《Computer Organization and Design, Hardware/Software Interface》以及《Computer Architecture: A Quantitative Approach》被誉为体系结构界的两本圣经。
最近除了编译原理外,还在补的就是《硬件/软件接口》这一本了。
这本书讲解得非常透彻。原本我只是对体系结构、CPU有个模糊的很难学的概念,,,书中由浅至深详细地解释了其中的工作原理,,,,真的好难啊Q_Q…
2018-02-02
当时还剩下最后一章的一点东西没看,回来把这些内容看完。
算是在这个方面做了这么久的工作,对里面的好多东西也都有了新的理解,顺便重新整理一下。
本书的官方主页:Elsevier Store
笔记的内容基本上按照目录,这一篇记的是前三章的主要内容。
CHAPTER 1. Computer Abstractions and Technology
1.1. Instruction
1.2. Eight Great Ideas in Computer Architecture
计算机系统结构中的八个 Great Ideas
其实系统结构设计发展这么多年了,很多核心的设计思想本质上都是几个基本原理。
- Design for Moore’s Law
系统结构设计的周期通常都比较长,由于摩尔定律的存在,很有可能项目开始时和项目结束时能够提供的原件在工艺方面的性能就有很大的差距了,因此做系统结构设计需要考虑到这方面的因素。
话说 Intel 每年的 CPU 升级战略也有一点这个意思,“Tick-Tock”一年升级工艺制程,一年升级架构设计。
然后到了 2017 年,摩尔定律开始唱衰了,各方都开始吹摩尔定律要走到头了,一大波人转而去搞领域专用的 ASIC 芯片设计去了。
- Use Abstraction to Simplify Design
分层次进行设计,底层的细节对上层不透明,意思就是上层不用去管底层里面是怎么做的,只要给我想要的接口就好了。
其实也就是模块化。这样做的好处是,比如做某一层工作的人可以专心钻在那层里面,在自己的范围内做改进啊做优化啊,不用去管别人的工作需要做什么。
当然层次分的太多,可能也会引起性能的下降,有的时候我们搞优化的反而就想要层次简单点,一波直通到底。
- Make the Common Case Fast
做优化要把工作放在 Common Case 上, 花大力气在 Rare Case 上就浪费了。另一方面要找到最耗时的点,找到瓶颈所在才有用。
那么哪些地方是 Common Case 呢?这就需要做针对性的测试来找出来了(见 Section 1.6)。
- Performance via Parallelism
并行也没啥好说的,这几年的发展趋势就是硬件上单核往多核甚至众核走,算法上也都要往并行方面设计。
- Performance via Pipelining
流水线是一个非常重要的思想,在硬件和软件的架构设计里面都能用的到。
多级流水可以提高资源利用率、隐藏延迟等等。
- Performance via Prediction
这块主要指的是处理器指令预测、指令预取等等。
- Hierarchy of Memories
存储器分级最突出的体现还是在 cache 上,现在主流的处理器上 cache 已经做到了 L3,可能过几年就有 L4 了。
- Dependability via Redundancy
通过冗余设计来保证系统可靠性,这个主要是容灾备份的思想。
1.3. Below Your Program
这里有一句特别有意思的话:
Just as the 26 letters of the English alphabet do not limit how much can be written, the two letters of the computer alphabet do not limit what computer can do.
程序运行的过程:
高级语言编译成汇编语言(低级语言),再汇编成机器语言,然后硬件运行
1.4. Under the Covers
这一节拿 iPad2 简单介绍了一下硬件实现。在电子元件的层面,无论是屏幕显示还是计算都是 0 和 1,从元件往上开始就涉及到了前面说的抽象思想了,指令集就是对机器码实现的抽象。
1.5. Technologies for Building Processors and Memory
电子元件的发展演变:
| 年份 | 电子元件技术 | 单位资源消耗能得到的相对性能 |
|---|---|---|
| 1951 | 电子管 | 1 |
| 1965 | 晶体管 | 35 |
| 1975 | 集成电路 | 900 |
| 1995 | (Very)大规模集成电路 | 2,400,000 |
| 2013 | (Ultra)超大规模集成电路 | 250,000,000,000 |
话说理论上来说从 1965 年一直到现在本质上用的原件都还是晶体管,只不过工艺水平一直在提升,集成度也在不断增加,摩尔定律本质上是对单块芯片里面晶体管数量增长率的估计。
来看下 CPU 这些芯片是怎么造出来的:

首先原料是从硅开始,硅是一种出色的半导体材料,它本身的导电性介于导体和绝缘体之间,但是经过某些化学处理之后,可以变成三种不同性质的结构:
- 用微观铜线或者铝线(microscopic copper or aluminum wire,不知道这个具体处理过程是啥)处理之后,可以变成良导体
- 绝缘体
- 可控进行导电或者不导电,起到开关的作用(晶体管)
把纯的单晶硅熔化了,从里面拉出来硅锭(silicon crystal ingot);硅锭是圆柱形的,对其进行横向切片,得到了厚度小于 0.1 英寸的晶圆(wafers);然后经过 2040 道工序的化学处理,就把晶圆上的不同位置变成了前面说的三种结构,要么导电、要么不导电、要么变成晶体管,这个过程也就是电路蚀刻(现在的半导体工艺已经做到了单层晶体管,28 层用绝缘体隔开的导体结构)。
电路蚀刻的过程非常复杂,由于工序太多,而且中间都是各种物理化学反应,很难做到一整个晶圆上的电路都是完美的,所以芯片制造工艺从一开始就考虑了这一点,一个晶圆上蚀刻了很多片(dies)芯片(chips)。这样虽然很难保证整块晶圆上的电路都是完美的,但是切出来的单块芯片是完美的的可能性还是很大的。后续就是对这些芯片做测试,通过测试的再封装上外围电路等等,就生产出来完整的 CPU 了。
封装这件事情上面还有个比较有趣的点。同代的某种型号的 i7、i5、i3 有可能出自同一个晶圆!!!完美的芯片做成 i7,有瑕疵然后测试挂了几个核的就封装的时候关掉几个核做成 i5,瑕疵更多挂了更多个核的就封装成 i3。
一些资料:
1.6. Performance
两个需要区别开的概念:
- wall clock time、response time、elapsed time:指的都是跑一个任务实际花费的时间,包含了 I/O 啊,访存啊,操作系统 overhead 啊等等等等,相当于用秒表记出来的时间;
- CPU execution time、CPU time:指的是 CPU 跑这个任务消耗的时间,实际上对应的是 CPU 跑了多少个时钟周期,里面不包含其他部分消耗所花费的时间(I/O,线程切换等等其他这些)。
后面说系统性能针对的时间计量方式是前者,而 CPU 性能针对的时间计算方式是后者。
面向某个具体的优化任务时,要考虑清楚要用哪种方式来计量。优化要达到的性能指标跟性能定义是直接相关的,也需要针对具体的指标来找出性能瓶颈所在。
性能的定义:
$$性能_X=\frac{1}{运行时间_X}$$
X比Y快n倍:
$$\frac{性能_X}{性能_Y}=\frac{运行时间_Y}{运行时间_X}=n$$
CPU运行时间/CPU时间:
$$CPU运行时间=CPU时钟周期数*时钟周期时间=\frac{CPU时钟周期数}{时钟频率(主频)}$$
CPI(时钟周期/指令):
$$CPU时钟周期数=指令数*CPI$$
$$CPU运行时间=指令数*CPI*时钟周期时间=\frac{指令数*CPI}{时钟频率}$$
1.7. The Power Wall
功耗与主频几乎是同等上升的,主频越高功耗越高。前期主频提升很快,而最近一个阶段,处理器的主频基本不再提升,因为功耗已经达到了一个相当高的程度,在散热等其他方面还没办法跟上的时候只能限制主频的提升。
- 动态功耗
CPU 的功耗主要是动态功耗,来源于晶体管的开关切换,即高低电平(0 和 1)之间的翻转,这中间本质上是个充放电的过程,所以这部分能量消耗是无法避免的:
$$动态功耗\propto *电容性负载*电压^2*开关频率$$
动态功耗与主频成正比,与电压的平方成正比。
- 静态功耗
静态功耗主要来自于晶体管的漏电流,也几乎是无法避免的,只能通过工艺改进来减少。
一些资料:
1.8. The Sea Change: The Switch from Uniprocessors to Multiprocessors
受到工艺、功耗等的限制,单纯地提升主频来提高处理器的性能已经是做不到了,因此转向提高处理器的并行能力来继续发展CPU,即往一个芯片中集成更多的处理核心,而从单核开始向多核转变。
之前由于性能的提升主要在工艺、硬件层面,对于软件来说影响很小,但是多核处理器出现之后,也推动了并行算法的发展,因为只有从算法上进行改进才能够更好地利用上多核处理的优势。
1.9. Real Stuff: Benchmarking the Intel Core i7
实例:Intel Core i7的基准测试
1.12. Historial Perspectives and Further Reading
1.13. Exercises
CHAPTER 2. Instructions: Language of the Computer
第二章主要是以 MIPS 为例,介绍计算机指令。
2.1. Instruction
2.2. Operations of the Computer Hardware
设计原则1:简单有助于规整
定义一些基本的操作,再用基本的操作来组成复杂操作。
2.3. Operands of the Computer Hardware
设计原则2:越少越快
为了保证每个寄存器的读取速度,寄存器数量不能太多。
2.4. Signed and Unsigned Numbers
2.5. Representing Instructions in the Computer
设计原则3:好的设计需要适宜的折中方案
计算机指令的设计需要考虑到指令长度等等一系列复杂的因素。
2.6. Logical Operations
2.7. Instructions for Making Decisions
2.8. Supporting Procedures in Computer Hardware
函数和过程的实现,主要通过地址跳转和堆栈来完成。
2.9. MIPS Addressing for 32-Bit Immediates and Addresses
32位立即数和地址的MIPS编址
| 说明 | op | rs | rt | rd | shamt | funct | address | |
|---|---|---|---|---|---|---|---|---|
| R-format | 算术/寄存器操作 | 6位 | 5位 | 5位 | 5位 | 5位 | 6位 | |
| I-format | 转移/分支/立即数操作 | 6位 | 5位 | 5位 | 16位 | |||
| J-format | 跳转操作 | 6位 | 26位 |
条件转移范围:
16位地址码,但是MIPS中是按4字节寻址,即实际上可以表示18位的地址
18位首位为符号位,即可跳转到当前PC位置的$(-32K\sim32K-1)*4=-128K\sim(128K-4)$字节
立即数范围:
与上同理,都属于I-format的指令,因此可表示的立即数范围为$-32K\sim32K-1$
跳转指令范围:
26位地址码,4字节寻址,实际可表示28位地址
28位为无符号数地址,可跳转到$(0\sim2^{26}-1)*4=0\sim(256M-4)$字节
2.10. Parallelism and Instructions: Synchronization
并行编程的指令中最重要的是原子操作,即多个不同进程之间的同步。
这里介绍了一下 ll(load link)和sc(store conditional)指令。
2.11. Translating and Starting a Program
高级语言编译成汇编语言,再汇编成机器码的二进制对象,之后链接上一些必要的库文件(也是机器码二进制对象),最终才得到了机器码的二进制可执行文件,然后 load 到内存里运行。
2.12. A C Sort Example to Put It All Together
一个C语言的排序示例
2.13. Advanced Material: Compiling C
提升材料:编译C语言
2.14. Real Stuff: ARMv7 (32-bit) Instructions
实例:ARMv7(32位)指令
2.15. Real Stuff: x86 Instructions
实例:x86指令
2.16. Real Stuff: ARMv8 (64-bit) Instructions
实例:ARMv8(64位)指令
2.19. Historial Perspectives and Further Reading
2.20. Exercises
CHAPTER 3. Arithmetic for Computers
计算机中的算术运算
3.1. Instruction
3.2. Addition and Subtraction
加减的硬件实现考虑数电中的加减电路,原理还是很简单的。
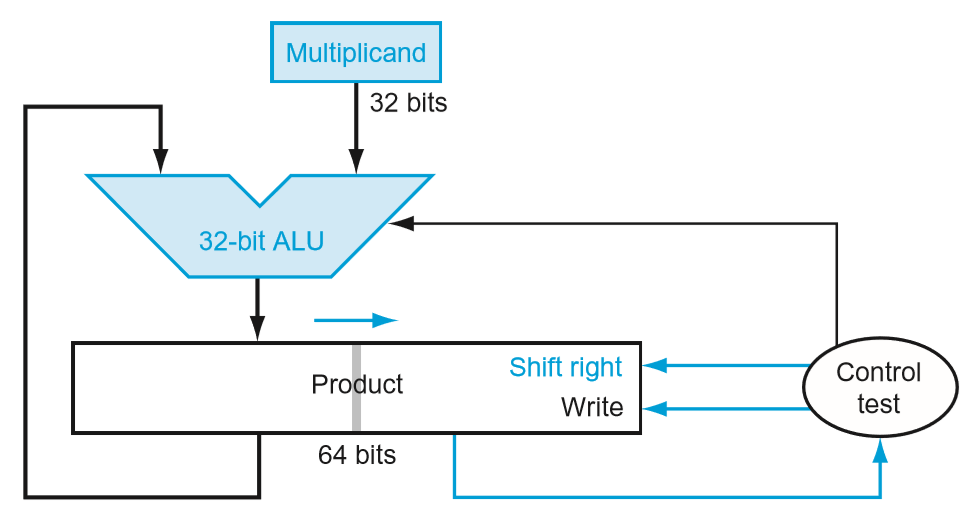
3.3. Multiplication
乘法的硬件实现也可以看成是用纸笔列竖式乘法方法的衍生,即移位和加法。
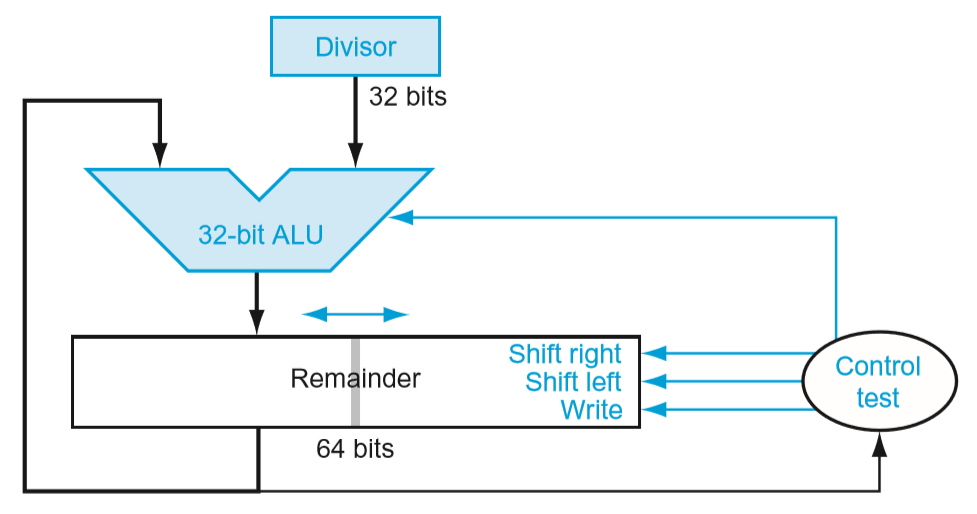
3.4. Division
移位加比较,原理类似。
3.5. Floating Point
计算机中的实数用科学计数法来表示,将一个存储空间的一部分用于表示指数,另一部分用于表示尾数。
存储空间的总大小是一定的,指数数位越多,则表示的数的范围越大,但是由于尾数数位少了,有效数位下降了;反之,指数数位越少,表示的数有效数位越多,精确度越高,但是能够表示的范围就小了。
以MIPS中常见的32位浮点数表示为例:

首位为符号位,接下来8位是带符号的指数部分,最后23位是尾数,则整个数最后表示的内容是:
$$(-1)^S*F*2^E$$
它能表示的范围在:$2*10^{-38}\sim2*10^{38}$
64位的浮点数结构则是这样的:

表示的范围在:$2*10^{-308}\sim2*10^{308}$
IEEE754标准对零、无穷与无效数据格式作了规定:

除此之外,对浮点数有两个比较重要的规定:
- 忽略尾数的前导1
- 指数带偏阶
标准格式的10进制科学计数法中,整数位一定是个介于1~9之间的数,否则就可进一步进行标准化,把多出来的数位算到指数上去。
那么2进制的科学计数法也是一样的道理。因此尾数第1个数位一定是1,则约定俗成的,若是隐藏这个前导1,实际可以多表示一位数位。
指数的偏阶是为了避免一个看上去似乎是很大的数,因为指数是负数,而结果很小的情况。
32位浮点数中,默认将阶数加上127作为存储的指数。
这样$128_{10}=10000000_2$的指数实际上表示1;而$0_{10}=00000000_2$实际上表示-127。
则最终,实际上浮点数的表示是:
$$(-1)^S*(1+F)*2^{E-Bias}$$
3.6. Parallelism and Computer Arithmetic: Subword Parallelism
处理图像和声音等等数据时,可能会有一堆类似的操作一起出现,考虑并行处理。
这里的子字并行(subword parallelism)这个词其实就是平常更常说的向量化或者 SIMD。就是一条指令对一组数据进行相同的操作。
3.7. Real Stuff: Streaming SIMD Extensions and Advanced Vector Extensions in x86
实例:x86中的SIMD流扩展和高级向量扩展
3.8. Going Faster: Subword Parallelism and Matrix Multiply
DGEMM: Double precision GEneral Matrix Multiply
对比了x86架构中 scalar double 与 parallel double 两种指令集的性能。其中 parallel double 在运算时执行的是并行的浮点乘法运算(SIMD)。
优化前性能:1.7GFLOPS
优化后性能:6.4GFLOPS
3.11. Historial Perspectives and Further Reading
3.12. Exercises
后接下一部分: