最近 NV 刚发布了新架构的 GPU,自之前理过 Intel CPU 的架构变化 后再来理一下 GPU 的。
硬/软件接口那篇有介绍过 GPU 的结构,当时也是以 Fermi 架构为例的,NV 很有意思的是会用一些历史上杰出的科学家的名字来命名自己的硬件架构。
总体上,NV GPU 用到的 SIMT 基本编程模型都是一致的,每一代相对前代基本都会在 SM 数量、SM 内部各个处理单元的流水线结构等等方面有一些升级和改动。这篇暂时不涉及到渲染管线相关的部分,其他诸如多少 nm 工艺、内存频率提升等等也都先略过,只关注计算相关的硬件架构演进。
Tesla
关于初代 GPU 的架构,找到的资料不太多,基本上都是从 Fermi 开始的。
Fermi
Compute Capability: 2.0, 2.1

每个 SM 中包含:
- 2 个 Warp Scheduler/Dispatch Unit
- 32 个 CUDA Core(分在两条 lane 上,每条分别是 16 个)
- 每个 CUDA Core 里面是 1 个单精浮点单元(FPU)和 1 个整数单元(ALU),可以直接做 FMA 的乘累加
- 每个 cycle 可以跑 16 个双精的 FMA
- 16 个 LD/ST Unit
- 4 个 SFU
我的理解是做一个双精 FMA 需要用到两个 CUDA Core?所以是 32 / 2 = 16
Kepler
Compute Capability: 3.0, 3.2, 3.5, 3.7
这一代 SM 整体结构上跟之前是一致的,只不过升级完了以后又往里面塞进去了更多的运算单元,其他部分也没有做太大的改动。
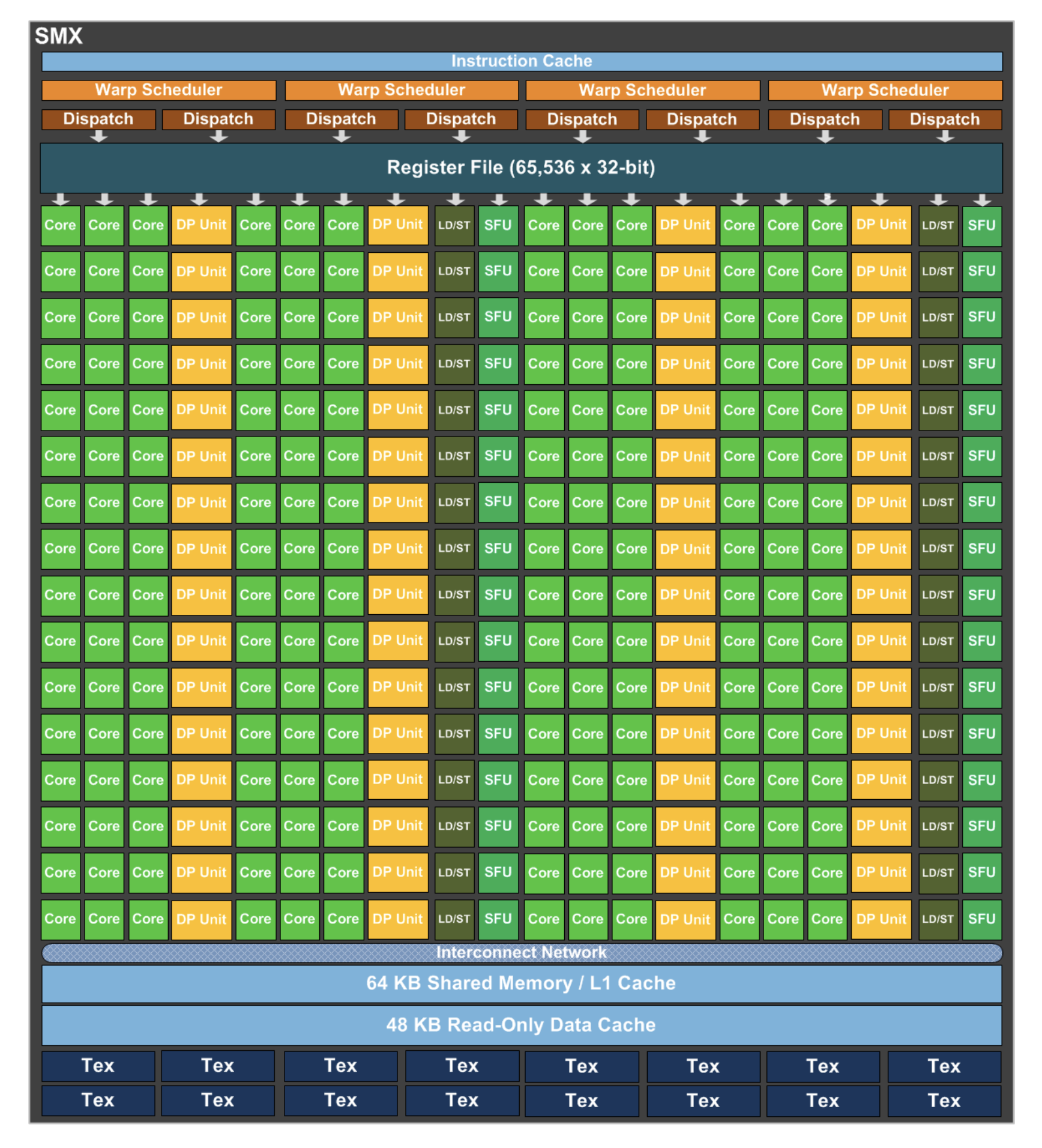
每个 SM(这里叫 SMX 了)中包含:
- 4 个 Warp Scheduler,8 个 Dispatch Unit
- CUDA Core 增加到 192 个(4 * 3 * 16,每条 lane 上还是 16 个)
- 单独分出来 64 个(4 * 16,每条 lane 上 16 个)双精运算单元。
- SFU 和 LD/ST Unit 分别也都增加到 32 个
Kepler 是附近几代在硬件上直接有双精运算单元的架构,不用通过单精单元去做双精运算了,所以对比前后几代的双精浮点的性能话会发现 Kepler 要高出一截。
Maxwell
Compute Capability: 5.0, 5.2, 5.3

可能是觉得 Kepler 往一个 SM 里面塞了太多东西,其实最终效率也并没有那么高,这一代的 SM 开始做减法了,每个 SM(SMM)中包含:
- 4 个 Warp Scheduler,8 个 Dispatch Unit
- 128 个 CUDA Core(4 * 32)
- 32 个 SFU 和 LD/ST Unit(4 * 8)
Kepler 里面 192 这个数字也被诟病了(不是 2 的倍数)。
这些硬件单元的流水线分布也不再是像 Kepler 那样大锅炖了,而是有点像是把 4 个差不多像是 Fermi 的 SM 拼在一起组成一个 SM:
每个 Process Block 里面是:
- 1 个 Warp Scheduler 和 2 个 Dispatch Unit
- 32 个 CUDA Core
- 8 个 SFU 和 LD/ST Unit
图上没有看到之前 lane 的标记,不过我猜应该也还是 4 条,两条 CUDA Core 的 lane,1 条 SFU,1 条 LD/ST Unit。
应该是工艺和频率的提升,Maxwell 每个 CUDA Core 的性能相比 Kepler 提升了 1.4 倍,每瓦性能提升了 2 倍。对 CUDA Core 的详细结构没有再介绍,姑且认为从 Fermi 开始一直到以后 CUDA Core 内部的结构都没有什么改变。
另外一点是,前面说到的双精单元在这一代上也移除了。
也许是觉得认为只有少数 HPC 科学计算才用的上的双精单元在这代上不太有必要吧。
Pascal
Compute Capability: 6.0(P100), 6.1(GTX 10x、P40、P6、P4), 6.2
这一代可以说是有了质的飞跃,还是先从 SM 开始:

可以看到一个 SM 内的部分作了进一步的精简,整体思路是 SM 内部包含的东西越来越少,但是总体的片上 SM 数量每一代都在不断增加,每个 SM 中包含:
- 2 个 Warp Scheduler,4 个 Dispatch Unit
- 64 个 CUDA Core(2 * 32)
- 32 个双精浮点单元(2 * 16,双精回来了!)
- 16 个 SFU 和 LD/ST Unit(2 * 8)
一个 SM 里面包含的 Process Block 数量减少到了 2 个,每个 Process Block 内部的结构倒是 Maxwell 差不多:
- 1 个 Warp Scheduler 和 2 个 Dispatch Unit
- 32 个 CUDA Core
- 多了 16 个 DP Unit
- 8 个 SFU 和 LD/ST Unit
单个 Process Block 的流水线增加到 6 条 lane 了?
其他质变的升级包括:
- 面向 Deep Learning 做了一些专门的定制(CuDNN 等等)
- 除了 PCIE 以外,P100 还有 NVLink 版,单机卡间通信带宽逆天了,多机之间也能通过 Infiniband 进一步扩展 NVLink(GPUDirect)
然后 NV 现在已经把 Infiniband 行业的龙头 Mellanox 给收购了……说不定那时候就已经有这个想法了呢
- P100 上把 GDDR5 换成了 HBM2,Global Memory 的带宽涨了一个数量级
- 16nm FinFET 工艺,性能提升一大截,功耗还能控制住不怎么增加
- Unified Memory,支持把 GPU 的显存和 CPU 的内存统一到一个相同的地址空间,驱动层自己会做好 DtoH 和 HtoD 的内存拷贝,编程模型上更加友好了
CUDA Core 在这一代也终于有了升级,现在硬件上直接支持 FP16 的半精计算了,半精性能是单精的 2 倍,猜测应该是一个单精单元用来算两个半精的计算。
Volta
Compute Capability: 7.0(TITAN V、V100), 7.2(Xavier)
又一个针对深度学习的质变 Feature,Tensor Core!
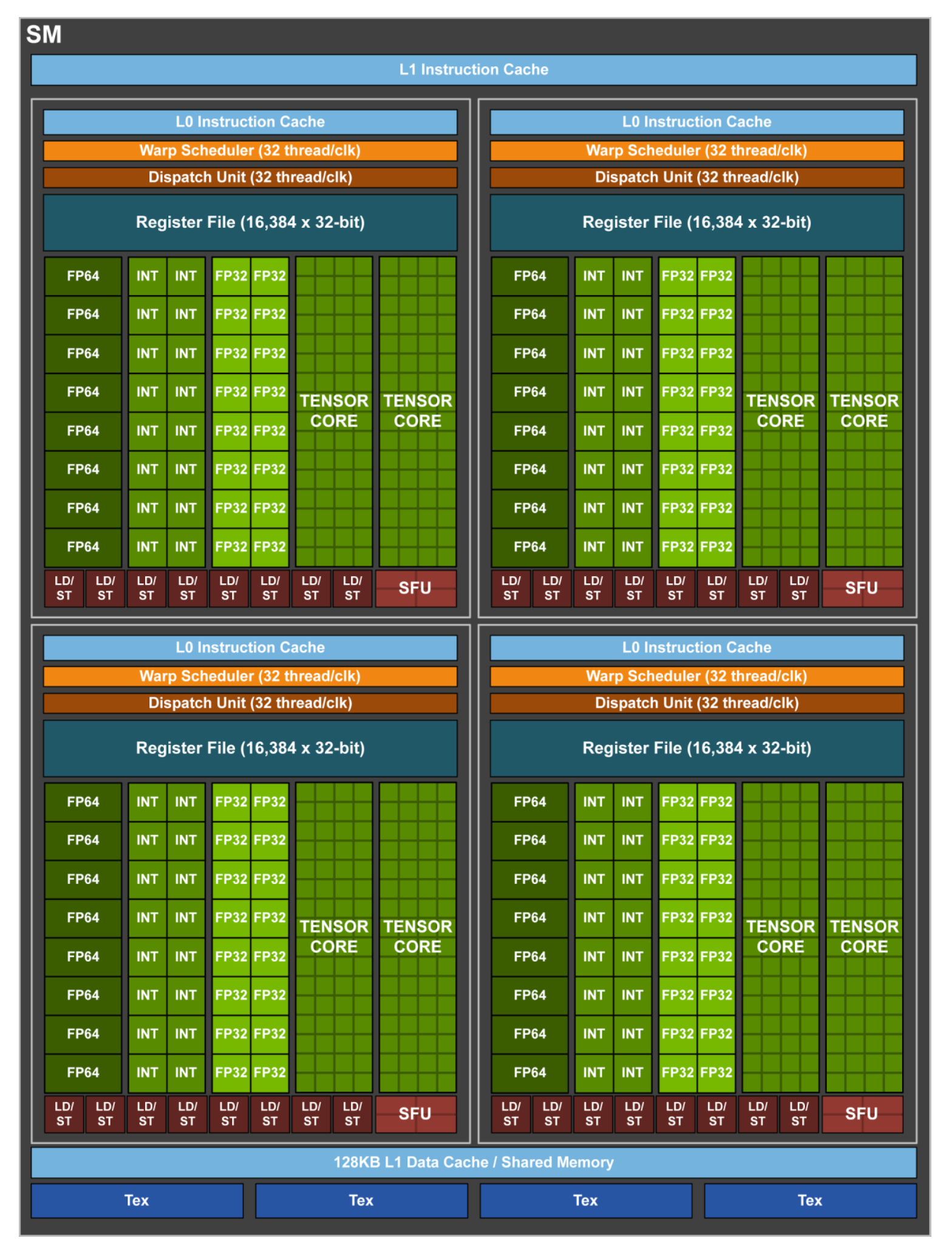
看到 SM 的时候我们会发现这一代除了多出了一个额外的 Tensor Core 的单元以外,怎么 SM 的体积看起来好像又加回去了,每个 SM 中包含:
- 4 个 Warp Scheduler,4 个 Dispatch Unit(发现不需要配 2 个 Dispatch 给每个 Scheduler 了?白皮书里面倒是没有对这个的解释)
- 64 个 FP32 Core(4 * 16)
- 64 个 INT32 Core(4 * 16)
- 32 个 FP64 Core(4 * 8)
- 8 个 Tensor Core (4 * 2)
- 32 个 LD/ST Unit(4 * 8)
- 16 个 SFU
事实上相比 Pascal 而言,单个 SM 中的单精运算单元数量是一致的,相当于把 Pascal 中的每个 Process Block 进一步地又拆成了 2 个,每个 Process Block 中包含:
- 1 个 Warp Scheduler,1 个 Dispatch Unit
- 16 个 FP32 Core
- 16 个 INT32 Core
- 8 个 FP64 Core
- 2 个 Tensor Core
- 8 个 LD/ST Unit
- 4 个 SFU
这里把原本的 CUDA Core 给拆开了,FP32 和 INT32 的两组运算单元现在是独立出现在流水线 lane 里面了,这一设计的好处是在前几代架构中 CUDA Core 同时只能处理一种类型的运算,而现在每个 cycle 都可以同时有 FP32 和 INT32 的指令在一起跑了。Pascal 中需要 6 个 cycles 来做一组 FMA,现在在 Volta 中只需要 4 个 cycles。
另外每个 Warp Scheduler 还有了自己的 L0 指令 cache。
这一代还改进了一下 MPS,现在从硬件上直接支持对资源的隔离,方便多任务共享 GPU。
其他一些比较重要的改进:
Tensor Core
最重大的改动不用说也知道是 Tensor Core 了。
Tensor Core 的思路从系统设计上还是相当直接的,目前深度学习的 workload 中最主要的计算量都在矩阵的乘加上,因此为了专门去高效地支持这些 workload,就增加一些专用于矩阵运算的专用部件进去。
这个也是常见的 AI ASIC(比如 Google 的 TPU、其他厂商的各种 xPU 等等)通常采用的思路,只不过 ASIC 可以从一开始就是针对特定的 workload 去的,因此设计上可以更直接更激进一些,直接上大量的 MMU(Matrix Multiply Unit),然后采用例如脉冲阵列这种设计去最大化它的 throughput。
而 NV 的 GPU 毕竟还要用作其他一些通用的运算,所以只能往原本的 SM 流水线里面插进去一些额外的专用部件 lane 了。开个脑洞,要是哪一天发现除了 FMA 以外还有其他另外一种形式的运算有大量的需求,未来的 GPU 设计里面说不定也会出现其他 xx Core。好在 FMA 除了深度学习以外在 HPC 的 workload 里面也是挺常见的,这个设计以后还是比较有用的。
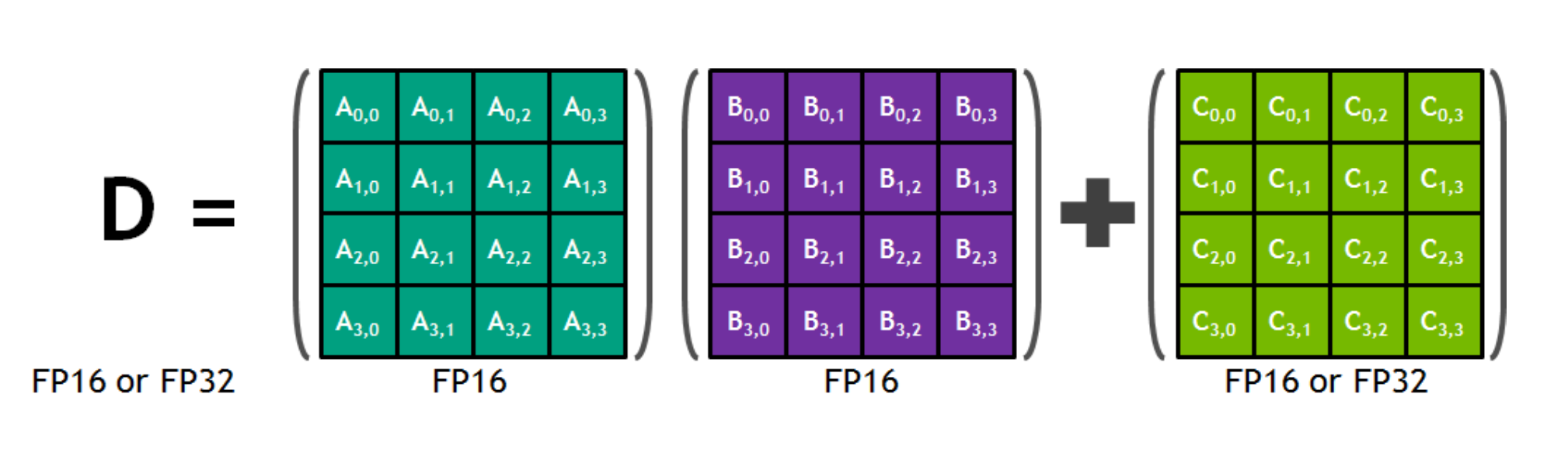
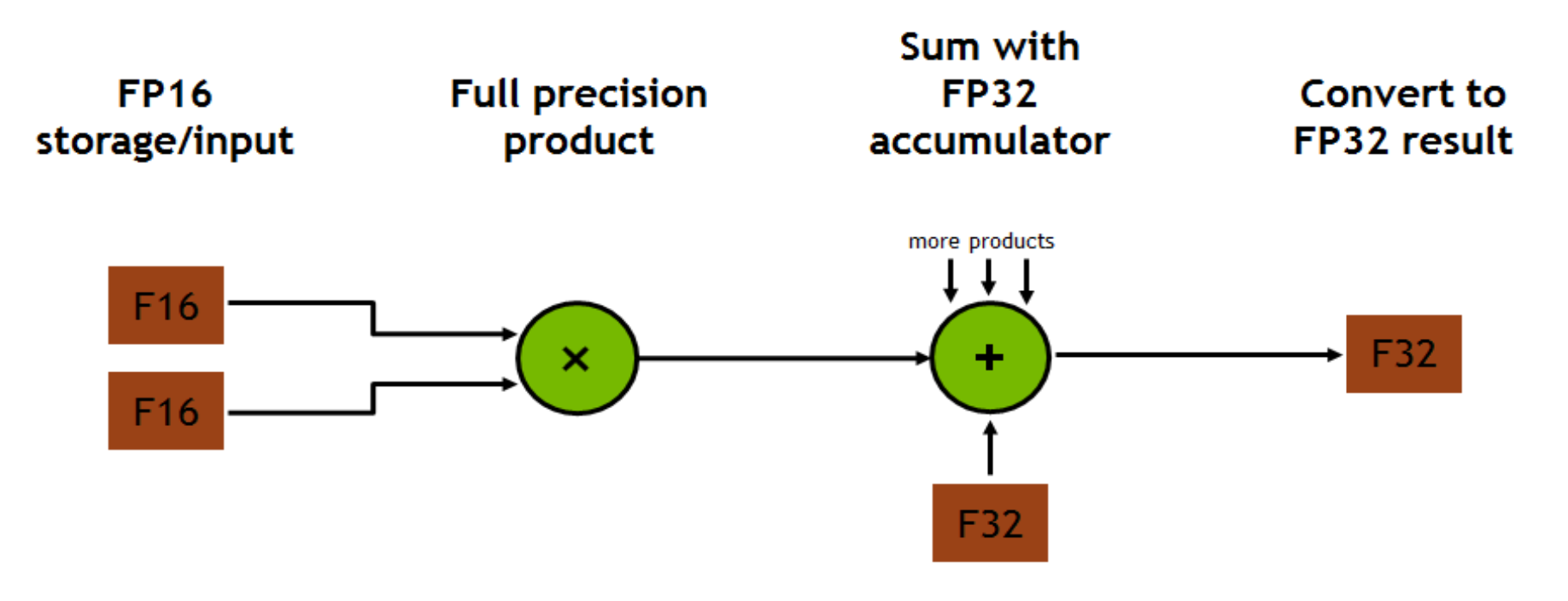
Tensor Core 这个部件直接从 SM 的寄存器里面取两个 FP16 的矩阵作为输入,进行全精度的矩阵乘之后得到的结果可以是 FP16 或者 FP32 的,然后累加到 FP16/FP32 的 accumulator 里面去。数据类型选择 FP16 作为输入然后输出 FP32 猜测可能是为了保证结果不溢出,然后在加速部件设计等等方面做了一些 trade off。
所以 FP16 in -> FP16 out 和 FP16 in -> FP32 out 哪一个性能更好呢…
我没有测过,但是猜测可能默认结果是 FP32 out 更快?反而是输出 FP16 需要从 FP32 再转一次?
接下来道理我们都懂了,那 Tensor Core 要怎么用呢?这个部件的编程模型在一开始接触的时候可能会有一些坑。
我们知道常规的 CUDA 代码需要制定 grid 的结构、block 的结构,然后其实我们写的 kernel 代码都是针对每一个单独的 thread 的,可以认为是 thread level 的编程。对一个子矩阵的 FMA 运算存在比较多的数据重用机会,这时候如果只是一个 thread 算一个矩阵块的 FMA 就比较浪费了,因此 Tensor Core 的设计是用一整个 warp 去共同完成一个 FMA 运算,一个 warp 中的 32 个 thread 可以复用寄存器里面的数据。CUDA 对 Tensor Core 的指南里面把这个叫做 “WMMA warp-wide macro-instructions”。所以 Tensor Core 的编程模型直接就是针对一整个 warp 写的。
事实上,Tensor Core 的代码写起来还是有相当多的限制的,CUDA 给 Tensor Core 提供了以下这些 c 的 API:
1 | template<typename Use, int m, int n, int k, typename T, typename Layout=void> class fragment; |
PTX 的指令应该更多一些,不过我没有详细看过。
首先用来做乘加的矩阵都需要放在这个叫 wmma::fragment 的变量里面,这个本质上就是定义了一个要放在 SM 寄存器上的存储空间,但是需要提供详细的 FMA 参数:
- 第一个参数
Use是这个fragment在 FMA 运算里面的角色,可选项有:matrix_a、matrix_b和accumulator,含义就是字面意思,也没什么需要再解释的了。 - m,n,k,T 是这一个 warp 里面要处理的的 FMA 子矩阵的形状以及数据类型,不同的 Capability 能够支持的组合还不太一样,比如最基础的就是 a、b 都是
__half,accumulator 是float,然后 m、n、k 都是 16。
m、n、k 的组合不是任意的,能支持的种类跟 Capability 直接相关,比如 V100 和后来出的 T4 能够支持的就不一样,具体可以在 Programming Guide 里面查。 - 最后这个
Layout可选项有两个row_major和col_major,代表这个fragment在内存里面实际存储的行列主序情况。
load_matrix_sync 和 store_matrix_sync 分别是把数据写到 fragment 空间里面和从这里面取出来写到别的地方去。fill_fragment 对 fragment 初始化。mma_sync 就是对整个 warp 调用 Tensor Core 去跑完这一个 FMA 运算了。
常规的写法也是先把矩阵 A、B 都 load 到 shared_memory 上,然后再从 shared_memory 里面取对应 FMA 块大小的数据到 fragment 里面,mma_sync 跑完,最后从 fragment 里面把结果写到外面去。
这里的注意点是上面这些代码(包括 fragment 定义以及下面几个函数的调用)都是针对 warp 的,即我们在写代码的一开始就需要考虑到每个 block 里面的 thread 结构,保证一个 warp 的 32 个 thread 执行的代码是完全相同的。相应地,对矩阵的分块也是需要在写代码的时候就考虑清楚,我们要保证每个 warp 处理的 a、b 矩阵的大小刚好是这个地方设定好的 m、n、k。
看起来确实相当麻烦,不过想想可能好像也还好,本来如果要写出性能很好的 CUDA 代码来,每个 warp 要算多少东西也是需要精细考虑清楚的。
SIMT Model Upgrade & COOPERATIVE GROUPS
Volta 这一代对 SIMT 的编程模型也做了改变。
在之前的 SIMT 流水线中,如果一个 warp 的指令里面出现了分支,这些分支块是不能被同时执行的。所以一直以来写 CUDA 代码都会要有一个原则是不要在一个 warp 里面出现不同的分支,要不需要花费两倍的时间去处理。
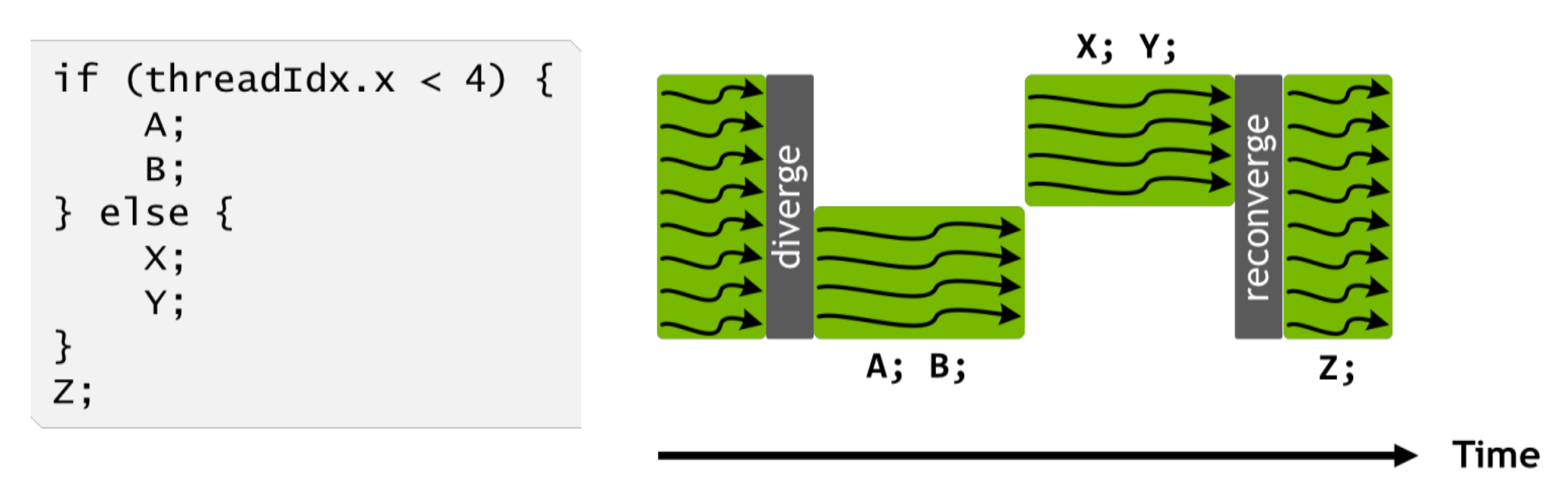
这一代开始把 PC 和调用栈做成了每个线程独立的:
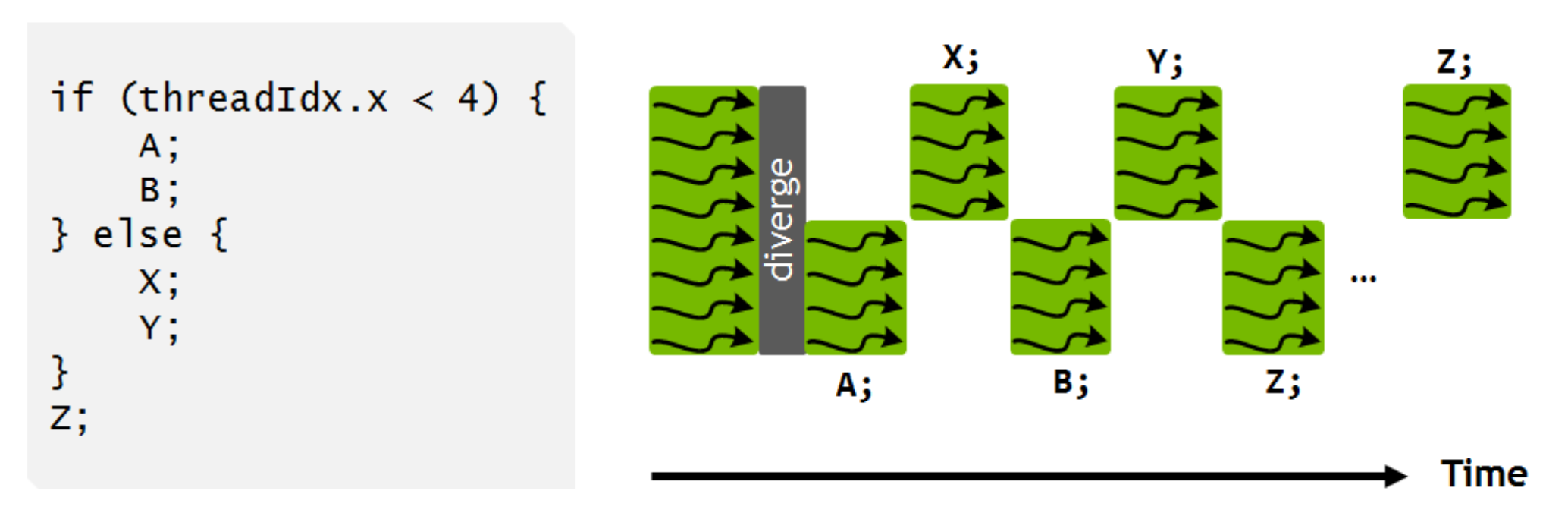
现在呢,每个分支里面的指令可以在更细粒度的层面上进行混合调度了,也可以手动插入一些在 warp 层面同步的指令进去:
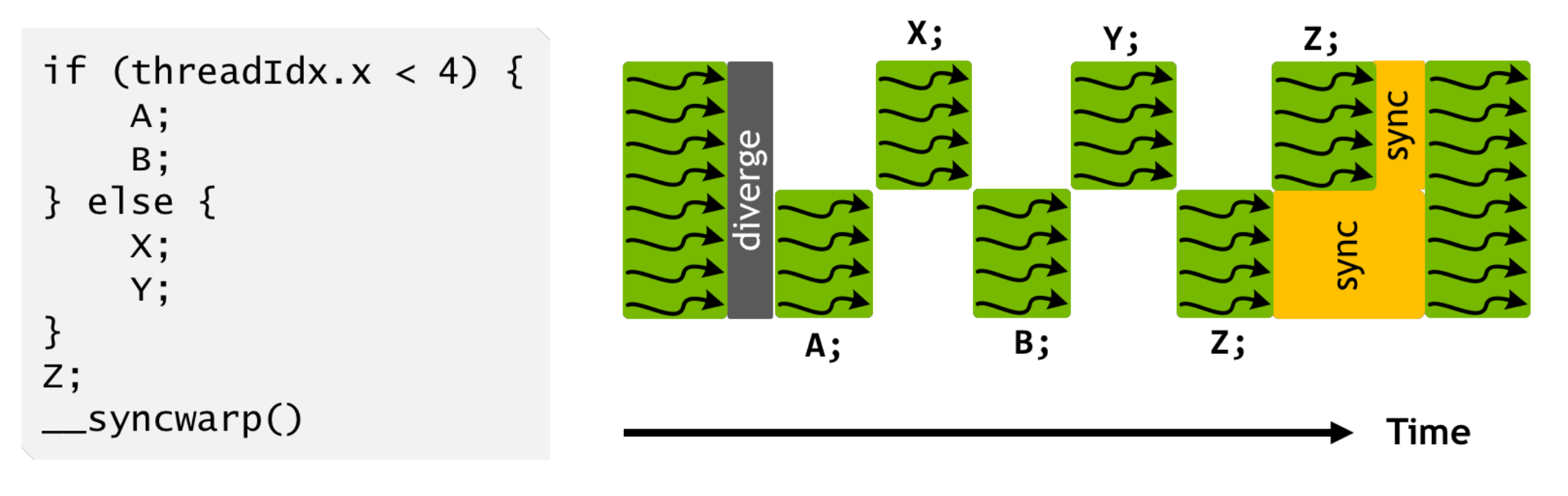
白皮书后面给了一个可以从这个改动上得到收益的 Starvation-Free Algorithms 的示例,修改带锁的双向链表的时候,不同 thread 可能会被 block 在锁上,以前的架构应该基本上不太可能能处理得了这种 case,新架构就保证了即使有些 thread 还在等待锁,另外的 thread 也有可能先拉出来跑。
可能也是因为这样所以 1 个 Dispatch Unit 配 1 个 Warp Scheduler 了?因为线程指令的实现事实上更加复杂了。
所以其实最后还是同时只能执行一个分支里面的一部分,这个 upgrade 我暂时还没有想到具体的应用场景会有多常出现(上面这个带锁双向链表我觉得写在 CUDA 里面就很不常见啊…),以及会具体有多少性能收益,说不定还是原本的那种简单的设计更直接更高效一些呢。(期待一下未来的硬件里面会不会把这个恢复回去……)
以前 CUDA 编程原则里面不要写分支的那条在新架构下我觉得还是适用的,不写分支就不会有这么多额外的麻烦要考虑了。
另外有一个 Cooperative Group 的新设计倒是看起来感觉更有用一些。原本的 __syncthreads( ) 是针对一个 block 里面的所有 thread 做同步的,现在可以对不同 block 的不同 thread 单独定义同步组了,CUDA launch 的时候会把同一个组的一起 launch 上去,同步可以在一个更加细粒度的层面上完成。
Turing
Compute Capability: 7.5(RTX 20x、T4)
这一代的改进看起来只是对 Volta 的小加强,Compute Capability 大版本号都仍然是 7。Tesla 计算卡系列只更新了 T4 这种推理卡,增加了 Int8/Int4 的推理能力,其他主要的设计更新重心都放在了像实时光追这种渲染能力上,让 Gforce 系列游戏卡的能力有了质的飞跃。
SM:
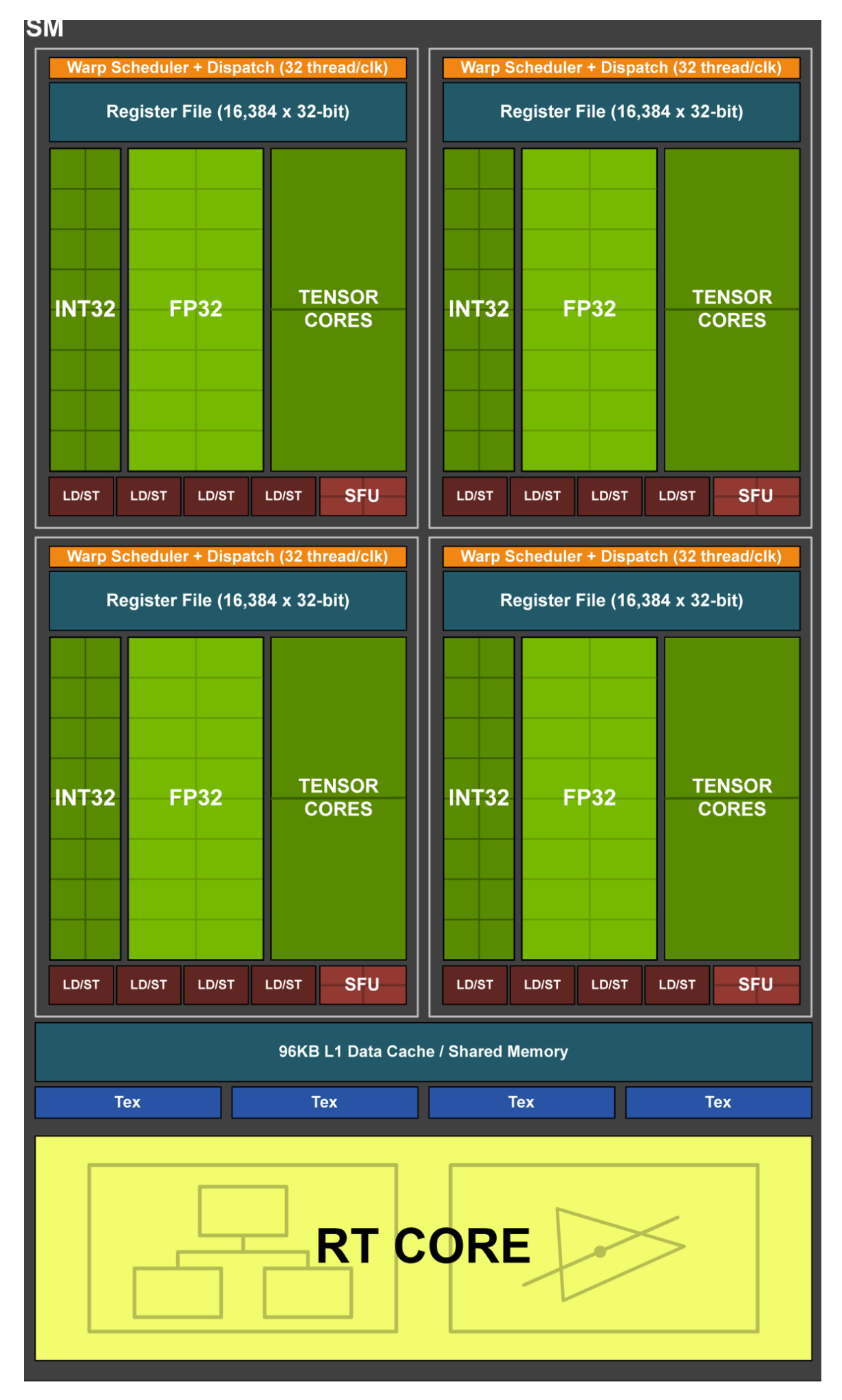
每个 SM 中一共有:
- 4 个 Warp Scheduler,4 个 Dispatch Unit
- 64 个 FP32 Core(4 * 16)
- 64 个 INT32 Core(4 * 16)
- 8 个 Tensor Core(4 * 2)
- 16 个 LD/ST Unit(4 * 4)
- 16 个 SFU
每个 SM 中有 4 个 Process Block,对于每一个 Process Block 来说有:
- 1 个 Warp Scheduler,1 个 Dispath Unit
- 16 个 FP32 Core
- 16 个 INT32 Core
- 2 个 Tensor Core
- 4 个 LD/ST Unit
- 4 个 SFU
相比原本的 Volta SM,可以看到 FP64 又被去掉了,LD/ST 单元砍半。(是不是因为 Turing 系列没有打算出 T100 这种大卡,而推理和渲染对 FP64 以及访存的需求没有那么大?)
Tensor Core 部分相比 Volta 的初代设计增加了 Int8 和 Int4 支持。且毕竟占了很大一块芯片面积,Tensor Core 现在除了 AI 场景以外在这一代开始也能够在游戏和渲染中用上了,Turing 支持 Deep Learning Super Sampling(DLSS)深度学习超采样技术,看名字应该是通过神经网络进行视频插帧。
其他的提升主要集中在渲染管线和新加的这个 RT Core 光线追踪能力上,这里就跳过了。
Ampere
Compute Capability: 8.0(A100、A30), 8.6(RTX 30x、A40、A16、A10、A2), 8.7(Orin)
算是又一个大版本更新:
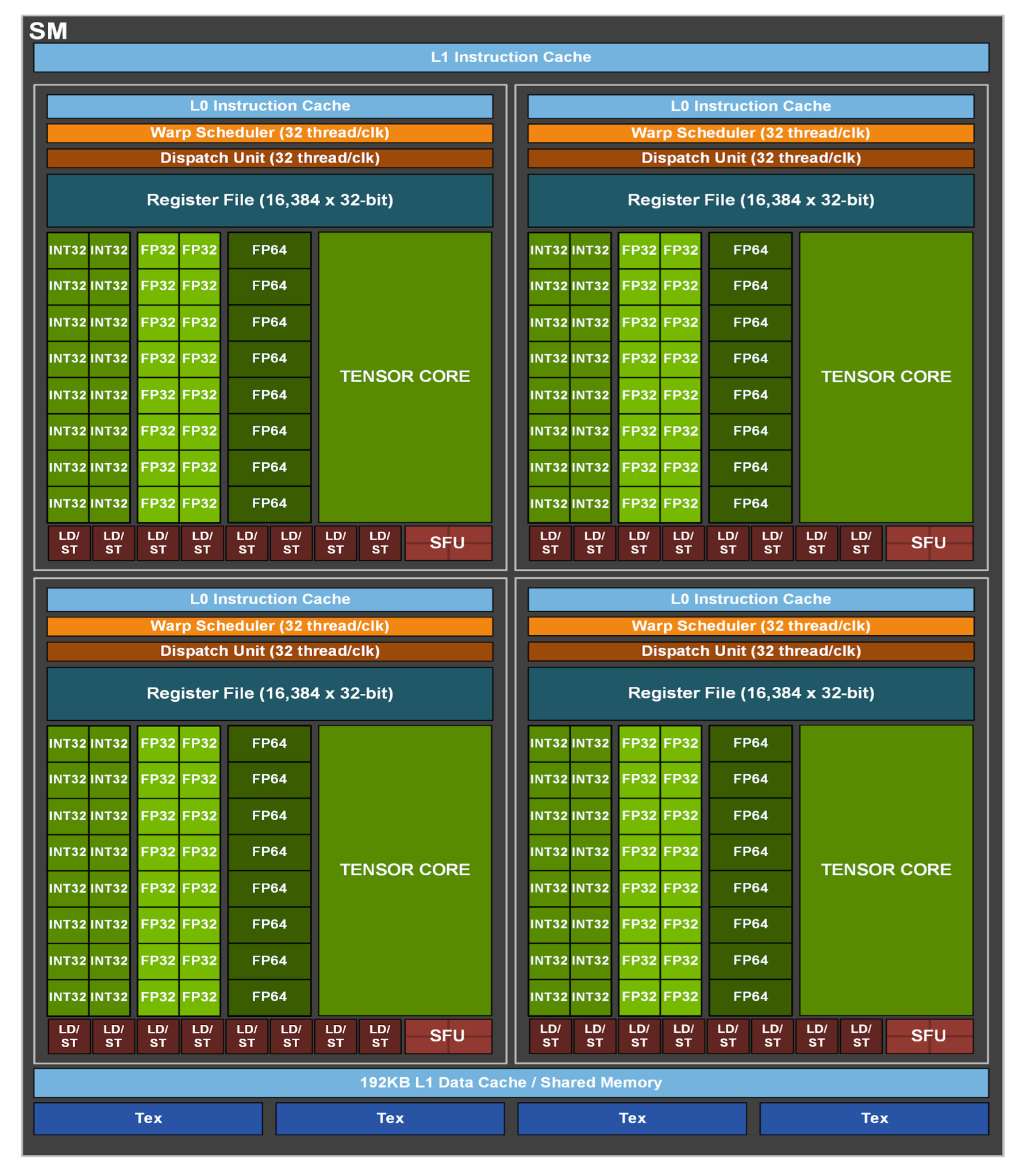
还是先来看下 SM 的结构:
- 4 个 Warp Scheduler,4 个 Dispatch Unit
- 64 个 FP32 Core(4 * 16)
- 64 个 INT32 Core(4 * 16)
- 32 个 FP64 Core(4 * 8)
- 4 个 TensorCore(4 * 1)
- 32 个 LD/ST Unit(4 * 8)
- 16 个 SFU(4 * 4)
每个 Process Block:
- 1 个 Warp Scheduler,1 个 Dispatch Unit
- 16 个 FP32 Core
- 16 个 INT32 Core
- 8 个 FP64 Core
- 1 个 Tensor Core
- 8 个 LD/ST Unit
- 4 个 SFU
从单元数量上来看,Ampere 跟 Volta 是基本一致的,也有 FP64 的核心。把 Volta、Turing、Ampere 三代放在一起比就有种 Tik-Tok 的感觉出来了 … 每一代大卡通过工艺升级压进去更多的计算单元,FP64 和 LD/ST 单元的数量都是拉满的,然后会有一个小改款出不带 FP64 的推理卡以及专注提升图像性能。
这一代比较大的改进在 Tensor Core 以及各个部分的 memory 工作效率上。
唯一的区别是 Tensor Core 的数量相比上代减少了一半,但可不要觉得 Ampere 的性能因此就下降了。
Volta/Turing 中的每个 Tensor Core 每个 cycle 可以执行 64 个 FP16/FP32 的混合精度 FMA 计算,而 Ampere 中的 Tensor Core 虽然数量减少了,但是每个的内部都堆了更多的料,单 cycle 的吞吐量提升了 4 倍到 256 个 FMA。一来一回,单个 SM 的 Tensor Core 计算能力还是提升了两倍。
Tensor Core 可以支持的数据类型扩展到了 FP16、BF16、TF32、FP64、INT8、INT4 甚至是 Binary。(TF32 的数据类型是为了能够更好地支持 FP32 的 Tensor Core 计算)
另外一个最大的改进在于 NV 给 Tensor Core 增加了一种特殊的结构化稀疏运算能力:
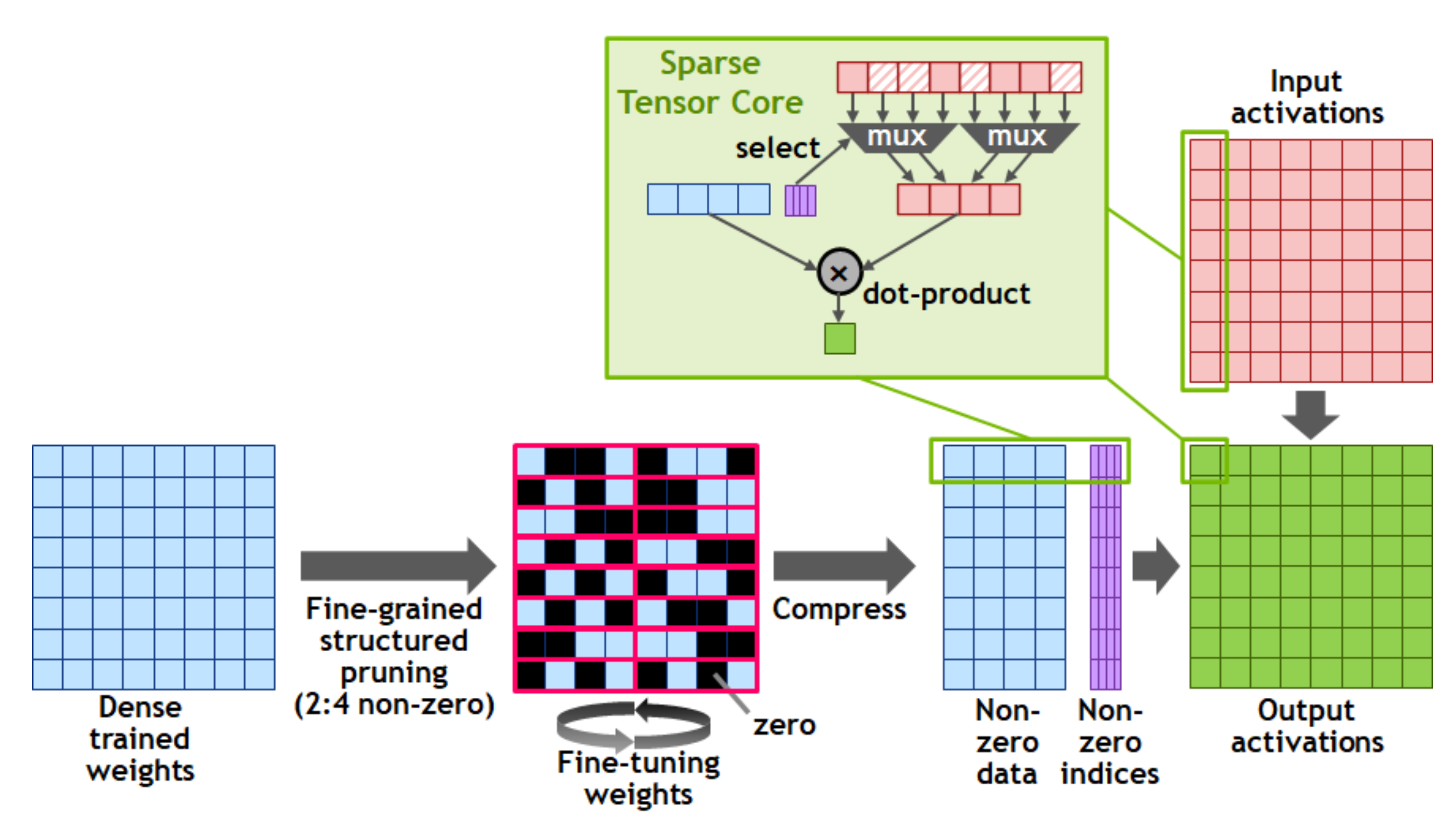
网络中训练出来的 Weight 通过预处理以 2:4 的压缩比处理成一个稀疏矩阵的结构,每 4 个数据块精简掉 2 个块。可以看到这个结构跟通常的 BSR、CSR 等稀疏存储结构是完全不同的,压缩好的系数矩阵的数据量变成原来的一半,然后再加一个标记了 2:4 稀疏位置的 indices 矩阵,估计是需要用 CUDA 自己的稀疏处理 API 来做到。
上图中也比较清楚地解释了 Tensor Core 的稀疏计算原理,indices 矩阵通过两个选择器直接把输入数据的对应位过滤出来,然后做点乘。
很有意思的是白皮书在这里给了一张细化到每个点上的性能对比图:

一连串的翻倍提升看起来确实挺吓人的。首先 Tensor Core 在本身吞吐量以及 A100 的总 SM 数量上综合有 2.5 倍的硬计算能力提升,如果用上稀疏计算,则吞吐量可以再涨一倍到 5 倍。各级 Memory 之间的访存带宽以及容量也有了大幅提升。
接下来,之前 Volta 上 Tensor Core 只能在一个 warp 的 8 个线程间共享数据,现在这个共享范围扩展到了整个 warp 的 32 个线程,计算时对寄存器的访存可以减少 2.9 倍。Ampere 上还增加了一个新的异步访存指令,之前从 Global Memory 拷贝数据到 Shared Memory 其实是要先经过寄存器中转的,现在可以直接 bypass 寄存器了进行异步数据拷贝了。
剩下的几个看上去倒是并没有太 promising 的样子:
- Residency Controls:通过算法上增加复用来减少内存使用量提高计算时内存利用率的优化,可以减少数据的搬运次数,进一步提高性能。(这个 6.7 感觉有点夸张了,不知道是不是针对特定 workload 做的专门优化才能达到这个效果)
- Data Compression:为了有效利用访存带宽,Ampere 上甚至可以在数据搬用过程中进行 2~4 倍的数据压缩。(这个看起来就更玄乎了……)
Conclusion
| Ampere | Turing | Volta | Pascal | Maxwell | Kepler | Fermi | |
|---|---|---|---|---|---|---|---|
| Process Block | 4 | 4 | 4 | 2 | 4 | 1 | 1 |
| Warp Scheduler | 4 4 * 1 |
4 4 * 1 |
4 4 * 1 |
2 2 * 1 |
4 4 * 1 |
4 | 2 |
| Dispatch Unit | 4 4 * 1 |
4 4 * 1 |
4 4 * 1 |
4 2 * 2 |
8 4 * 2 |
8 | 2 |
| FP32 Core | 64 4 * 16 |
64 4 * 16 |
64 4 * 16 |
64 2 * 32 |
128 4 * 32 |
192 | 32 |
| INT32 Core | 64 4 * 16 |
64 4 * 16 |
64 4 * 16 |
||||
| FP64 Core | 32 4 * 8 |
32 4 * 8 |
32 2 * 16 |
64 | |||
| TensorCore | 4 4 * 1 |
8 4 * 2 |
8 4 * 2 |
||||
| LD/ST Unit | 32 4 * 8 |
16 4 * 4 |
32 4 * 8 |
16 2 * 8 |
32 4 * 8 |
32 | 16 |
| SFU | 16 4 * 4 |
16 4 * 4 |
16 4 * 4 |
16 2 * 8 |
32 4 * 8 |
32 | 4 |
| Register File 32bit | 65536 4 * 16384 |
65536 4 * 16384 |
65536 4 * 16384 |
65536 2 * 32768 |
65536 4 * 16384 |
65536 | 32768 |
| L1 Cache/Shared Memory | 192K | 96K | 128K | 64K | 96K | 64K | 64K |