重新理了一下,把内容分开,其实大部分内容都是以前记的,接上篇:
本篇为第四、五章开始。
CHAPTER 4. The Processor
从这一章开始就是讲处理器里面的设计了,还是以 MIPS 为例展开。
4.1. Instruction
指令实现 overview:
- 首先所有指令都存在内存里面,向内存发送 PC(program counter)来获取(fetch)下一条指令
- 根据指令具体要做的事情,读取一个或者两个寄存器的数据。
前面两步是所有指令都要做的,再之后就是根据指令做具体的操作了。
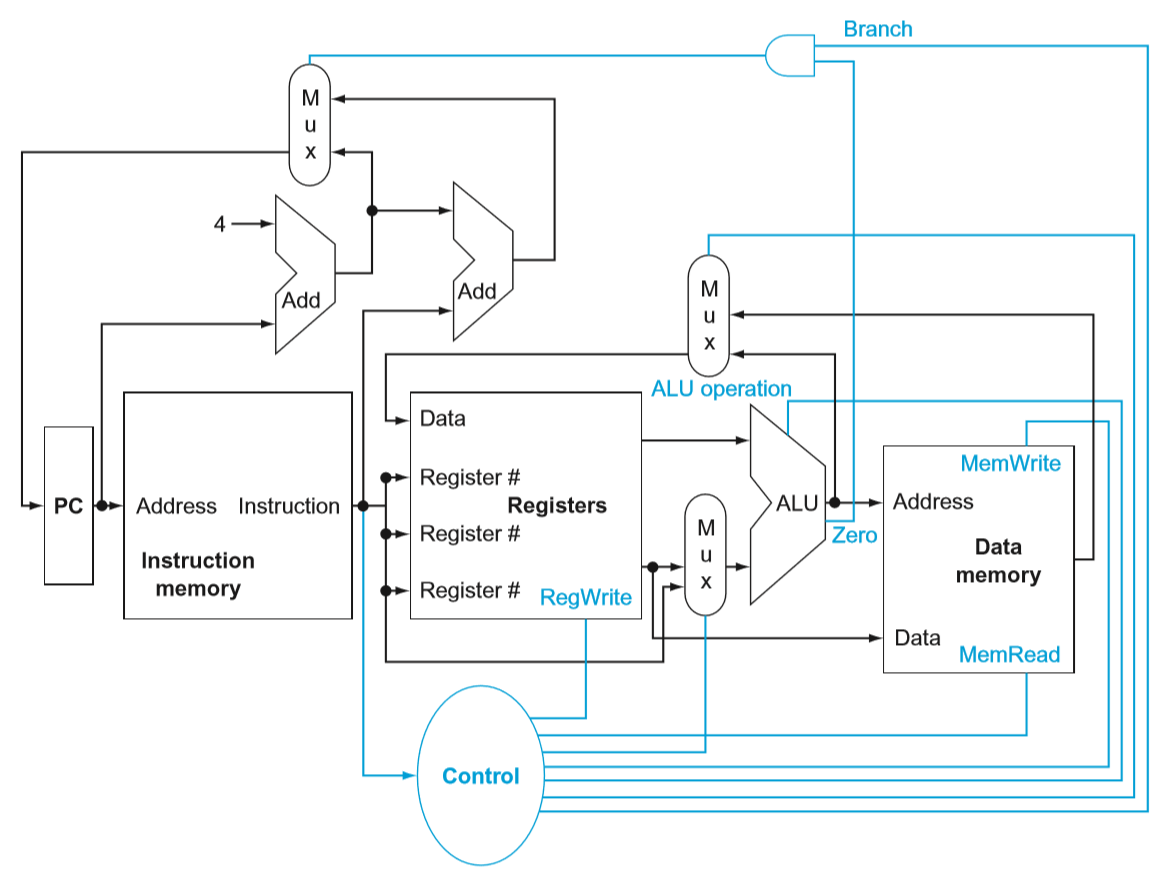
4.2. Logic Design Conventions
这里把 MIPS 实现的数据通路上的逻辑元素分成两类:结合性元素(combinational element)和状态元素(state element)。
结合性元素指的是执行操作的元素,输出只与输入有关,任何时候,只要给一样的输入,就会有一样的输出结果,例如 ALU。
另外一些元素不是结合性的,而是可能包含运行状态,即带有内部存储结构,例如指令存储器、寄存器等。
触发电平用于控制各个元素的执行。这里假定都用边沿触发。
4.3. Building a Datapath
数据通路的具体实现,首先是处理指令需要的几个基本元素:
- 指令存储器
用于存储所有的程序指令,并且给它们编上地址 - PC
一个地址寄存器,用于存放指令地址,即指向指令存储器中当前正在执行的指令 - 加法器
用于改变PC的值,指向下一条指令,以使程序可以继续向后执行
对于寄存器的操作:
- 读寄存器
输入1个寄存器号,输出该寄存器的内容。可随时读取。 - 写寄存器
输入1个寄存器号,以及要写入写寄存器的值。需要给寄存器文件一个写信号才能写入。
以R-format指令为例:
一般需要读取2个寄存器的内容,经过ALU运算,写入另一个寄存器。
结合上面的寄存器操作,则寄存器访问需要4个输入(2个要读的寄存器号,1个要写的寄存器号,1个要写入的寄存器值),2个输出(分别是输出2个要读的寄存器的内容),以及一个写信号脉冲。
寄存器号的3个口需要5位的数据宽度(第二章中rs、rt、rd的长度都是5位),写入与读出的3个口则分别需要32位的数据宽度。
再看I-format指令:lw $t1,offset($t2)
存储地址是将$t2中的内容(32位基地址)加上offset(16位偏移地址)作为目标地址,然后将内容写入寄存器$t1。
这里需要的是一个地址加法器(加16位和32位的数)以及数据存储器。beq $t1,$t2,offset
首先读取$t1和$t2的内容到ALU进行对比,若通过,则将offset(16位偏移地址)加到PC上作为下一次的目标地址。
需要注意的是:lw中目标地址是直接把offset和$2中的内容相加,而beq中offset指的是按4字节寻址的地址,PC中存的是完整的地址,offset要作2位偏移之后再加到PC中去
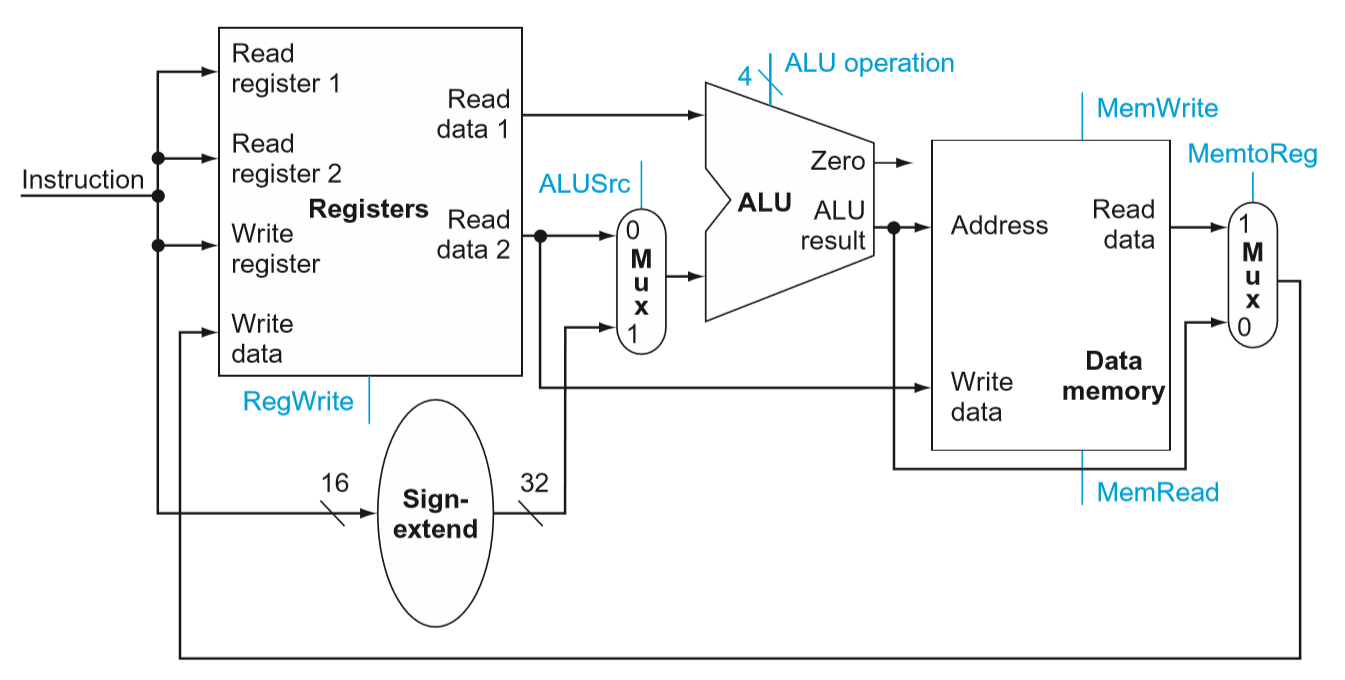
上图中进行R-format指令操作时:
多路选择器ALUSrc选0,输入两个寄存器的内容到ALU中;多路选择器MemtoReg选0,将运算结果输出至寄存器文件的写入数据端,写入寄存器。
进行I-format指令操作时:
多路选择器ALUSrc选1,输入一个寄存器的内容以及将offset从16位符号扩展至32位之后的值到ALU中;多路选择器MemtoReg选1,将数据存储器中读到的内容输出至寄存器文件的写入数据端,写入寄存器。
在上图的基础上把PC以及指令寄存器的内容加上去就是一个比较完整的数据通路了。
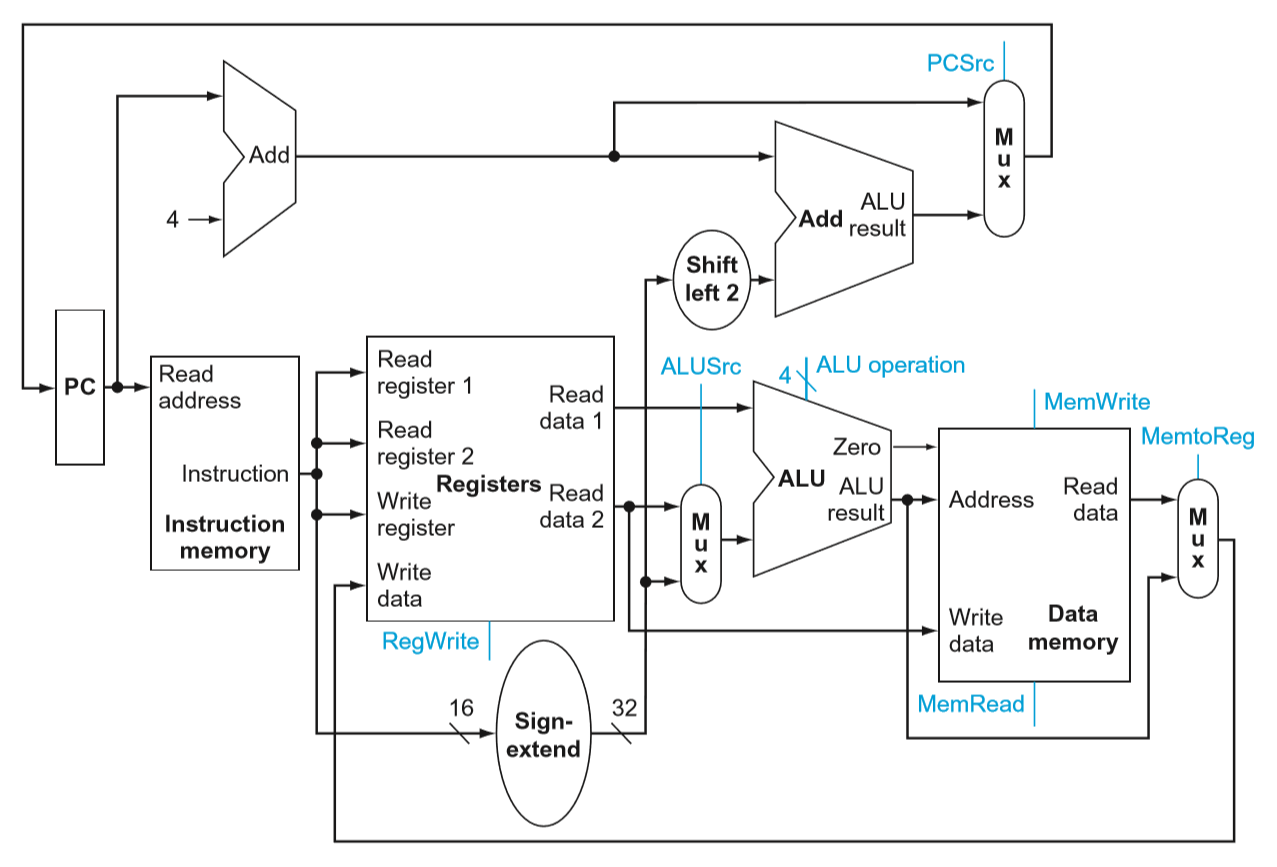
PC后的两个加法器用于改变PC的地址。将offset从16位符号扩展至32位之后的值作2位左移与地址累加是完成beq这一类的跳转,用PCSrc进行数据选择。
4.4. A Simple Implementation Scheme
然后来模拟实现一个简单的的指令集,包含:
- load word (lw)
- store word (sw)
- branch equal (beq)
- 算数逻辑运算:add, sub, AND, OR
- set on less than
要实现上面的这些功能,操作数只需要2位:
- 00表示lw或者sw,这里对于ALU来说只需要作地址的相加即可。
- 01表示beq,需要用ALU对两个寄存器相减。
- 10表示R-format操作,需要配合6位的Funct再进行各种情况的选择。
- 根据上述的2位ALUOp和6位Funct,生成出真正的4位ALU操作码
结合第二章表格里面每一种类型的指令的格式,再加上控制单元部分,可以把数据通路图进一步画成:

多路选择器RegDst用于区分R-format和I-format中目标寄存器在操作数中的位置(rt在20:16,rd在15:11)
单独有一个ALUOp用来根据最后的Funct(5:0)来产生真正的ALU控制码,这里其实只是一个真值表的处理。
指令的31:26位用一个单独的控制器处理,来完成各种控制信号的产生。

跳转的指令是6位操作数和26位地址,这个地址也是按4字节寻址的。
则加上跳转就是将原来PC+4的高4位,以及26位地址偏移2位组成新的PC地址,完成跳转。
至此,单指令周期的数据通路构造完成。
而由于指令数的庞大,单周期指令实际运行时非常慢,必须等到一条指令运行完毕之后才能跑下一条,而每一条指令其实只占用了数据通路的一部分(这里只是实现了几条简单的指令集,完整的可以想象是更加庞大的),剩下的部分都是空闲没用的。
因此要用到下一节之后的流水线技术来处理这个矛盾。
4.5. An Overview of Pipelining
流水线思想是为了提高吞吐量,其实最简单的理解就是把每个不同部分错开同时执行,其本身并不能提升单个指令的执行速度,但是当指令数量达到一定量级,且每级流水线的工作时间设置的比较合适时,使用流水线比不使用流水线要快大约流水线级数倍。
处理1条 MIPS 指令包含5个步骤:
- 从指令存储器中读取指令(Instruction Fetch)
- 指令译码,并且同时读取寄存器的内容(Instruction Decode)
- 执行操作或者计算地址(Execute)
- 从数据存储器中读取操作数(Memory Access)
- 将结果写回寄存器(Write Back)
本章讨论的流水线也是分成5个部分。
当然,前面说的能加速流水线级数倍的前提是所有指令都能够用流水的方式执行,事实上在实际情况下这是有问题的,下一条指令可能需要依赖于上一条执行完毕之后才能执行,这里就有个流水线冒险的问题:
结构冒险:由于硬件结构导致的冒险,两条指令没办法同时使用一块相同的硬件,比如两条指令在不同的阶段需要同时访问相同的寄存器。
这个需要从硬件结构上来解决。
数据冒险:下一条指令需要的数据,上一条指令还在计算中。
例如这两条指令按顺序进入流水线时:
1
2add $s0, $t0, $t1
sub $t2, $s0, $t3当
sub指令需要读取$s0的数据时,add只执行到第三个阶段,还要等到第五个阶段才能把结果写回到$s0中去。数据冒险是特别常见的情况,编译器可以通过改变指令顺序处理掉一部分的数据冒险,另外的就需要通过增加额外的硬件结构来完成转发(forward)和旁路(bypass)。
转发指的是下一条指令读取寄存器数据时直接把上一条 ALU 计算的结果拿过来。
 对于某些特别的指令,比如读取数据,就需要给流水线暂停一个时钟周期再转发,相当于插入一条气泡指令。
对于某些特别的指令,比如读取数据,就需要给流水线暂停一个时钟周期再转发,相当于插入一条气泡指令。
 可以通过指令重排,往气泡的位置插入一条跟这两条无依赖关系的指令来避免浪费。
可以通过指令重排,往气泡的位置插入一条跟这两条无依赖关系的指令来避免浪费。控制冒险/分支冒险:遇到例如beq这类指令时,指令正在译码,但是流水线就要紧接着读入下一条指令,而此时下一条指令的PC还没有确定,因此产生矛盾。
比较简单的解决方案是随便预测一个方向先执行,如果不对再忽略前面执行的指令转去执行正确的指令,这样如果预测是正确的,则流水线任然是全速运行,如果是错误的那么与原来不采用预测的方式耗时一样。使用额外的硬件预测器可以把准确率提高到90%以上。另外在MIPS中还有一种方案是将一条不影响分支的指令放到分支之后。
 对于某些特别的指令,比如读取数据,就需要给流水线暂停一个时钟周期再转发,相当于插入一条气泡指令。
对于某些特别的指令,比如读取数据,就需要给流水线暂停一个时钟周期再转发,相当于插入一条气泡指令。
 可以通过指令重排,往气泡的位置插入一条跟这两条无依赖关系的指令来避免浪费。
可以通过指令重排,往气泡的位置插入一条跟这两条无依赖关系的指令来避免浪费。4.6. Pipelined Datapath and Control
流水线中的数据通路和控制

- IF:Instruction fetch
指令预取 - ID:Instruction decode and register file read
指令译码并读取寄存器 - EX:Execution or address calculation
执行指令或者计算地址 - MEM:Data memory access
访问数据存储器 - WB:Write back
寄存器回写
数据流是从数据通路的左端开始,一直向右进行。图中仅有的两条反向流动通路是PC和寄存器的回写,这两个反向流也就是后面需要解决冒险的地方。
为了使得一个数据通路里面的五个部分之间相互不影响,解决方法就是在两个相邻的部分之间使用额外的寄存器来传递数据,保证上一条指令的结果能够保存下来传给下一个部分来执行,同时能继续执行下一条指令的该部分。

考虑一条lw $dest, offset($addr)指令:
- IF:根据 PC 的值,从指令存储器中获取到这条指令,存到 IF/ID 寄存器中。PC 自增 4 并写回,等待下一个时钟周期来读下一条指令,同时这个时候的 PC 值也存到 IF/ID 寄存器中,以备以后使用。
- ID:分拆指令的各个部分,读寄存器,把读到的寄存器值(这里只有一个)以及 32 位扩展后的偏移值存入 ID/EX,自增过的 PC 也存入 ID/EX。
- EX:把 32 位扩展值以及寄存器 1 的内容用 ALU 加起来,就是需要访问的最终目标地址,算出目标地址之后存入 EX/MEM。
- MEM:用目标地址去访问内存,把读到的数据存入 MEM/WB。
- WB:把读到的数据写回到寄存器中。
分析完 lw 和 sw 中数据流动的特点之后会发现,这里可能会存在一个 bug:即写寄存器这一步发生在整个数据流的最后一步,要写入寄存器的内容和要写的寄存器号其实都是在最后一步 WB 中给出的。
因此在第二步 ID 中得到的要写的寄存器号在这一步中没有用到,而是需要随着整个数据通路一直向后传递,直到最后一步,然后传回来。
上图中蓝色的线就是对这个问题的修改。
这里先不考虑发生冒险的情况,以下面这段程序为例:
1 | lw $10,20($1) |
运行过程中流水线中的内容:

把上图中第五个时钟周期中每个部分执行的内容连起来看:

流水线每一级能够独立工作就是完全靠了每一级之间的这些流水线寄存器。
控制部分与前面的单周期数据通路类似,这里主要强调控制指令也是逐级往后传递,在本级没有用到的控制字直接传递给下一级的状态寄存器,给数据通路中的每一个组件加上控制信号等等即可。

4.7. Data Hazards: Forwarding versus Stalling
然后来看看数据冒险的解决。
以下面这段代码为例:
1 | sub $2, $1,$3 |
将上述代码画在图中即:

后面四条指令均用到了第一条指令的结果:
其中第二条$2作为rs,第三条作为rt,第一条的结果还没来得及写入寄存器即马上要被调用,发生数据冒险
虽然第三条的读取寄存器与第一条的写入寄存器发生在同一个时钟周期内,但是可以认为写入发生在前半个时钟周期内,读取发生在后半个时钟周期内,无冲突
第四条读取寄存器时,数据已完成写入寄存器,无冲突
这里的解决方案是作数据转发,上图是从寄存器角度来看这个过程,如果从状态寄存器上看:

第二条指令的ALU需要输入时实际上答案已经算出来了,存在第一条的EX/MEM状态寄存器中,只要作一下转发即可避免冲突的产生。
转发这个操作从图上很好理解,但是发生在一个流水线通路中,那么从硬件实现上面就是增加多路选择器以及额外的控制模块(Forwarding Unit)来实现:

但是,另外仍然有一个无法用转发避免的数据冒险,发生在 lw 这样读取数据存储器的指令后:

这里正确的结果出现在MEM/WB状态寄存器中,解决方案只有将后面的指令作一个时钟周期的延时,以完成转发:

“气泡指令”即输入一条空指令,将所有控制状态字都置为0,则整个数据通路中状态寄存器不发生改变,相当于保持原状延时1个时钟周期。
4.8. Control Hazards
接下来来看一下控制冒险的问题。
碰到条件跳转等等情况,我们根本确定不了下一条指令是什么,那要怎么往流水线里面放指令呢?答案就是先默认选一条(比如默认先不跳转,直接把下一条指令放进来),然后把本来要在 EXE 级完成的比较计算提前。
通过增加额外的硬件,可以把 beq 判断的结果和转移地址的计算都控制在 ID 级完成,并默认先顺序读取下一条指令。当结果判断完毕时,转移的地址也同时被计算出来了。若分支未发生,则不需要改变,流水线任然可以看做是全速运行的;若分支发生,则因为此时是在 ID 级结束,只需要在给 IF/ID 一个 IF.Flush 信号删掉之前读入的指令,并读入正确的指令即可,相当于一次“气泡”延时。
另外考虑到 beq 指令之前,还可能出现数据冒险的情况:
若 beq 前为 add、sub 这类的计算执行指令,结果将在 EX 级之后被计算得到,则需要将 beq 指令延迟一个时钟周期,等待数据转发;
若 beq 前为 lw 这类的数据存储指令,结果将在 MEM 级之后得到,需要将 beq 指令延迟两个时钟周期,等待数据转发。
比默认选择一条路径更优的是利用“历史记录”等等进行动态对分支方向进行选择。
分支预测和指令预取这块深入下去还有很多人研究,也是一个很大的研究点,貌似这几年已经能达到80~90%的准确率了。

4.9. Exceptions
最影响流水线性能的是异常和中断,因为这类情况的发生是不可预知的,而发生时则需要暂停当前正在运行的程序,跳转执行至异常处理程序中。
在MIPS异常发生时,需要保存下当前的指令地址 EPC 以及错误发生的原因 Cause。
到这里为止,基本上完整的流水线数据通路已经完成了:
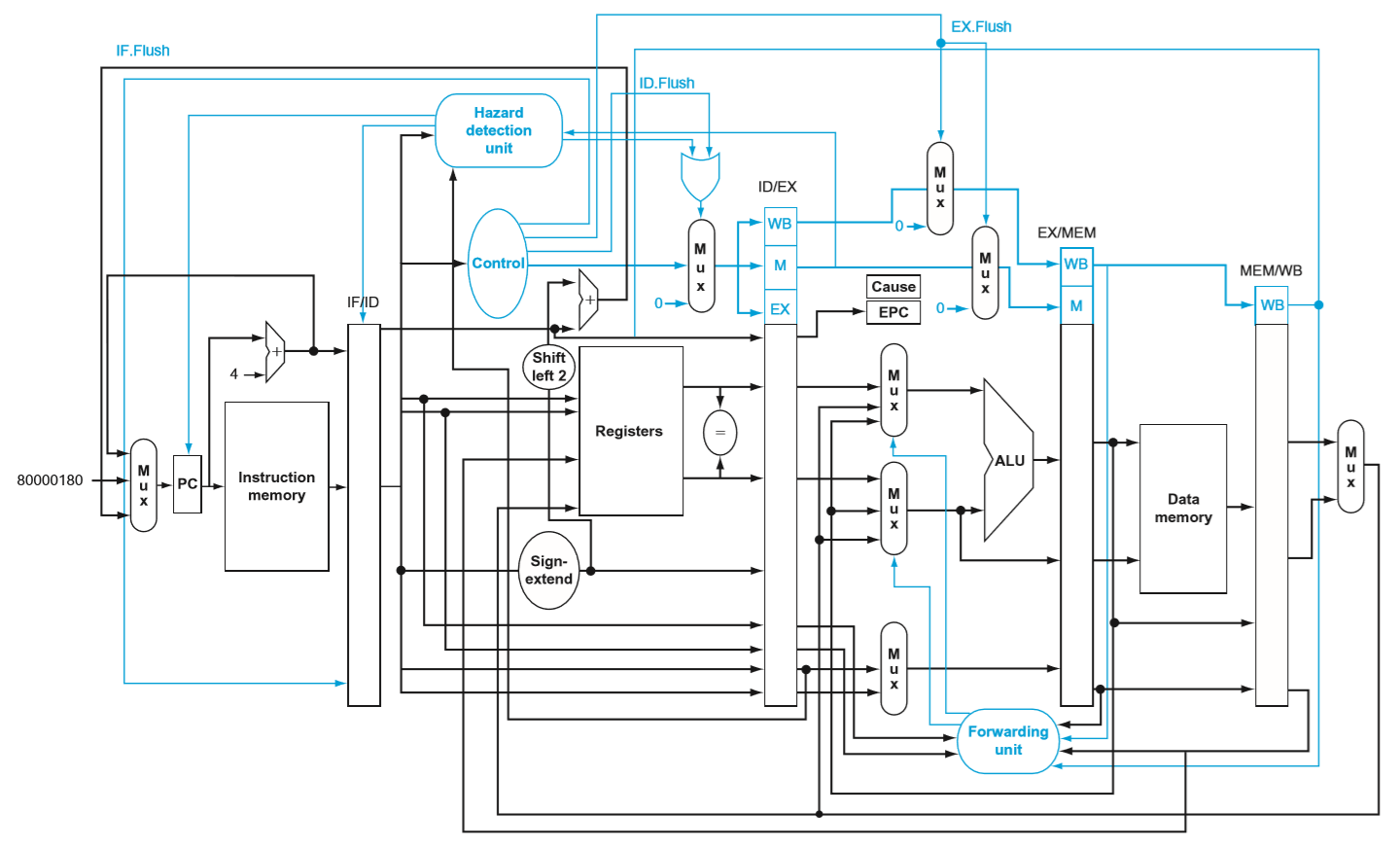
4.10. Parallelism via Instructions
流水线技术其实表现的是计算机执行指令时的并行潜力,这里有个专门的词就叫指令级并行(ILP,Instruction Level Parallelism)。
本书中关于指令级并行的内容只有13页,基本上只是个概览,关于详细的要去看《量化分析方法》。
大汗……把这里的 13 页扩展到 200 多页。
进一步增强流水线的潜力一般有两种思路:
- 增加流水线的深度,这样流水线中就能够同时容纳更多的指令。当然,要修改流水线级数还需要考虑到重新把每一级的执行时间调整到差不多相同的程度(作为一个时钟周期);
- 复制流水线中每一级的部件,让流水线在相同的周期内能同时运行多条指令(也是一种解决结构冒险的思路),这个通常叫做指令多发射,也即单周期多指令并行。
第一章中提到过 CPI 这个概念,如果单个时钟周期内可以处理多条指令,那么 CPI 的值就能做到小于 1,或者要改用 IPC(Instruction per clock cycle)来做性能指标了。工艺上提升主频,再从设计上提高 IPC,那么一个 4 GHz 的 4 路多发射处理器就能每秒处理 16 G 条指令。
然鹅理想很美好,要做到指令的多发射虽然能够显著地提升速度,但是随之而来的也有很多的问题:
- 怎么同时跑多条指令?这里有个发射槽的概念,那么就是说如何合理地将指令分配到不同的发射槽中,使得指令能够做到多发射?有多少条指令,哪些指令可以在一个指令周期内一起发射?
- 指令多发射之后,数据冒险与控制冒险的情况就更为严重了。
第一个问题的解决方案基本上还是要靠前面的分支预测技术,只不过要考虑的方面要更复杂了,单独有个单词来特指这个部分的工作:推测(Speculation)。
多发射通常采用两种思路:
静态多发射:简单地说就是将前几节的数据通路作进一步拓展,每一级流水线中都有多套设备,或者干脆就是把一条数据通路复制几份,这样就能一次读取多条指令,一次同时执行多条指令了。主要依靠编译器来帮助把指令打包在一起以及处理各种冒险,编译器需要针对特定结构的CPU作优化,如果要移植到不同的设备上,需要作重新编译。这种思路最开始的实现叫超长指令字(VLIW),即这种实现结构中指令特别长,单条指令中有多个操作数,定义了一组相互独立的操作。
为了保证高效,就需要尽可能地让每条流水线都跑满,这个想想就是一个特别复杂的问题。
动态多发射,又叫超标量(Superscalar):扩展了基本的多发射思路,在编译器排好指令顺序之后,处理器按顺序读取指令,然后由处理器来决定能不能同时发射多条指令进去跑,核心是要依靠动态流水线调度技术,流水线结构相对前面几节的数据通路来说应该已经完全改变了。程序经编译器优化后得到的代码应该始终是正确的,编好的代码放到不同结构的超标量处理器里面都应该能够得到相同的结果。
超标量流水线的结构已经不同于前面的简单数据通路了,而是分成了 3 个部分,一个指令发射单元,多个功能单元,一个提交单元,顺序发射指令,乱序执行指令, 最后顺序提交指令:
每个功能单元里面都有个保留站(Reservation Station)用于存储当前指令的操作数和操作码,只要功能单元硬件就绪,并且所有操作数就绪,它就可以执行了,当计算已经执行完毕,结果就会被马上转发到其他正在等待的保留站,同时存入提交单元的重排缓存(Reorder Buffer)中,经过提交后写入寄存器或者存储进内存等等。
- 发射单元按顺序取指令并译码,将操作码、操作数发送给合适的功能单元去执行,存入对应功能单元的保留站,任何在寄存器或者重排缓存中就绪的数据也会直接被拷贝进来。一旦指令被发射出去,数据完成了到保留站的拷贝,则原寄存器的数据锁定也可以解除了,若此时有写寄存器的操作发生,可以直接覆盖,因为正确的内容已经被功能单元保存下来了;
- 若保留站中的数据没有准备好,则该单元需要等待至数据就绪(数据完成转发)之后再进行计算。
这个地方的处理思路,就是数据流啊!!!
为了使整个过程看上去像是与顺序流水线一样,取指与提交都要是顺序的:取指和译码单元顺序发射指令,并同时记录程序中的依赖关系。而提交单元也需要按照顺序将结果写回寄存器和存储器。当异常发生时,处理器可以找到最后执行的那一条指令。
4.11. Real Stuff: The ARM Cortex-A8 and Intel Core i7 Pipelines
这里简单介绍了 ARM Cortex-A8 和 Intel Core i7 920 这两块现代处理器的流水线结构。
| Processor | ARM A8 | Intel Core i7 920 |
|---|---|---|
| TDP( Thermal design power) | 2W | 130W |
| Clock rate | 1GHz | 2.66GHz |
| Cores/Chip | 1 | 4 |
| Floating Point? | No | Yes |
| Multiple Issue? | Dynamic | Dynamic |
| Peak instructions/clock cycle( IPC) | 2 | 4 |
| Pipeline Stages | 14 | 14 |
| Pipeline schedule | Static In-order | Dynamic Out-of-order with Speculation |
| Branch prediction | 2-level | 2-level |
| 1st level caches/core | 32KB I, 32 KB D | 32 KB I, 32 KB D |
| 2nd level caches/core | 128 - 1024 KB | 256 KB |
| 3rd level cache(shared) | - | 2 - 8 MB |
ARM A8 的流水线是动态多发射,但是静态顺序运行,其 14 级流水线结构如下:
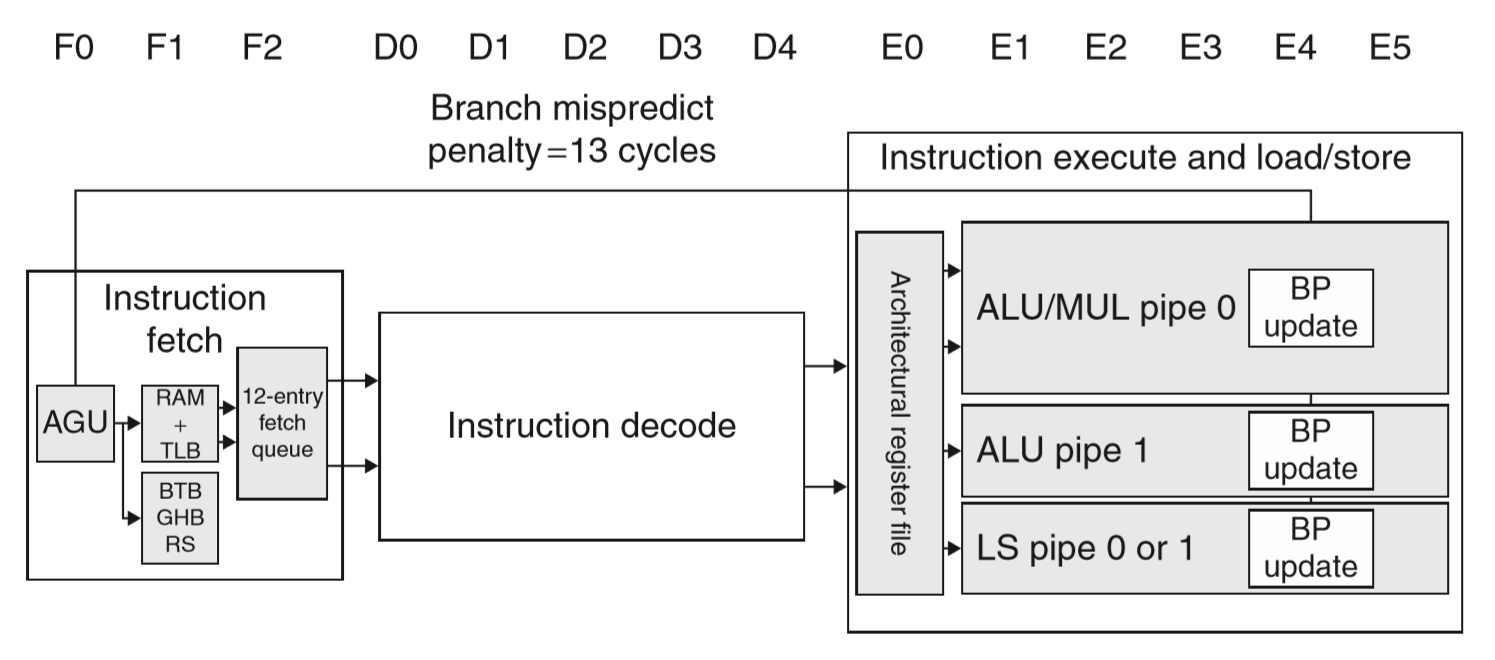
- 前三级能同时取出 2 条指令,并维护一个 12 条指令的预取缓存。两级分支预测,但是没有在这里做额外的预测判断,所以如果预测错了就要等 13 个时钟周期之后才能知道。
- 接下来是把一对(2条指令)进行五级指令译码,这里也负责判断数据依赖等等。
- 之后是六级指令运行流水线。
SPEC2000 测试集跑下来的结果是,CPI 最好的情况 1.4,最差 5.2,跟理想的 0.5 还是有一定差距的。平均情况 80% 的停顿是源于流水线冒险(分支预测错了、结构冒险、数据依赖)。这种流水线结构基本上是要完全依靠编译器的指令重排来解决结构冒险和数据依赖的问题。
x86 处理器的流水线结构就要复杂多了:
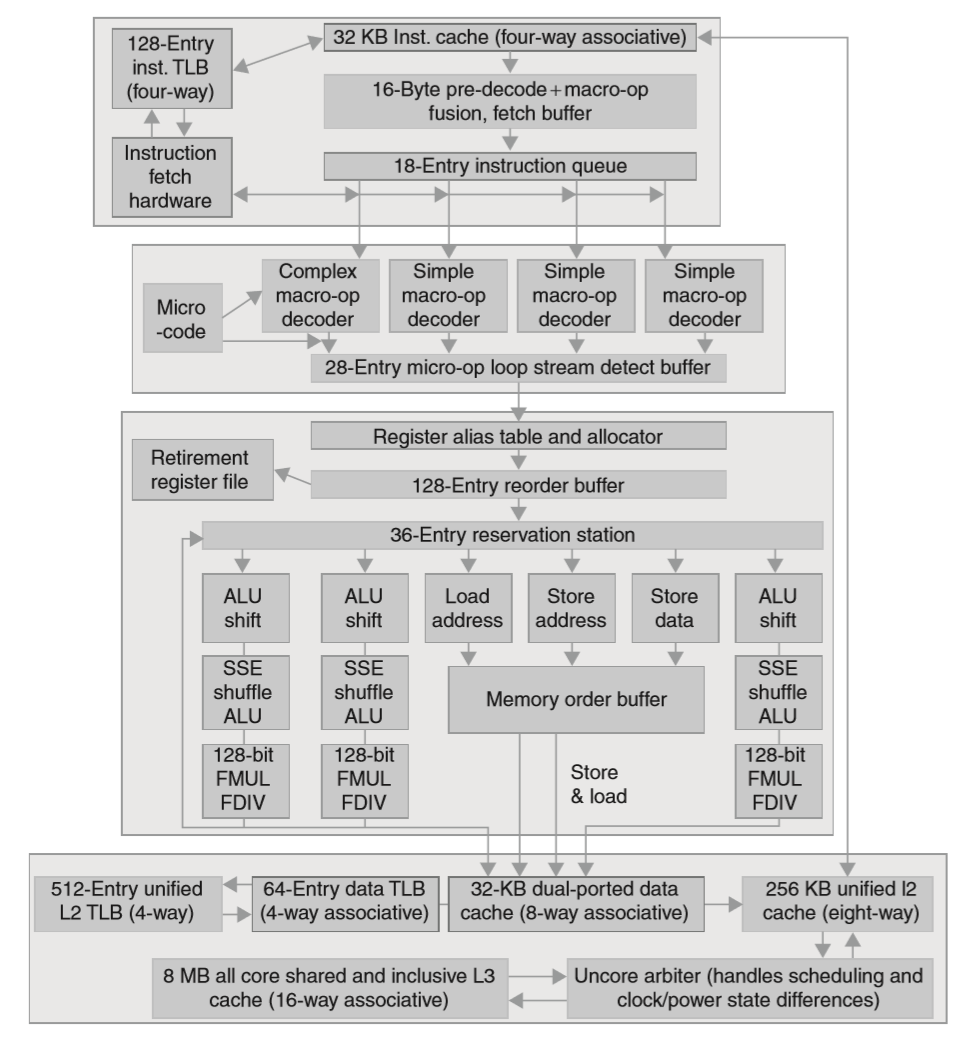
x86 是一种复杂指令集,一条指令在译码的时候会先转换成一种类 MIPS 结构的指令(微操作,micro-operations)。配合动态多发射,动态调度,乱序执行,分支预测等等,最高可以达到单指令周期 6 个微操作的速度。
- 指令读取:多级分支预测、涉及 cache 等等一堆复杂的部分,最终从指令 cache 中得到 16 个字节的指令数据。预测错误需要浪费大约 15 个指令周期。
- 指令预译码:16 个字节的指令数据预译码后变成微操作码(micro-op code),放入指令队列。
- 微操作译码:由于 x86 指令集的复杂性,这里还分不同的微操作译码器,译码完成后按照原本指令的顺序放入微操作 buffer。
- 循环流检测:如果找到了特定条件的一系列循环操作,就能直接发射这些微操作了,而不必再经过指令读取和指令译码(???)。
- 开始进行基本的指令发射:在寄存器表中查找寄存器位置、寄存器重命名、分配重排缓存入口、从寄存器或者重排缓存中提取结果等等。
- 保留站发送操作给功能单元进行执行,6个功能单元最多同时支持6个操作的执行。
- 功能单元执行操作,把计算完的结果转发给其他要用的保留站,同时发给寄存器回收单元来更新寄存器。重排缓存中的对应内容标记成完成。
- 当重排缓存中的一条或多条指令标记为已完成,则可以执行寄存器更新等等操作了。
4.12. Going Faster: Instruction-Level Parallelism and Matrix Multiply
循环展开加上AVX指令的SIMD,直接把性能提高了 8.8 倍。
6666666666666
4.13. Advanced Topic: An Introduction to Digital Design Using a Hardware Design Language to Describe and Model a Pipeline and More Pipelining Illustrations
提升主题:介绍如何使用一种硬件设计语言来描述和模拟流水线
4.14. Fallacies and Pitfalls
谬误:流水线很简单
呵呵。。。动态多发射乱序执行的这个想想就可怕,看了 i7 的流水线结构就知道这玩意有多复杂了。
谬误:流水线思想可以与工艺无关
陷阱:没有考虑到指令集的设计会反过来影响流水线
4.15. CondudingRemarks
4.16. Historical Perspective and Further Reading
4.17. Exercises
CHAPTER 5. Large and Fast: Exploiting Memory Hierarchy
这章的内容主要是存储器结构层次,大部分篇幅在 cache 上。
5.1. Introduction

越靠近CPU,速度越快,容量越小,价格越高。
越远离CPU,速度越慢,容量越大,价格越低。
5.2. Memory Technologies
一般常见的几种存储器技术:
|存储器技术|典型访问时间|价格/GB|特点|
|-|-|
|SRAM半导体存储器|0.52.5 ns|$5001000|数据用晶体管存储,可直接读取数据|
|DRAM半导体存储器|5070 ns|$1020|数据用电容存储,会不断漏电,需要定期刷新(充电)|
|FLASH半导体存储器|5,00050,000 ns|$0.751.00|EEPROM,电擦除可编程存储器,有读写次数上限|
|磁性硬盘|5,000,00020,000,000 ns|$0.050.10|用磁盘、磁头等进行磁性存储和读写|
5.3. The Basics of Caches
Cache是CPU直接用来进行读取的存储器,在第四章的数据通路部分没有指明的是,指令和数据都必须要到了Cache中才能够被CPU访问。

- 整个Cache区域分成多个条目,每个条目的存储结构由3部分组成:本条是否有效、条目标签以及数据块内容
- 低位地址作为Cache索引条目的索引地址,高位地址作为一条Cache内容的标签号,用Valid标识该条目是否有效,最后将连续的多个字节内容存入Cache数据块中
- 查找内容时,首先根据地位地址找到索引条目,对比该条的标签与高位地址一致并且条目为有效则访问命中,可以直接读取数据块内容给CPU;若没有命中,则要将数据请求下放一级,并从下一级获取数据到该级,然后返回数据给CPU,在取数据到Cache的过程中,CPU需要等待数据到位
若缓存Cache块中同时存放了多个字的数据,则可以进一步加一个多路选择器来解决:

正如上面所介绍的,读取数据时CPU首先从Cache中找数据,若未命中,则要多花时间先从下一级提取内容至Cache中,这里就造成了Cache延时;
而写入数据时,也会发生冲突:需要考虑用写直达法,同时更新Cache与下一级存储器中的内容,或者写回法,先写到Cache,当该块Cache需要被替换时再写回存储器。
5.4. Measuring and Improving Cache Performance
- 首先是评估Cache的性能
第一章中的CPU时间可以作进一步的划分:
$$CPU时间=(CPU执行时钟周期数+存储器阻塞时钟周期数)*时钟周期时间$$
阻塞时间:
$$存储器阻塞时钟周期数=读取阻塞周期数+写入阻塞周期数$$
$$读取阻塞周期数=\frac{读取次数}{程序数}*读取缺失率*读取缺失延时$$
$$写入阻塞周期数=\frac{写入次数}{程序数}*写入缺失率*写入缺失延时+写缓冲区延时$$
将写入与读取统一为存储器操作,则:
$$\begin{align}存储器阻塞时钟周期数&=\frac{存储器操作数}{程序数}*缺失率*缺失延时\&=\frac{指令数}{程序数}*\frac{缺失数}{指令}*缺失延时\end{align}$$
Cache的缺失和阻塞是不可能避免的,而经过简单的计算分析,可以发现Cache的阻塞延时对整体运行时间的影响甚至超过了CPI对运行时间的影响!即如果只是单纯地提高CPU的速度,而存储器的速度没有跟上的话,整体性能的流失会更加严重。
另外一个比较重要的因素与Cache的大小有关:一味地加大Cache的大小也是没有用的,Cache越大则访问Cache本身的时间将会延长。
资料:
将访问Cache的时间和Cache命中情况综合考虑,得出一个平均存储器访问时间(Average Memory Access Time):
$$AMAT=命中时间(访问Cache的时间)+缺失率*缺失延时$$
- 通过更灵活地调整Cache的结构,改变关联度来减少缺失率
5.3节中介绍的Cache结构是直接匹配的方式,虽然存放和查找非常方便,但是存在的问题是出现多个具有相同Cache索引的地址的反复调用时,就需要反复覆盖同一条索引记录,而每一次的访问都会是Cache缺失的
全相联方式:任意的地址都能任意存在Cache的任意一条索引上…这个,每次查找的时候就需要把整个Cache遍历一遍…想想都慢,虽然多加几个判断硬件可以做成并行的,但是成本也加大了。适用于Cache很小的时候。
折中的办法是组相联方式:首先还是按照直接匹配的方式计算索引号,然后就是一条索引号对应一个集合中的几个数据块,这样可以同时存放索引相同的几个不同地址的记录。
然而整个Cache的物理大小是固定的,增加组数,就是减少了索引数。需要在缺失率和命中时间之间平衡考虑。

在组联合结构中,为了使一条索引中的每块数据同时判断(并行判断),增加一些比较器即可:

- 多级Cache
由于物理条件的局限性以及高时钟频率的要求,一级Cache的容量是有限的。为了进一步减少缺失率,采用多级Cache结构。
二级Cache通常是一级Cache的10倍以上。当一级Cache缺失时,首先会到二级Cache中找,二级Cache的访问速度肯定是要比直接访问到更下层的主存储器更快的。
与上面的关联度相同,二级Cache太大则访问的时间也会变长,多级Cache也需要根据实际情况权衡考虑。
- 软件优化
在代码上,如果同一块操作(比如多个嵌套循环)需要用到的数据能够用Cache一次性存下来,那么就能保证在操作过程中的Cache访问都能够命中。
反之,如果需要重复访问的数据太多,那么访问到后面的数据时就会覆盖掉前面的,然后再嵌套回到前面的操作又覆盖掉了后面的数据,增加了很多不必要的Cache缺失
5.5. Dependable Memory Hierarchy
先来定义一些概念:
- 故障:机器从正常的运行状态中被中断,跳到对应的故障解决服务中。若不能从故障中恢复就是永久性故障,故障还可能是间歇性的。
- 可靠性:估量机器从某一点开始能够持续正常服务的时长。
- 平均故障时间(Mean Time To Failure):平均持续正常工作不发生故障的时长。
- 年故障率(Annual Failure Rate):给定MTTF之后,一年中发生故障的时间比率。
- 平均修复时间(Mean Time To Repair):一旦发生故障之后,从故障中恢复平均需要花费的时间。
- 平均故障间时间(Mean Time Between Failure):MTTF和MTTR的总和
- 有效性:用于估量机器在整个故障及恢复过程中正常工作市场的比率。
$$有效性=\frac{MTTF}{MTBF}=\frac{MTTF}{MTTF+MTTR}$$
可见要想提高有效性,就需要减小MTTR或者增加MTTF。
为了提高MTTF的三种方案:
- 从设计上避免故障发生;
- 依靠冗余备份,使得即使故障发生了也能够正常运行;
- 提前预测可能发生故障的情况,并提前修正错误。
5.6. Virtual Machines
虚拟机的概念在近期重新兴起,主要是源于:
- 现代系统中的隔离和安全性变得越来越重要
- 标准操作系统中存在安全性和可靠性方面的故障
- 计算机的共享,尤其是云计算近几年的发展
- 处理器的原始速度在近期得到了非常迅猛的提升,因此虚拟机的开销变得更加可接受了
这一节虽然短,但是留下来的疑问比较多,回头要重新花时间看下。
比如I/O-intensive、I/O-bound,似乎后者表示I/O密集,但是前一个单词的intensive本身就是密集的意思,可是这两个词还应该是不一样的。。。
5.7. Virtual Memory
另开了一篇单独记录:
5.8. A Common Framework for Memory Hierarchy
这一部分算是对前面内容的一次总结。
|机制名称|组数|每组的数据块数|定位方法|需要比较的次数|
|-|-|
|直接映射|Cache中的块数|1(关联度最小)|索引|1|
|组相联|Cache中的块数/关联度|关联度(一般为2~16)|按组索引,组中分别查找|关联度|
|全相联|1|Cache中的块数(关联度最大)|遍历|Cache中的块数|
|全相联|1|Cache中的块数(关联度最大)|独立的查找表|0|
随着关联度的增加,缺失率下降,但是访问时间与设备的代价增加。
全相联的情况下,若采用遍历的方式查找条目,则耗时很久;若采用单独的查找表,则设备上花费很大。
可以采用3C模型来评价Cache的整体表现。
5.9. Using a Finite-State Machine to Control a Simple Cache
使用有限状态机来控制一个简单的Cache

附录D:PDF材料
5.10. Parallelism and Memory Hierarchies: Cache Coherence
多处理器的Cache中还可能存在一些问题,也是并行一定会出现的问题,即:相同数据的冲突问题。
这里提到的与一般的并行冲突处理思路没什么不同。
5.11. Parallelism and Memory Hierarchy: Redundant Arrays of Inexpensive Disks
5.12. Advanced Material: Implementing Cache Controllers
5.13. Real Stuff: The ARM Cortex-A8 and Intel Core i7 Memory Hierarchies
这里是简单介绍了 A8 和 i7 里面的 cache 结构。
具体内容也没什么特别的,就是 i7 的 TLB 都有 2 级……666……以前还真没想过。
5.14. Going Faster: Cache Blocking and Matrix Multiply
5.15. Fallacies and Pitfalls
陷阱:写程序或者在一个编译器中生成代码时,忽略了存储器系统的行为。
陷阱:在模拟Cache时,忘记说明字节编址或者Cache块的大小。
陷阱:对于共享Cache,组相联度少于核心的数量或者共享该Cache的线程数。
陷阱:用存储器平均访问时间来评估乱序处理器的存储器层次结构。
陷阱:在未分配地址空间的顶部增加段来扩充地址空间。
谬误:域内磁盘错误率与他们的额定值相匹配。
谬误:操作系统是规划磁盘访问的最好的地方。
陷阱:在不为虚拟化设计的指令集系统结构上实现虚拟机监视器。
5.16. Goncluding Remarks
5.17. Historical Perspective and Further Reading
5.18. Exercises
下一部分: