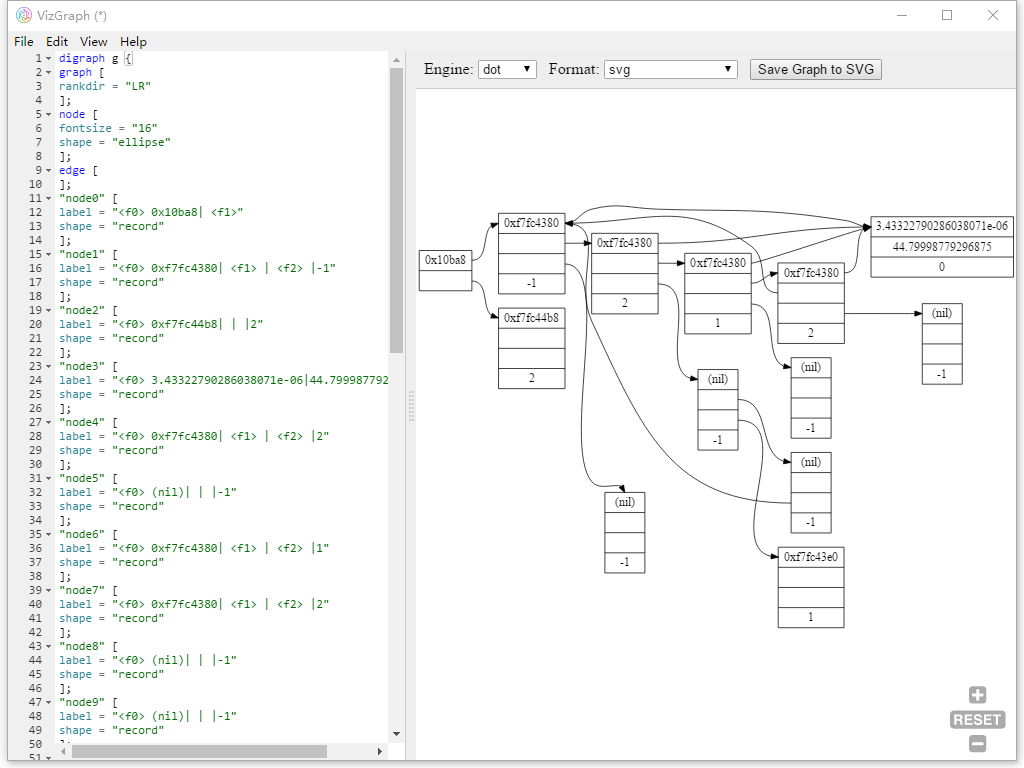
这事的起因是想给前面那篇 TF 拆包画个函数调用图,然后试了若干画图工具都不是很满意,最后准备试试看能不能造个轮子出来。
Electron 上手还是很容易的,即使对我这样前端基础甚少的第一次写这种项目的人,找了个别人做的网页实现照着做,也只花了一个下午就写出来一个初版了。
18年的第一篇,开一个估计又是会持续超长时间的坑。
要来拆包 TensorFlow 啦。
嗯,话说这件事情前年、去年就一直在做,做完 RDMA 写完论文就扔一边了,也没再整理过。没想到之后的工作还是回到了这里,所以重新过一遍,也好好整理一下。
给毕业论文方向找资料ing,虽说具体要做的东西目前还在思考比较多,从之前的 【整理一下看过的论文】 里面把相关的论文理出来了。
大致分成三个方面:
虽说重点主要集中在后面两块上,不过其他方面的机器学习毕竟发展的时间比深度学习更早,分布式系统方面还是有参考价值的。
把第二三两部分分开整理主要考虑一个是偏框架和算法设计,一个是偏向针对某个具体的应用问题做的大规模实现。
Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)
Ponyo and Garfield are waiting outside the box-office for their favorite movie. Because queuing is so boring, that they want to play a game to kill the time. The game is called “Queue-jumpers”. Suppose that there are N people numbered from 1 to N stand in a line initially. Each time you should simulate one of the following operations:

逛知乎的时候发现的这个问题:
一开始只是觉得这个名字熟悉(脑子里面冒出来的是 Tarjan 离线 LCA),点进去一看越看越心惊。
强连通分量?哦,那个经典算法好像确实叫 Tarjan。LCT 动态树…卧槽他写的?斐波那契堆…卧槽他写的?Splay 伸展树…卧槽他写的?
从 1971 年至今,Tarjan 大佬大概发了 300 篇左右的论文,还在不断产出,他创造了一堆图论、树结构上的经典算法,还获得过 1986 年的图灵奖。
嗯,原本打算写着玩系列写个内存池、线程池啥的,前段时间做医疗影像 DL 项目的时候跟实验室的小伙伴一起用 C++ 和 Cuda 写过一个 Inference 的框架。
那个项目后面还不知道要怎么发展,似乎暂时没办法把框架公开出来。然后内存池只写了个开头,准备等有空再出来补补吧。线程池…嗯,还不知道在哪呢。
最近整理以前的资料的时候又给自己找了个新坑。嗯,虽说之前在 gRPC 和 TensorFlow 上都改过 RDMA,然而这两个都是当时直接改在它们原本的源码里面的,要有人让我再改一个别的东西那我就傻了,又得从头重新走一遍。要我给个示例的话,手上只有当时最早学 RDMA 时从 rc_pingpong 里扒出来的 client 和 server 了。
于是准备开个新坑,整理个自己的的 RDMA 轮子库出来。
发现以前会的好多算法现在都忘得差不多了。。。翻了翻以前写过的一些比较复杂的题目,发现现在真是两眼一抹黑。
准备有空重新开始刷一波题。
先开个线段树的专题吧。
还是得多看别人的论文,看多了等自己有东西能写的时候才能写得出来。
迷迷糊糊地就发出去第一篇 Paper 了。。。回想起来也算是幸运吧。
把以前看过的论文都理一理,共享在 OneDrive 上了(似乎被墙了):
事情的起源是这样的:
想把笔记本上的 1060 用起来,但是 Windows 下 Cuda 的 nvcc 只跟 VS 的编译器绑定,没法换成 Mingw,这就很不开心了。虽然实在为了在 Windows 下跑程序方便,还是把 VS 2015 装上了(吃了我整整几十个 G 的空间,心疼),但是用起来仍然是非常不爽。
虽说以前也经常折腾 Win + Linux 的双系统,这次换完笔记本之后觉得破坏原本的分区引导什么的贼不清真 ╮(╯_╰)╭ 然后并不想装。
…
那最后还是要用啊,怎么办,好烦。
…
后来终于有了个(自己觉得)特别 6 的想法。我搞个 U 盘装上就好了哇!用 Linux 的时候插上,不用拔了,特别清真!
然后。。。晚上下了个单,第二天 U 盘就到啦。。。(还特意买个新 U 盘。。。主要是老 U 盘容量都太小)。
然后。。。就没有然后了,中间一直坑。

关于 Node.js 的异步编程之前已经稍微了解过了,再来继续深入研究一下用来支持它异步能力的底层事件库 —— Libuv。
这个标志还是很霸气的,也象征了这个库简单粗暴又高效的特点。