接上篇:
- TensorFlow 拆包(一):Session.Run()
- TensorFlow 拆包(二):TF 的数据流模型实现
- TensorFlow 拆包(三):Graph 和 Node
- TensorFlow 拆包(四):Device
单节点的运行流程基本上已经有个大体印象了,接着就要来拆我所关注的重点所在——分布式运行时了。
Architecture
进入代码部分之前,首先看一下官方文档中,对整个 TensorFlow 结构的介绍。以下是一个典型的分布式 TensorFlow 的架构图:

这里的 Master 和 Worker 服务只在分布式运行时中有,可以认为单节点的 Session 是包含了这两个服务的全部内容。
Client 指的是面向用户的前端编程接口,通常能用的就是 Python 和 C++ 了,client 完成运算图的构建,然后把图的定义通过 session 对象用tf.GraphDef这个 Protobuf 结构传给后面的 Master 服务来跑(即 Python 层定义好计算图,然后通过 Protobuf 的接口进入 C 部分的运行时)。
所以源码中会有
/tensorflow/python/client这个目录,其中的内容做的就是架构图中 client 这个概念的任务。

分布式环境中的 Master 有以下几个任务:
- 精简并且优化计算图,根据当前次 client 提交运行的输入输出目标,提取出一个子图来
- 把子图划分到硬件上(graph -> Partition -> Device)
- 缓存前面那一步的结果,以便以后的 steps 能够重用而不用再把上面两步再执行一遍
这些事情看上去好眼熟啊…没错!这就是DirectSession 中 Executor 的任务啊!
在 tensorflow::Partition()中,划分子图到硬件上,对于不在同一个设备上的边需要补充一对 send/recv 的 op 接口,例如上面那张目标图:

Master 接下来再把任务分给具体的 Worker 服务来完成。每一个 Worker 服务都有自己对应的 tasks,ps 负责存储数据,worker 负责具体的计算。
注意 Worker Service 和 Worker task 的区别,Worker Service 可以有 ps 和 worker 这两种 tasks。

截两张实际运行中 Client、Master、Worker 的关系图。
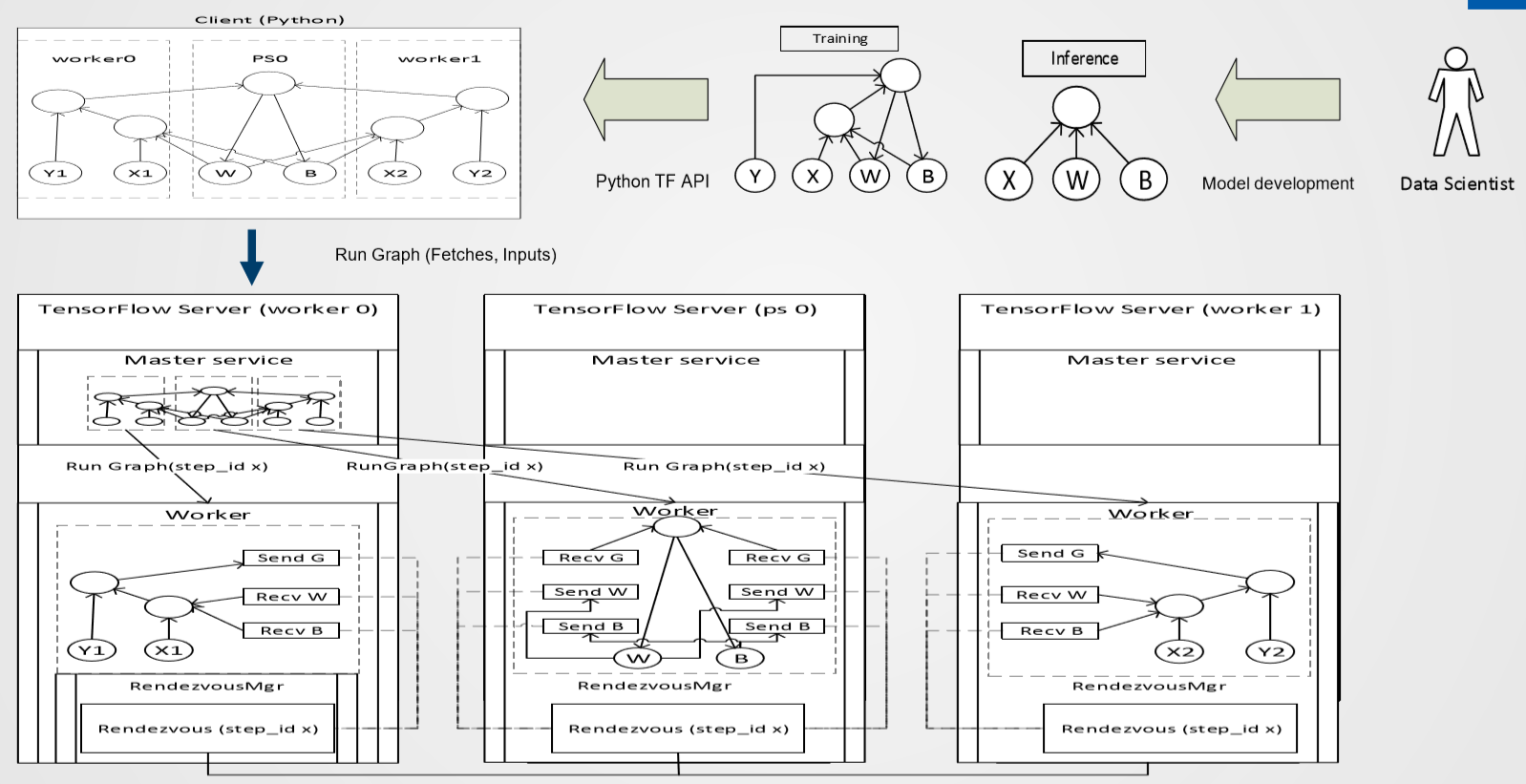
上面一种做法是在 ps 和 worker1 中调用 Server.join(),建图等等的事情全部由 worker0 这边的一份代码完成,大概可以理解成某些代码中的 “Single Session” 的模式。
更常见的写法是下面这种,在 ps 上开 Server.join(),然后每个 worker 分别跑一遍完整的 Python 脚本,自己构建自己本地的计算图。
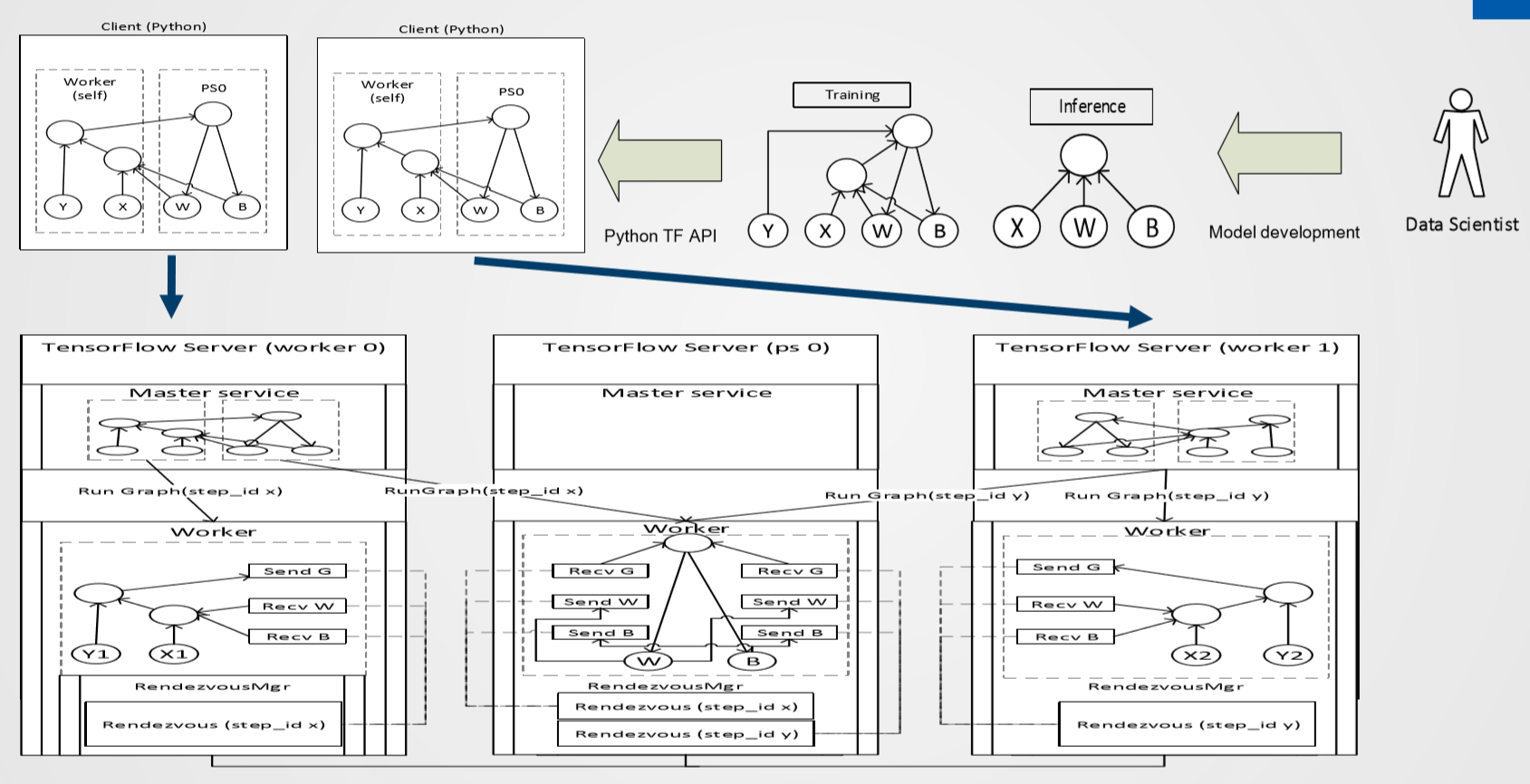
那我们看到 Client(Python 脚本)运行时是通过本地的 Master Service 来管理整个计算过程,Master 相当于单节点环境的 Session 的角色,由它去分配任务给本地的 worker 或者远程的 worker。
Worker 服务有以下几个任务:
- 处理 Master 交过来的请求
- 拿到自己的子图之后,调度其中的 op 完成具体的计算
- 处理与其他 task(即其他的 Worker 服务)之间的数据通信问题
第 2 步的详细处理也是前面分析过的,即ExecutorState 的 RunAsync() 和 ScheduleReady()部分处理的事情了。
关于 send/recv:
- CPU 和 GPU 之间通过
cudaMemcpyAsync()来 overlap 计算和数据传输 - 两个本地 GPU 之间通过 DMA 直接传输
- 在 task 之间(不同的 Worker 服务、不同的计算节点之间)通过 gRPC 或者后来增加的 RDMA 来传输
Master 和 Worker 简单地想可以认为是把 DirectSession 中的 Executor 相关的结构功能给拆了出来。
接下来看看具体的代码实现。
tf.train.Supervisor()
代码从单节点改造成分布式只需要替换掉几个固定的 API 即可,先从 Python 层 API 的 Supervisor 说起。
Supervisor 是一个对 Coordinator、Saver、SessionManager 等结构的封装类,用于管理运行的分布式 Session,在运行中建立检查点,并处理异常情况的恢复等等。
1.6.0 版用这个 API 的时候会有警告说将在未来移除,建议换成
tf.train.MonitoredTrainingSession,但是改用这个新 API 实测性能会下降一截,可能是配置方式需要做一下改变,暂时先放下不作研究。
Supervisor 的构造函数有一堆输入参数,挑几个比较重要的记一下:
- graph:运算图,不指定则使用默认图(这个跟单机版一致)
- is_chief:分布式环境中可能存在多个 worker 节点,但是其中需要有一个作为 chief worker 节点。chief 需要负责初始化整个运行图,其他 worker 节点将从 chief 节点获取计算图的信息
- init_op:图中用于初始化所有变量的 op
- summary_op:用于收集整个运算过程中的有关信息的 op
- saver:chief 将把有关的信息写到 log 中去
- global_step:在分布式环境中全局共享的一个变量,标识当前跑到了第几次迭代
- session_manager:用于管理执行具体运行的 session,也负责异常恢复等等,如果不指定则会创建一个
创建结束时,Supervisor 所关联的计算图将会被锁定,不再允许修改,因为这个图可能会被多个线程共享。
Session
分布式环境下的 C 运行时中存在 3 种 Session 结构,分别是 WorkerSession、MasterSession 以及 GrpcSession,基本上跟前面的 Architecture 是能对应起来的。下面从它们在代码中的调用顺序开始分析:
WorkerSession
WorkerSession 在创建 tf.train.Server()时就被构造出来。
C 层面的 Server 是一个用于管理当前进程中的 Master 和 Worker 服务的结构,通过Start()、Stop()、Join()构成了下图的状态机:
1 | // Join() Join() |
GrpcServer 在被初始化时:
- 检查当前可用的所有计算设备,构建 device 列表(与 DirectSession 中做的
AddDevices()一致) - 创建了 RpcRendezvousMgr
- 检查传入的 cluster 信息中,其他 tasks 的端口等等的信息
- 注册一个 Grpc 的通信 server
- 创建 Master 以及 GrpcMasterService
- 创建 GrpcWorker 以及 GrpcWorkerService
- 启动 Grpc 的通信server
- 创建 WorkerCache
- 创建一个 SessionMgr,并随后在这个 SessionMgr 中创建 WorkerSession
- 这里没有马上创建 MasterSession,而是保存好创建 MasterSession 所需要的信息(大概是因为 ps 中不需要 Master?而 Worker 是所有节点都要有的)
- 创建 LocalMaster
Work 类用于管理 WorkerSession、处理子图、运行子图、接收 Tensor 数据。GrpcWorker 继承了 Worker 类之后重载了其中的数据传输部分,添加的是一个额外的传输方法,用于在传输大数据时不经过 Protobuf 序列化而直接传(调用 send/recv op 的接口的话,应该是默认要序列化之后再传吧)。
GrpcWorkerService 重载的是 AsyncServiceInterface 这个类,AsyncServiceInterface 抽象的是一个异步等待服务,即创建一个新的线程,用 polling 循环来等待传入的 RPC 请求。
GrpcWorkerService 底层关联的是 WorkerService 这个通过 Protobuf 定义用于 RPC 的结构。
WorkerSession 相对而言反而是个比较简单的结构:
1 | // WorkerSession encapsulates all of the state relating to a given session. |
保存了名字啊、worker_cache啊、device_mgr啊、graph_mgr啊这样的内容。
GrpcSession
下一个断点首先是 GrpcSession 再被触发。
分布式环境下对应的 Session 结构为 Supervisor 中创建的managed_session(),对于 chief 节点,调用自己 SessionManager 中的 _restore_checkpoint() 来在 C 层面创建出 GrpcSession 结构,并且负责完成图的构建等等,之后检查本次运行是否有对应的检查点,有则把检查点的信息恢复出来。而非 chief 节点调用的是wait_for_session() ,创建 GrpcSession 之后等待 chief 节点完成图的构建。
GrpcSession 是从 Session 类继承出来的,其负责的任务跟单机版中的 DirectSession 很像,跟它是同一个层级的东西。
或者说 Session 类在整个 TensorFlow 架构中更确切的应该叫它 Client Session,它们与 Python 层的
sess = tf.Session()这种结构是直接对应的,是用户编程界面与 TF 运行时的入口。
但 DirectSession 发挥功能的函数都是在本身中直接定义出来的,而这里的 GrpcSession 却可以说基本上是围绕 MasterService 的封装。通过 MasterInterface 来调用 MasterService 的功能来完成任务,可以说 GrpcSession 只是最上图中架构中 client 与 Master 服务之间的接口。
这里的 Master 接口有两种,LocalMaster 用于进程间的直接通信,GrpcMaster 用于 Grpc 通信,GrpcSession 在创建时会根据选项选择所需的 MasterInterface。通常情况下,由于 GrpcSession 都是是直接跟本地的 Master 进行交互,所以默认添加的是 LocalMaster。
MasterSession
上面managed_session()在创建完 C 层面的 GrpcSession 返回之后,会很快执行一次 sess.run(),有检查点的情况是恢复检查点时的变量数据,没有检查点时是执行 init_op 来完成变量初始化。
这里执行的 sess.run()与单节点版本的行为相同,需要首先执行_extend_graph(),不同的是这里执行的是tensorflow::GrpcSession::Extend(),最终到tensorflow::LocalMaster::CreateSession()、tensorflow::Master::CreateSession()。
话说 TensorFlow 中跟 Master 这个概念相关的结构有一堆,一层套一层,而且功能上跟 Worker 又有很多区别的地方。类比起来,大概 MasterSession 也就是跟 Executor 比较像,每一次 Client Session 要 Run 一个子图时(sess.run(...)),启动一个 MasterSession。
MasterSession 追溯到最后是由 GrpcSession.Extend()、GrpcSession.Create()在构建运行图或者修改运行图的时候创建。调用栈大概是这个样子,层次看起来还是比较乱:
1 | tensorflow::GrpcSession::Create() -> |
注释中对 MasterSession 的介绍是:
- 负责分配 node 到 device
- 添加额外的边(例如 send/recv)
- 发射 commands 给 worker 来运行
具体来看,还是从sess.run()入手:
1 | tensorflow::GrpcSession::Run() -> |
最后的 ReffedClientGraph 是与计算图和 Worker 相关的内容了,具体的实现相当复杂,封装层次也是特别多,大致看了下RunPartitions()这里的注释:
- 匹配 fed tensors 和它们在 req 中的 index
- 给每个 partition 准备一个将发给 worker 的 call
- 通过
tensorflow::MasterSession::ReffedClientGraph::Part::worker(这是一个 WorkerInterface)的RunGraphAsync()方法,把运行的 call 提交给 worker 跑 - 等待 RunGraph 的 calls 返回结果
- 最后处理收到的运行结果
画张图稍微理一下上面这些结构的关系:

然后还有来自这里的一张图:
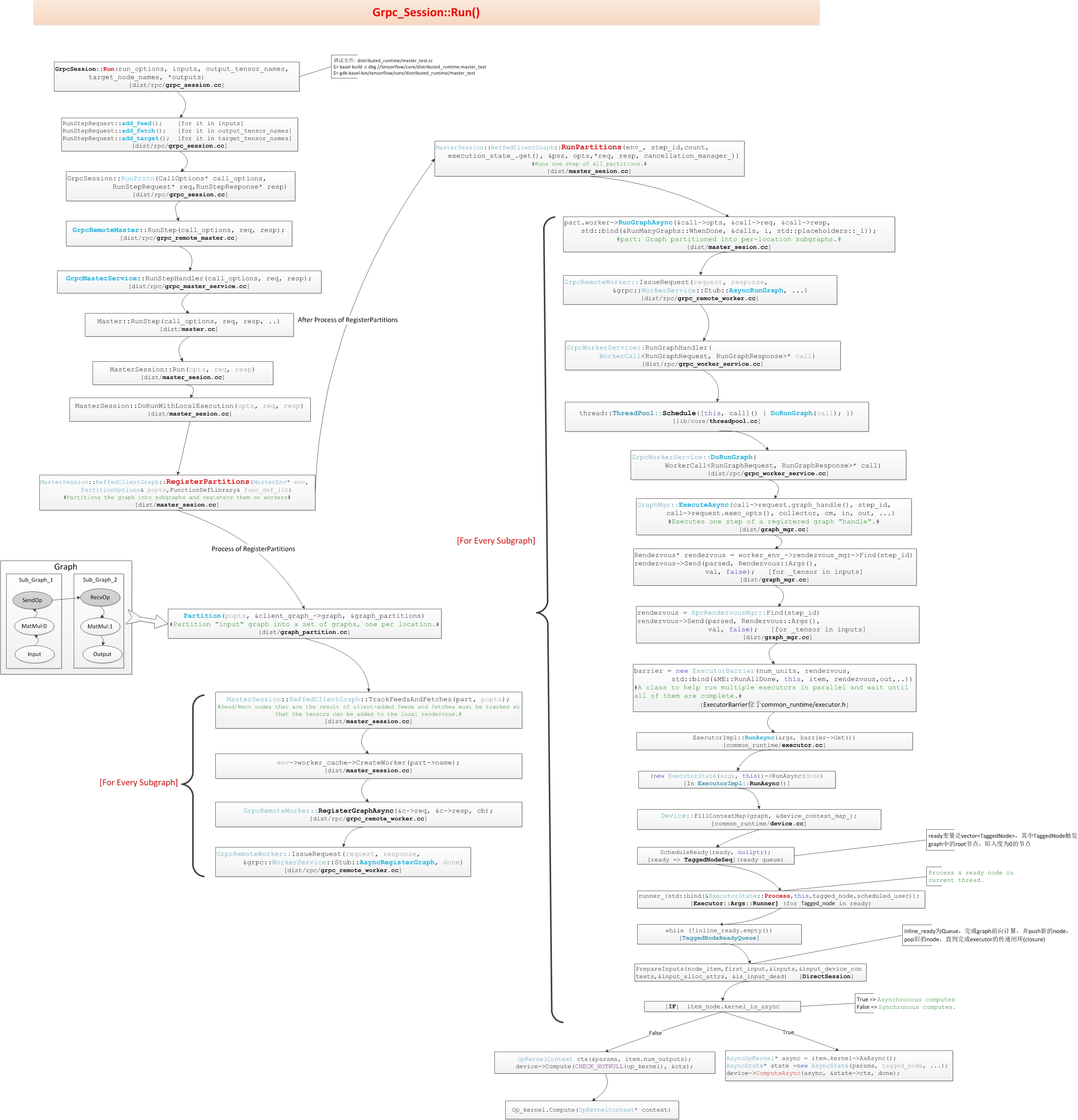
WorkerInterface
这两个类是作为 TensorFlow 运行时调用 gRPC 的接口基类。
从源码中可以看到,WorkerInterface 类定义了一堆诸如GetStatusAsync()、CreateWorkerSessionAsync()、DeleteWorkerSessionAsync()等等这样的虚函数接口,可以认为是跟 GrpcWorkerService 支持的 GrpcWorkerMethod 是一一对应的:
1 | // Names of worker methods. |
当然这个同时也是要跟 Protobuf 的配置要一一对应。
具体的实现在它的两个继承类 Worker 和 GrpcRemoteWorker 里面。
从代码上来看,GrpcRemoteWorker 类中的每一个函数都是调用 IssueRequest() 发起一个异步的 gRPC 调用,远程的 GrpcWorkerService 作为守护进程处理传入的 gRPC 请求。
Worker 类中的对应实现则都是直接在本地做。
Work Flow
最后回到前面的运行部分。
在tensorflow::MasterSession::ReffedClientGraph::RunPartitions()中,MasterSession 运行每一个已经划分好的 partitions 用的是 part.worker->RunGraphAsync() 调用。
part.worker 是每个 partitions 对应的 WorkerInterface 对象,很容易猜想到如果分配在远程对应的应该是 GrpcRemoteWorker 实例,否则对应的应该是 Worker 实例。
那再看数据收发部分的send/recv,之前已经知道了数据传输由recv部分发起,最终调的是RpcRemoteRendezvous::RecvFromRemoteAsync():
继续往下看,检查各项参数,准备 RpcRecvTensorCall,之后启动 call->Start(),Start()里面调的是StartRTCall():
1 | void StartRTCall(std::function<void()> recv_done) { |
wi_ 同样是一个 WorkerInterface 的结构。
这样就很清晰了,无论是 Master、Worker 相互之间的控制还是send/recv的数据传输都是通过 WorkerInterface 的派生类作为接口完成的,接口的另一头是底层的 gRPC 通信库。
那么再看到响应 gRPC 调用的那一边,在 GrpcWorkerService 创建时,守护进程HandleRPCsLoop()就启动了:
1 | void HandleRPCsLoop() { |
首先准备好一系列 gRPC 调用的等待队列,11 种调用请求与前面的 GrpcWorkerMethod 一一对应,插入完成之后就是 gRPC 部分的任务了。每个方法对应的处理过程的代码也都列在后面,随便挑一个举例:
1 | void GetStatusHandler( |
响应 gRPC 请求时这里把要做的任务都封装到线程池里面去执行,然后向队列中重新补充一个相同的等待调用。具体执行的是 worker_(其实是一个 GrpcWorker),完成后向调用方返回一个 gRPC 的 Response。
最后的一个 while 循环是读取 gRPC 完成队列中的内容,处理 gRPC 调用完成之后的收尾工作,RequestReceived、ResponseSent、Cancelled这三种状态。
话说这种完成队列的方式跟 RDMA 的还是挺像的。
MasterInterface
MasterInterface 的结构跟 WorkerInterface 基本类似,不过话说从代码上能看出来不像是一拨人做的啊(命名风格等等),很奇怪。
支持的一些调用:
1 | static const char* grpcMasterService_method_names[] = { |
它所派生出来的两个类 GrpcRemoteMaster 和 LocalMaster 从名字上就能够看出来是分别针对远程和本地的调用接口。
乍一看 GrpcRemoteWorker 和 GrpcRemoteMaster 实现远程调用的写法居然完全不一样,很尴尬。仔细往下分析会发现 GrpcRemoteWorker 的 IssueRequest 里面封装的 RPCState 里面的内容跟 GrpcRemoteMaster 的 Call 中的内容很类似。所以为什么不用统一的写法呢。。。
然后 LocalMaster 这个类竟然只是个壳你敢信?。。。里面真正实现本地功能的是 Master 类。
话说前面 Worker 这个类实现的是本地功能,但是 Worker 类是直接继承的 WorkerInterface,到了这里 Master 类跟 MasterInterface 类没有关系,继承 MasterInterface 的是 LocalMaster 类,但是你又发现这个 LocalMaster 类居然是 Master 类的壳。。。相当于跟 Worker 差不多的结构,但是中间多包了一层。
再来看到 GrpcMasterService 的守护进程:
1 | void HandleRPCsLoop() override { |
基本的结构跟前面 Worker 是一致的。
Worker 的远程调用实际发生在:
- 本地 Master 处理好计算图的 partition 情况
- 根据 partition 是在本地还是远端,分别请求本地 Worker 或者 GrpcRemoteWorker 来执行
- 远程的 GrpcWorkerService 守护进程收到请求之后,调用自己本地的 Worker 进行处理,完成后将结果返回
话说 GrpcRemoteMaster 我还没找到到底是在什么情况下用到的。
后续: