前的实现很类似,其他的详见官方文档:
Memory Management
说起来,事实上 RDMA 的移植过程中的最大问题还是内存,因为要用 RDMA 就需要事先把内存注册到 IB 卡上,这样 IB 卡才能够有权限直接读写内存并且保证这块被注册过的内存不会被换页换出去。
所以对于他们的 RDMA 实现来说,我最关心的还是这个部分。
TensorFlow 原本的实现就是在传输的时候动态给 send 操作分配内存。
通常的思路有三种:
- 数据传输的时候现场把需要被传输的 Tensor 内存注册到 IB 卡上,用过以后再释放掉。这样很明显会有很大的 overhead。
- 提前注册一块固定的内存,传输的时候把需要发送的数据 copy 进去,然后在那块预注册的内存上进行 RDMA 操作。Overhead 会小一点,但是中间需要的
memcpy操作还是有点浪费。 - 内存池!!手动维护一个内存池,实现就把内存池注册到 IB 卡上,然后传输过程中,动态申请内存、用后动态释放内存都从内存池里面走。
想想都知道第三种方案是最好的,然而我们当时实现时没有成功把内存池写出来(后来,这事就成了挖好了但是一直没填上的大坑了【写着玩之 内存池】、【写着玩之 RDMA 轮子】。。。。。。很难受),所以其实采取的是 1、2 混合的方案。
当要发送的数据比较少的时候,memcpy 速度快,所以拷过去再发效果好点,发送的数据大的时候,就现场注册。然后我们还分别试了用了 RDMA_WRITE 和 RDMA_READ 这两种方式,想办法把注册内存的时间跟计算、通信这些 overlap 开(虽然效果很有限,但是能做一点是一点咯)。
官方库里目前的实现用上了内存池:
- 对于 DMAable Tensor(注册在支持 RDMA 的 CPU 上或者注册在支持 GPU Direct 的 GPU 上的 Tensor),都采用直接从源 Tensor 写到目标 Tensor 中的方案,完全避免了内存注册和内存拷贝。(66666666)
- 非 DMAable 的 Tensor,用 Protobuf 序列化之后通过预注册的内存传输(方案 2)。
- 不支持 GPU Direct 的 GPU 数据,虽然还是要拷回 CPU 端,但是 CPU 到 CPU 的传输用的还是 RDMA。
Memory Pool
那么就来详细看一下这里的内存池实现,这里实际上是借用了 TensorFlow 本身自带的内存池(。。。嗯,我前面挖了很长时间的内存池坑到时候就扒这个来填吧)。TensorFlow 本身的内存分配就是通过自己维护的内存池来完成的。
关于 TensorFlow 的内存管理实现,可以参照这里的说明,主要采用的还是比较简单的 BFC 算法。
tensorflow/core/framework/allocator.[ch] 是内存分配器的主要入口,具体的分配器实现在 tensorflow/core/common_runtime/ 中的 xxx_allocator.[ch] 中。
RDMA 部分的内存管理由一个单例模式的 RdmaMemoryMgr 结构来完成。
在 VerbsServer::Start() 中有这么一步 rdma_mgr_->InitAllocators():
- 首先获取到本地所有的 Allocator,CPU 分配器以及可能的 GPU 分配器。
- 把 RdmaMemory 中插入/删除 Memory Region 的操作(主要是处理内存到卡上注册的这一步)包装成 Visitor 的接口函数。这里的 Memory Region 跟 TensorFlow 自己内存池里面的不是一个概念(指的目标倒可能是一致的),而是指的一整块独立内存(一次性用 ibv_reg_mr 把一整块内存注册好,一块内存对应一个 mr)。
- 后面再检查当前环境是否支持 GPU Direct,是则同样把 GPU 的 Visitor 也加上。
之后需要用 RDMA 进行传输的时候,就可以从已有的 Memory Region 表中找出某块内存所对应的 mr、rkey 等等,而无需再注册了。
Transport protocol
TensorFlow 中的传输设计是异步发送,阻塞接收,这个设计也很容易理解,没有收到数据之前,当前节点之后的肯定执行不了,而发送者将内容提交之后数据流图到这里为止就结束了,可以把计算资源用于其他地方。
这张图来源于代码中的文档部分。
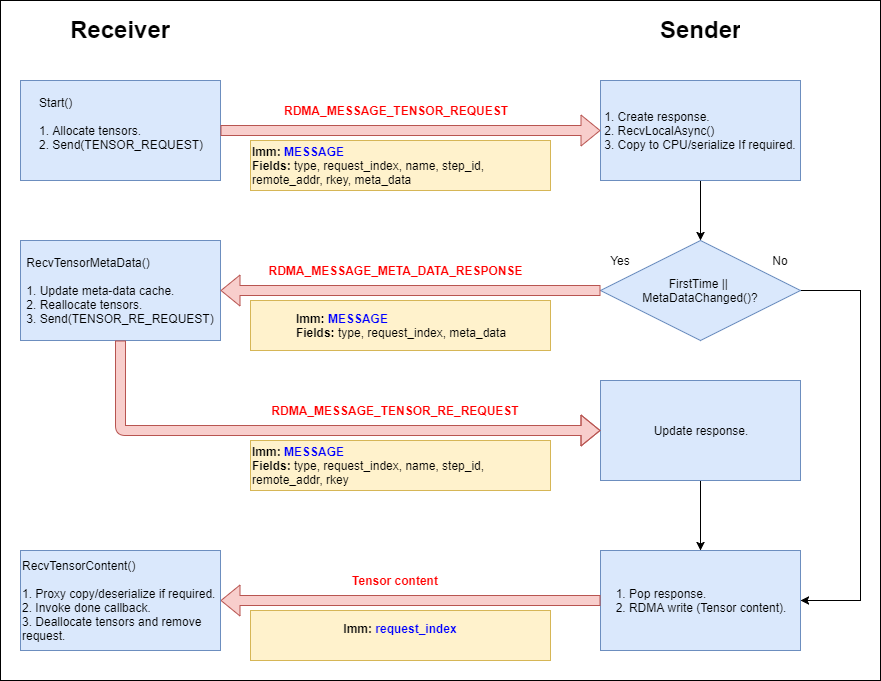
RecvFromRemoteAsync
一次完整的传输过程从 RdmaRemoteRendezvous::RecvFromRemoteAsync() 开始:
- 解析某条需要传输的 Tensor 的源地址和目标地址,确认目标地址是本机。
- 从 rdma_mgr_ 记录的 channel 中找出源地址对应的传输通道。
- 向传输通道中发送一条 Tensor 请求(构造一个新的 RdmaTensorRequest 并插入到 channel 的 request_table_ 中,启动
RdmaTensorRequest->Start())。
接收端这边的所有操作都封装在 RdmaTensorRequest 结构中,相对的,发送端这边用来响应请求的所有操作都封装在 RdmaTensorResponse 结构中。
Start() 首先在 RdmaMemoryMgr 中检查本次需要接收的 Tensor 的Meta Data 是否存在(用 Rendezvous 的 key 作为关键字)。Meta Data 记录的是所传输的 Tensor 的详细信息:
1 | class TensorMetaData { |
最主要的内容是形状(TensorShape)和数据类型(DataType)。如果 Meta Data 记录存在,则可以直接新建一个 Tensor(构建 Tensor 需要传入的参数是 Allocator、数据类型以及形状)。从 RdmaMemoryMgr 的 Memory Region 表中直接可以查到所分配的内存的 mr 信息。如果本机不支持 GPU Direct,则把目标改成本地 CPU 端的内存接收;如果当前传输的 Tensor 的数据类型甚至都不支持 memcpy,则把它先序列化成 Protobuf 再传输。
话说这里序列化是现场 malloc 内存,现场 ibv_reg_mr,为什么不直接从 CPU 的 Allocator 里面分配呢?
之后发送 RDMA_MESSAGE_TENSOR_REQUEST 消息。消息中包含的内容除了 key 之外,最重要的就是前面准备好的 Tensor 地址和 rkey 了,这个标识了远程的发送端等一下要把数据写到什么地方去。
Sender Side Recv Message
守护进程 RdmaAdapter::Process_CQ 处理所有传入的 RDMA 消息,接收到 RDMA_MESSAGE_TENSOR_REQUEST 时,解析出收到的数据,构造一个新的 RdmaTensorResponse 并插入到 channel 的 responses_table_ 中,启动 RdmaTensorResponse->Start())。
这一步调用 RecvLocalAsync() 从本地的 Rendezvous 中异步获取接收端所请求的 Tensor 数据,成功完成本地数据提取之后用 RdmaTensorResponse::RecvHandler() 开始准备数据的回传:
- 对比本地提取的 Tensor 数据与接收端需要的 Meta Data 的各项是否一致(话说为什么会有不一致的情况呢?)
- GPU:
- 数据一致且支持 GPU Direct:同步一次 GPU 流,完成后直接用
RdmaTensorResponse::SendContent()发出去; - 数据一致但不支持 GPU Direct:把 Tensor 从 GPU 上拷到 CPU 上,发出去;
- 数据不一致:需要重新请求同步 Meta Data,但是这条 Tensor 在数据流图中可能还会被其他节点的运算改变,因此需要先把 Tensor 从 GPU 上拷出来,然后发送更新后的 Meta Data 信息给接收端;
- 数据不支持 memcpy:把 GPU 数据序列化之后发送出去。
- 数据一致且支持 GPU Direct:同步一次 GPU 流,完成后直接用
- CPU:
- 数据一致:直接发送;
- 数据不一致:发送更新后的 Meta Data;
- 数据不支持 memcpy:序列化之后发送。
这个 Meta Data 重新请求的部分可以改成接收端直接用 RDMA READ 来抓取。
发送完成之后回收用过的资源,然后把当前 RdmaTensorResponse 从 responses_table_ 中删掉。
RecvTensorContent
接收端收到传入的 Tensor 数据之后,根据是否需要从 CPU 拷回 GPU 或者是否需要反序列化等等,做出对应的操作,调用 RdmaTensorRequest 创建时上层传入的 done() 回调函数,最后回收资源,把当前 RdmaTensorRequest 从 request_table_ 中删掉。
看到这里思路可以说是很清晰了,感觉上这里的 RDMA 实现也已经相当完善了(比我们当时做的好多了),细节上可能还能再抠一抠,不过再往上应该不会再能有什么大的性能提升了。