接上篇:
本篇为第六章的内容。
CHAPTER 6. Parallel Processors from Client to Cloud
从客户端到云端的并行计算,这一章主要关注于处理器之间、集群之间的网络连接,并行性等等。
6.1. Introduction
关于并行的好处,前面的章节也已经有提到过了。
这里再重新明确一下串行(Serial)、并行(Parallel)、顺序(Sequential)、并发(Concurrent)的概念:
| 顺序 | 并发 | |
|---|---|---|
| 串行 | 在Intel Pentium 4上运行一个MATLAB的矩阵乘法程序 | 在Intel Pentium 4上运行Windows Vista操作系统 |
| 并行 | 在Intel Core i7 上运行一个MATLAB的矩阵乘法程序 | 在Intel Core i7 上运行Windows Vista操作系统 |
6.2. The Difficulty of Creating Parallel Processing Programs
事实上,现在的处理器技术中比如超标量和乱序执行的设计就已经是进行了指令级并行了,对于程序员来说,不需要做任何事情,编译器和计算机自己就会完成中间的步骤。
而要把一个串行的程序写成并行的,则会另外引入许多新的问题,包括:调度、将任务划分成多块、平衡多部分之间的负载、同步、多部分通信等等。而且这种情况是核心数量越多,越麻烦。
根据Amdahl定律,可以得出如下结论:
- 为了充分利用好多核,程序中任何一个很小的部分都需要并行化。为了在100个核心上达到90倍的加速比,程序中顺序执行的部分只能够占到0.1%。
- 核心数的增加只有在数据规模也同样提升时才能有比较明显的效果。
- 负载均衡很重要。
书上有详细的举例和计算。
也就是说,理论计算上的并行加速比其实是很难达到的,中间有太多的限制条件在,实际编程时也是非常困难。
6.3. SISD, MIMD, SIMD, SPMD, and Vector
基于指令流和数据流的数量,并行硬件有如下一些分类:
- SISD(Single Instruction stream Single Data stream),就是常见的单核处理器结构。
- MIMD(Multiple Instruction streams Multiple Data streams),常见的多核处理器结构。
- SIMD(Single Instruction stream Multiple Data streams)。
举例:
| Single Data stream | Multiple Data streams | |
|---|---|---|
| Single Instruction stream | Intel Pentium 4 | x86上的SSE指令集 |
| Multiple Instruction streams | 目前还没有 | Intel Core i7 |
通常在MIMD的结构上写程序的方法是只写一个单独的程序跑在多个核心上,根据判断语句来让多个核心分别执行不同的部分,这样的开发方法叫做SPMD(Single Program Multiple Data)。
MISD非常少见,最接近的情况可能是“流处理器”:对于一个输入流,用一系列的流水线指令去处理数据。
反之SIMD则很常见,例如出现在向量计算机上,对于同一条指令,同时有多个ALU分别参与计算(也可以叫做数据级并行)。它的优点是所有并行执行单元都是同步的,从程序员的角度看,这个其实非常接近于SISD(尽管每个单元都执行相同的指令,但是每个单元都有独立的地址寄存器和独立的数据地址),可能一个顺序应用程序在串行硬件上编译时按SISD组织,到并行硬件上编译就会按照SIMD组织。
基于SIMD的想法,x86处理器中的MMX(Multimedia Extension)、SSE(Streaming SIMD Extension)和后来的AVX(Advanced Vector Extension)得到了发展。
SIMD的一个更加古老和优雅的称呼是向量机体系结构(Vector Architecture)。
这种结构的特点在于拥有一些特殊的向量寄存器。
用Linpack基准测试中的DAXPY(Double Precision a*X Plus Y)循环来举例:
其中X和Y是64位双精度浮点数的向量,a是一个双精度标量。
常规的MIPS代码为:
1 | start: |
向量版的MIPS代码为:
1 | start: |
向量处理器大大降低了动态指令带宽,仅用6条指令就完成了接近600条普通MIPS指令的工作:原因一是整个向量操作是在多个数据元上同时进行的,二是节省了原本在普通MIPS中接近一半开销的循环指令。
另外普通的MIPS指令在流水线中是存在阻塞的,每次add.d必须等待mul.d,每次s.d也必须等待add.d,而在向量处理器中,每条向量指令只会在每个向量的起始数据元阻塞,随后的数据元会流畅地通过流水线。
效率被大大提高了。
向量结构对比标量结构、多媒体扩展来说都有很大的优势。
6.4. Hardware Multithreading
硬件多线程是跟 MIMD 相关的一个重要概念。
MIMD需要用多处理器去解决多项任务,为了保证效率的提升,需要硬件多线程技术来尽量填满每个处理器,即当一个线程发生阻塞时马上切换到另一个线程上运行,保证每个处理器都有较高的利用率。
线程与进程:
线程:包括PC、寄存器状态、栈的状态。可以是轻量的进程,线程通常共享一个单独的地址空间。
进程:进程包含一个或多个线程、一个地址空间、操作系统状态。
进程切换通常要涉及到操作系统层面,要花上几百到几千个时钟周期,而线程切换则只是处理器上的切换,处理器设计时就要保证能够快速切换。
硬件多线程的几种形式:
- 细粒度多线程(Fine-grained Multithreading)
每一个指令结束后都能进行线程切换,多线程循环交错地执行。
这种方式下,无论线程的阻塞时间长短,总体吞吐量不会受影响,因为通常会采用 round-robin 算法,一条线程出现阻塞时总能切换到另外的线程上去。缺点是降低了单条线程的执行速度,如果这条线程上不存在阻塞,则本来可以更快地执行完毕,现在中间还有穿插执行其他线程。
- 粗粒度多线程(Coarse-grained Multithreading)
这种方式是在一条线程出现较大的阻塞之后再切换至另一条,比如末级Cache缺失等。
对于单一线程来说,执行速度受的影响就很小了。
但这种方式的问题出现在线程流水线的启动上。正常运行单一线程时,单一线程填充在流水线中,当阻塞发生时,则需要清空流水线,并把另外一条线程的状态填入流水线。阻塞开始后执行的新线程必须要在指令完成之前填充流水线(否则还不如继续执行原来的呢)。
流水线启动开销在阻塞时间短的情况下影响特别明显,一般只有在阻塞时间比较长时,才能忽略掉这个启动开销。
- 同时多线程(SMT,Simultaneous Multithreading)
主要还是依靠多发射动态调度的流水线的能力来挖掘线程级并行,同时保持指令级并行。这种方式的核心思想是多发射处理器有多个功能单元,而单个线程可能根本用不上这些多余的硬件资源,依靠动态调度、寄存器重命名等等技术,来自不同线程的多条指令之间完全不会有数据依赖,能够被同时发射出来处理。
这种方式应该是最完美的,但具体实现起来还是有很多困难点的。需要用到超标量、寄存器重命名、动态调度等等技术,解决来自不同线程的多条指令的相关性等等问题。
最新的Intel Core i7处理器也只能够支持2个线程的实时多线程处理。
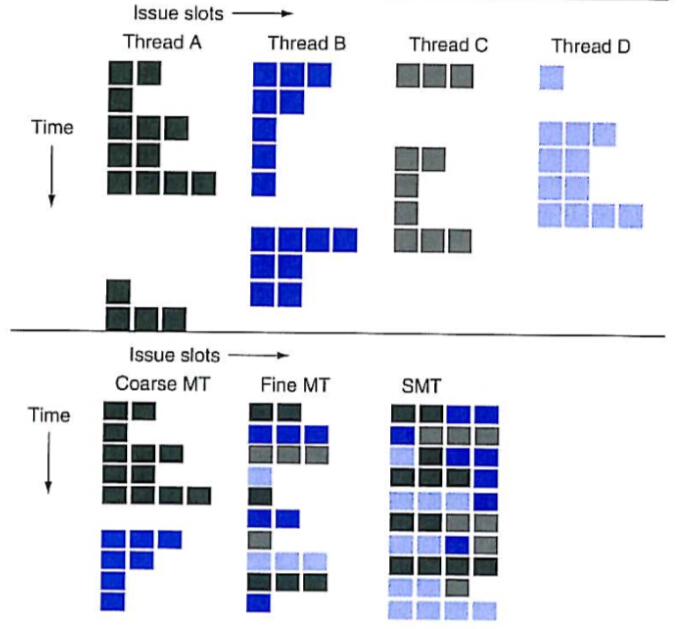
上面这张图的各种实现已经是基于超标量了。
可以很明显地看出,SMT下超标量+实时多线程的效果之强。
6.5. Multicore and Other Shared Memory Multiprocessors
这里讲的是一些常规的各种并行问题。
书上在这里也提到了OpenMP。
6.6. Introduction to Graphics Processing Units
这一节是GPU 的介绍。
随着游戏、图像等需求的发展,一类主要用于浮点运算的芯片开始发挥重要作用,用GPU把它们与CPU分类开来。用很便宜的价格就能够买到一个具有上百个流处理器核心的GPU。
GPU是辅助CPU的加速卡,因而它们只需要致力于提高浮点运算性能即可,其他的功能和控制能力可以很弱,甚至并不需要,交给CPU来完成即可。
GPU和CPU最大的区别是,GPU不需要依赖多级Cache来解决内存延迟,而是依靠硬件多线程,对于一个运算请求,通常GPU可以启动成百上千个独立的线程。它的设计完全是用来面向数据级并行问题的,就是说要大量用到 SIMD 特性的问题才适合在 GPU 上跑。
GPU 是一堆多线程 SIMD 处理器组合在一起的 MIMD 处理器结构。
GPU的主存是面向带宽而不是面向延迟的,GPU的主存通常能够提供更大的带宽,而容量通常要小于CPU的主存。
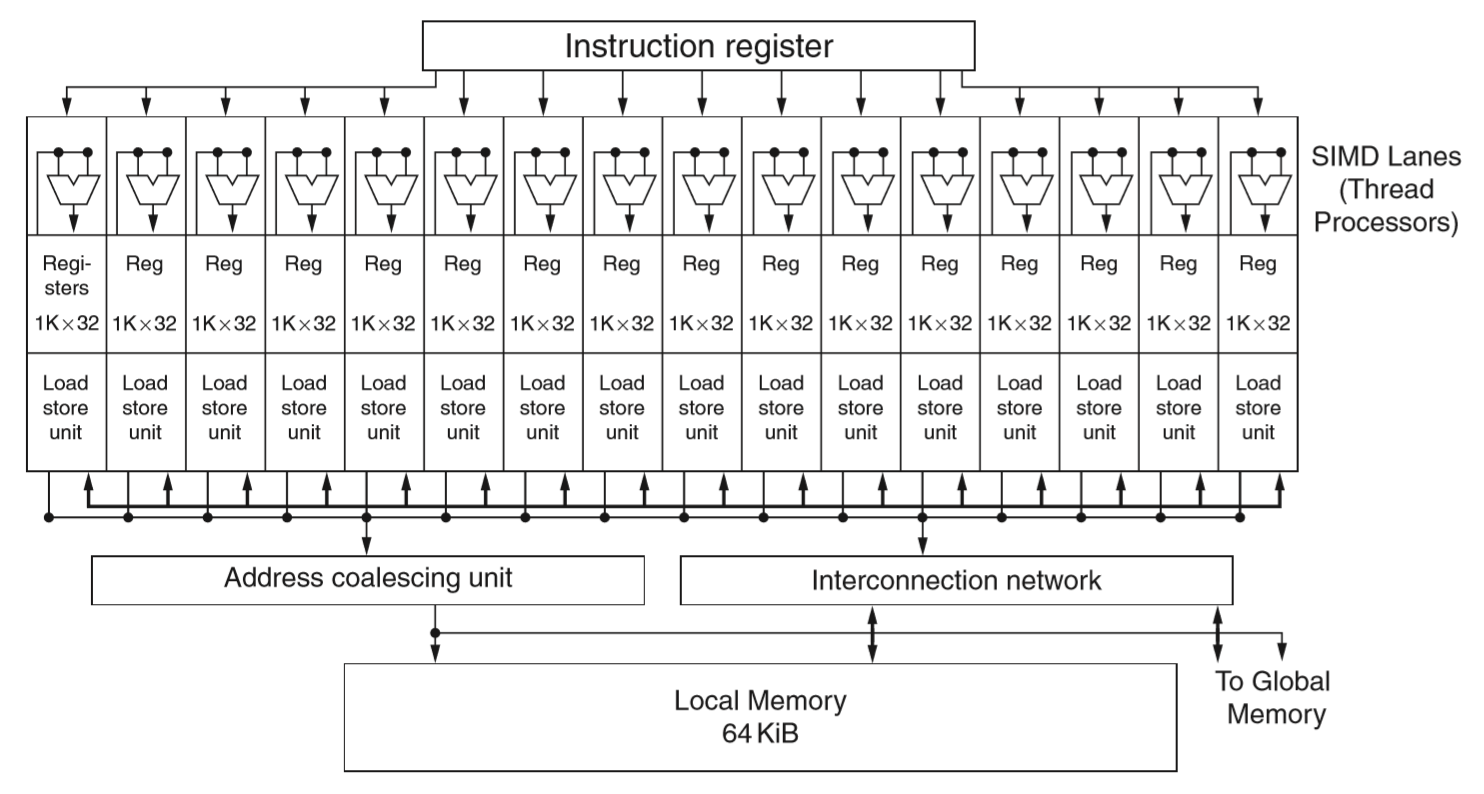
上面是个简单的GPU流处理器结构。
刚看到这里的时候,感觉书上讲的 Fermi 架构跟网上查到的还不太一样。
所以先查了一下官方资料。

一个Fermi流处理器(SM,Streaming Multiprocessor)里有32个单精 CUDA 核,16个 load/store 单元以及4个特殊功能单元(Special Functional Unit)。
CUDA 核内部是一个 32 位的整数 ALU(支持 64 位扩展运算),以及一个 FPU(支持单双精浮点运算以及 FMA)。64位的双精运算需要一排的两个 CUDA 核共同完成。所以一个 SM 在一个时钟周期内最多可以完成 16 个双精 FMA 操作。
接下来要说到流处理中的线程调度策略,Fermi 架构采用两级硬件调度器:
Block 级的线程调度器,这里叫 GigaThread global scheduler,在 SM 的外面,负责把线程 block 调度给空闲的 SM 来处理。
SM 本身能处理的指令都是 SIMD 的,这里的一条 SIMD 指令可以同时用上上图绿色部分的任意一排,即 16 个 CUDA 核、16 个 load/store 单元或者 4 个 SFU。
Wrap 级的线程调度器,就是上图中的 Warp Scheduler,在 SM 里面,且一个 SM 中有两个独立的 Warp 调度器和两个指令分发单元(dispatch unit),负责把 Wrap 中的线程扔给具体的执行单元去跑。
Wrap 本身表示的是 CUDA 里面的一组线程,即 32 个相似的线程打包在一起算是一个 Wrap。一个 SM 一次可以发射两个 Wrap,上图 4 排硬件中的任意两排可以同时执行。
当然如果是两个用 SFU 的 Wrap或者两个用 load/store 单元的 Wrap 肯定就不能双发射了。
然后回到书上那张图,这样就能明白是什么意思了。
书上的 SIMD 通道其实就是把 CUDA 核和 load/store 单元给放在了一起,相当于半个 SM 的硬件数据通路的结构。抽象成这个样子之后,这个抽象结构跟之前 6.4 节的传统多线程处理器基本是一致的,只是这里的每条指令都是 SIMD 的。
接下来是 GPU 上的存储结构:
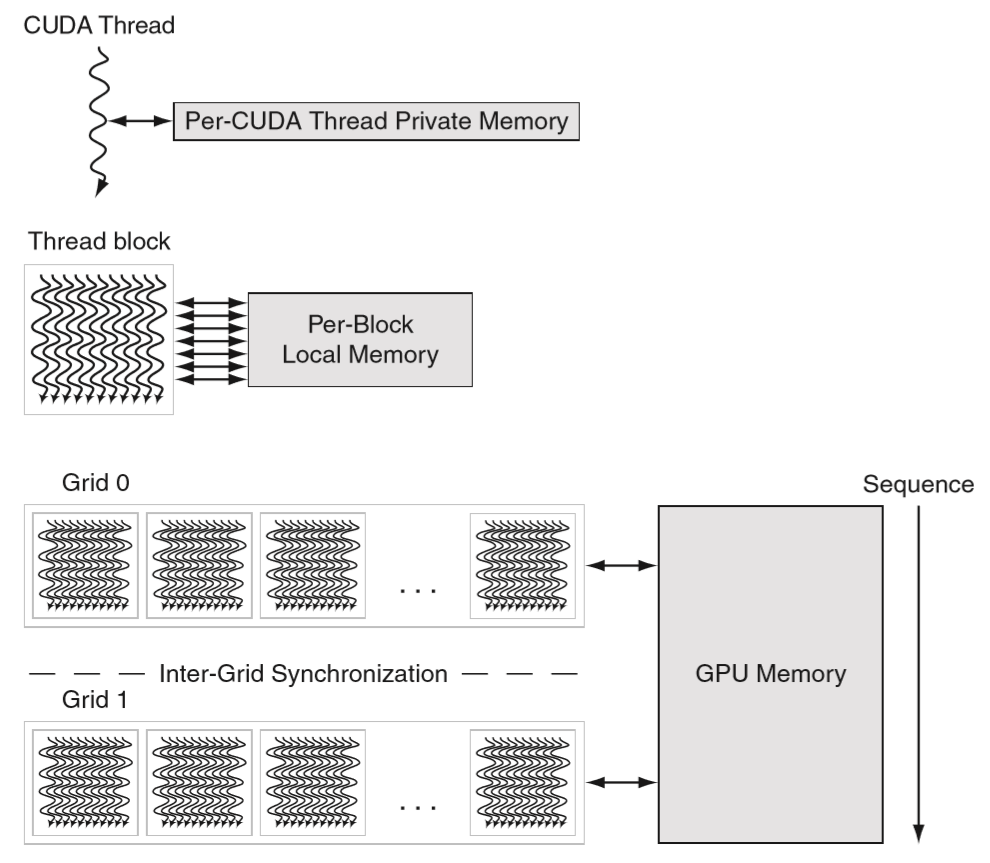
一个 SM 中的寄存器大小是 32k * 32 位,被所有这些 CUDA 核共享,均摊下来相当于每个 CUDA 核可以用到 1k 个 32 位的寄存器,这个也就是前面那张书上的图上画着的数据。实际运行中单个线程最多可以用到 63 个向量寄存器,每个向量寄存器由 32 个 32 位的寄存器元素组成(不超过 64 * 32 = 2k 个 32 位寄存器)。
片上有一块 64KB 大小的 shared memory 作为每个 block 的 local memory,这块片上内存可以配置成 L1 cache 或者手动来管理 shared memory。材质是 SRAM。
再往下一级,被所有的 grid 共享的就是 GPU 上的主存,材质是 GDDR 内存。
6.7. Clusters, Warehouse Scale Computers, and Other Message-Passing Multiprocessors
简要地介绍了一下集群中的环境,多节点之间的通信方式这时候就要用到消息传递了,因为已经没有了统一的共享内存。
6.8. Introduction to Multiprocessor Network Topologies
多处理器网络拓扑结构介绍。
资料:
6.9. Communicating to the Outside World: Cluster Networking
与外界的通信:集群网络
6.10. Multiprocessor Benchmarks and Performance Models
多处理器基准测试和性能模型
6.11. Real Stuff: Benchmarking Intel Core i7 versus NVIDIA Tesla GPU 538
实例:Intel Core i7与NVIDIA Tesla GPU 538的基准性能对比
6.12. Going Faster: Multiple Processors and Matrix Multiply
这一章肯定就是把原本单核的改成多核啦,16 线程的 OpenMP 大约又提升了 14 倍不到的加速比,那么再算上前面所有的这些加速方案,到这里为止,相比第三章中一开始的最初版程序一共提高了 212 倍的性能!