
逛知乎的时候发现的这个问题:
一开始只是觉得这个名字熟悉(脑子里面冒出来的是 Tarjan 离线 LCA),点进去一看越看越心惊。
强连通分量?哦,那个经典算法好像确实叫 Tarjan。LCT 动态树…卧槽他写的?斐波那契堆…卧槽他写的?Splay 伸展树…卧槽他写的?
从 1971 年至今,Tarjan 大佬大概发了 300 篇左右的论文,还在不断产出,他创造了一堆图论、树结构上的经典算法,还获得过 1986 年的图灵奖。
后面准备把他的一些经典算法都重新过一遍,看看他的原著论文什么的。
我知道的几种算法/数据结构:
Tarjan 双连通分量 & 强连通分量
【1972 - Depth-first search and linear graph algorithms】
Google 学术引用数 6049。
这篇论文似乎可以算是 Tarjan 的开山之作,其中提到了图上 DFS 序的一些重要特性。
论文里面直接提出了经典的无向图点双连通分量算法和有向图强连通分量算法。Tarjan 的这两个算法都是基于 DFS 栈的。
首先是割点的概念:一个连通图中,如果删掉一个顶点,整个图变成了两个连通图,则该顶点叫割点。
点双连通分量就是一张图中不含有割点的子图(块)。
论文中给出的 Tarjan 点双连通的过程大致是这样:
dfn 是 DFS 过程中访问节点的顺序(或者说时间戳?),low 是 DFS 过程中,某个点能够连接到的栈中的最底层的点。DFS 栈中存边。
1 | void tarjan(int x,int fa) |
有向图的强连通分量,我以前用的一直是 Kosaraju 算法,配合时间戳正反两次 DFS。Tarjan 的强连通分量算法跟双连通非常像,大致是这样的:
dfn 和 low 的意义相同,DFS 栈中存点。
1 | void tarjan(int i) |
嗯,看这篇论文的时候有点在看《算法导论》的感觉,证明、推理过程都非常严谨(虽然我从不看证明)。
【1973 - Algorithm 447: efficient algorithms for graph manipulation】
Google 学术引用数 795。
文中用流程图描述了找连通分量、找双连通分量、把图划分成多个简单路径的算法,大致的想法跟上面那篇 DFS 基本是一致的。划分简单路径要在双连通分量的基础上做。
Tarjan 离线 LCA
【1979 - Applications of path compression on balanced trees】
Google 学术引用数 356。
额…在 Google 学术上下到的 1979 年版是个迷之影印版,另外搜到个写着 1975 年的版本,感觉过去太多年以后,论文的时间确实都有点乱了。
看到这篇论文的标题“路径压缩”首先想到的是并查集,论文里面开头确实也提到了前人写的有关“等价问题”的算法,估计跟并查集有点关系。
文章一开始是一堆图和树的定义,然后定义了一个树上求值和构造的操作。求值是定义一个函数 eval(v) 计算从当前节点到根节点的某种数值关系,构造 link(v, w, x) 连接两个节点,树边长度是 x。由于这里求值函数的定义是从当前节点算到根节点,因此是有个结合律在里面的,所以可以用到路径压缩。
论文这里讲的路径压缩的思路大概跟并查集(关系传递)和线段树(lazy标记)里面用到的方法类似。嗯,跟线段树对比可能还不是很一致,线段树算是自顶向下求,这里应该是从当前节点一直向上求。
果然,文章的第 4 部分讲到了 2 个这套方法的算法应用:并查集和 LCA。
并查集没啥好说的,这里重点要说的 Tarjan 的离线 LCA。
为什么要特别指出是“离线”的 LCA 呢?看完算法的整个过程就知道了:
Tarjan 的 LCA 用 DFS 来遍历整棵树,并且依靠并查集来完成线性时间的查询。
- 首先对所有的 LCA 询问进行排序,交换
{vi, wi}使得vi <= wi - 然后在树上把所有的 wi 标记出来
- 之后在图中开始 DFS:
- 找到一个带标记的节点 wi,则对应的 vi 肯定已经事先访问过了(排序的作用),直接返回
getfather(vi)就是它们的 LCA 了 - DFS 回溯时,将当前节点并进父节点的集合中
- 找到一个带标记的节点 wi,则对应的 vi 肯定已经事先访问过了(排序的作用),直接返回
这个算法要求 LCA 询问事先得到,并且之后树的结构肯定是不能再改变的,所以是个离线算法。
参考这里的一个 Flash 动画演示可能会更清楚一点。
后文暂时没再往下看了,基本讲的是 eval 和 link 这两个操作的扩展玩法,甚至还有验证最小生成树的用途(?),应用面看起来还是非常不错的。
Link/Cut Tree 动态树
【1981 - A Data Structure for Dynamic Trees】
Google 学术引用数 1069。
我之前知道的动态树算法是跟 Splay 配合用的,更进阶的还有树链剖分跟这个也有点关系,前面在这里记过两道题。不过论文顺序上居然是 LCT 先写的。
摘要部分介绍了这是一种用于维护一个由若干棵不相交树组成的森林的数据结构,主要有link和cut操作来连接两棵树或者把一棵树拆成两棵。当然复杂度是非常优的,保证在O(logn)(复杂度太高的话就没有意义了)。
应用方面,摘要提到了 LCT 可以求:
- LCA 最近公共祖先
- 多种网络流问题,包括最大流等等(!)
- 某些特殊情况下的最小生成树(!)
- 某种最小费用流的简化算法(?)
如果单纯地只是要实现这样的数据结构,难度不是很大,直接模拟就好,最简单粗暴的实现也可以达到link和cut这样的操作在O(1)时间内完成,但是树上的其他查询操作就可能要花上O(n)(那就没有意义了)。
所以还是得想个办法解决具体实现的问题。
Tarjan 的高效实现不直接存树的原始结构,而是把整棵树按照路径集合的方式来维护。论文第三章是对这种转化的复杂度证明,保证 m 个对动态树的操作可以转化成O(mlogn)个对路径集合的操作。然后第四章接下来讲如何用二叉树来维护这个路径集合,话说这部分才是这个算法的核心实现吧。
嗯,我现在所知道的 LCT 的实际基本都是基于 Splay 的,话说论文里面后面这部分写到的二叉树实现中的左右旋等等的操作看上去就已经是 Splay 的雏形了,不过 Tarjan 的 Splay 论文是发在这一篇之后的,可能后面还有经过更多的改进或者验证吧。
这段暂时跳过,直接看看现代经过后人补充修正过的 LCT 是怎么实现的好了:
(OneDrive 上共享的,可能链接会被墙,不过在网上用这个标题应该也能搜到对应的文章。)
QTREE 一文中的Preferred Path跟 Tarjan 论文中的Solid Path应该是一致的。这里的核心操作是Access(v),访问 v 这个节点所经过的路径就是这次访问所产生的Preferred Path,LCT 算法就是把原本的树结构转化为维护这样的一些Preferred Path集合,树本身是可以分解成一堆Preferred Path的,只需要再知道这些路径之间的连接关系,就可以表示出这棵树了。Preferred Path保存在 Splay 上,Splay 就是 LCT 这个数据结构的辅助树(Auxiliary Tree)。
所以 Preferred Path 和 Auxiliary Tree 这俩名字是哪来的呢?。。。Tarjan 的论文里面好像没出现这两个词。
QTREE 文中对 LCT 的定义:
Link-Cut Trees 就是将要维护的森林中的每棵树 T 表示为若干个 Auxiliary Tree, 并通过 Path Parent 将这些 Auxiliary Tree 连接起来的数据结构.
比较尴尬的是这里的实现确实都是要基于 Splay 来理解了,所以先跳一步,重新来复习一下下面的 Splay 先。
有了 Splay 之后,接下来 LCT 的操作就很简单了。前面说过,LCT 的核心操作是 Access()。
以 QTREE 一文中的例子来解释(找不到什么比较好的画图工具,只好手画了):
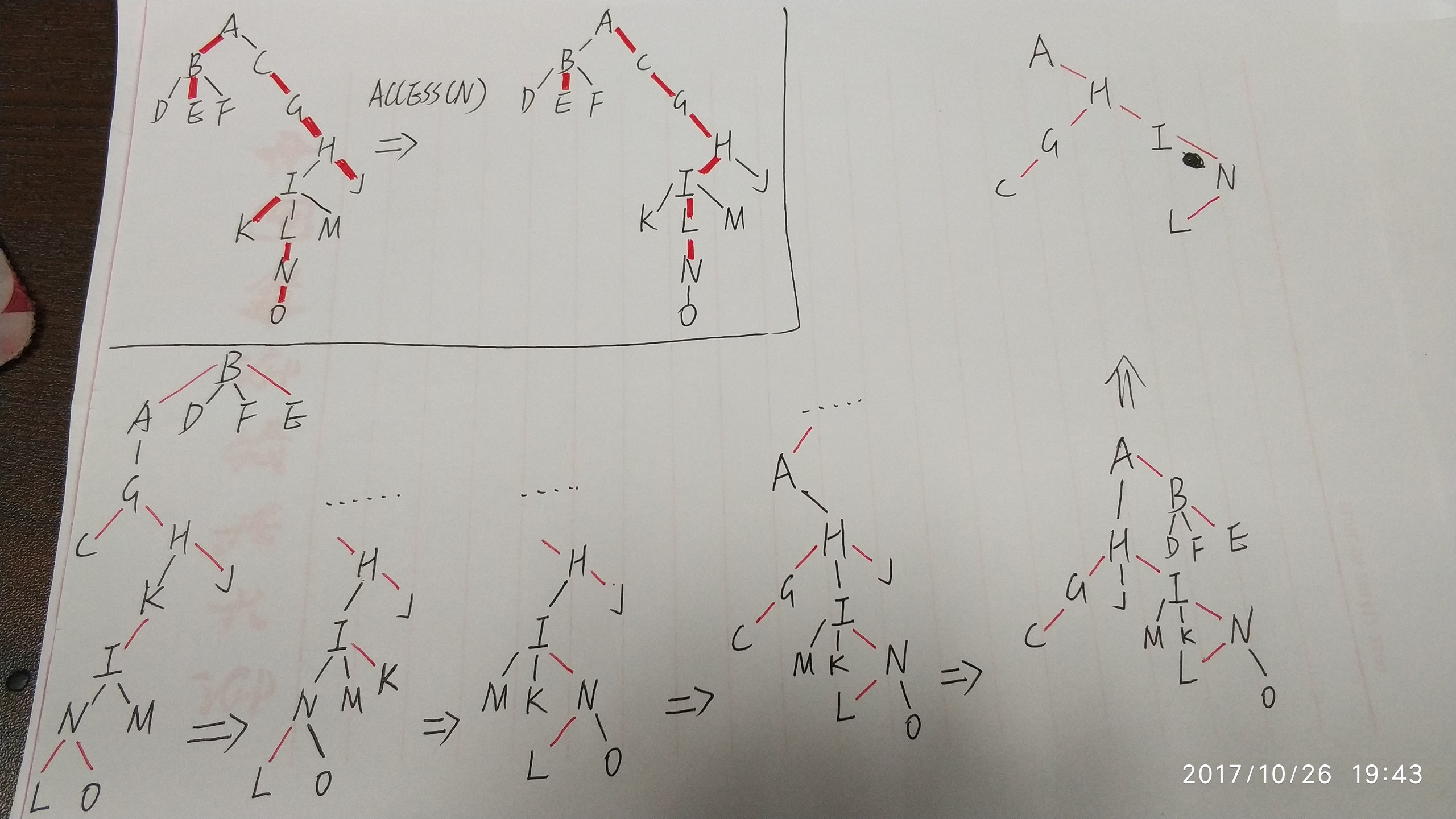
LCT 存储的是树结构上的 Preferred Path,例如对左边的树进行 Access(N) 操作之后,从根节点 A 到目标节点 N 就形成了一条 Preferred Path,跟这条路径上的点相连的原有的 Preferred Path 都恢复成普通边(例如 A-B 和 N-O 都从 Preferred Path 恢复成了普通边)。
我们把 Preferred Path 存储在 Splay 森林上,然后每次 Access 操作之后对 Preferred Path 进行的修改则相应地需要依靠 Splay 来进行维护。
左下角的这棵树就是 Access(N) 操作前的 Splay 森林的结构,红边是 Splay 的树边,黑边是两棵 Splay 树的连接关系。这里其实一共有 7 棵 Splay 树:ABE,D,F,CGHJ,IK,LNO,M。可以看到每一棵 Splay 实际上表示的是一条 Preferred Path 或者单个节点,Preferred Path 在原树中的深度就是对应的 Splay 中节点的索引值(!!这个对理解很重要)。
然后访问 Access(N) 会发生什么呢?
- 把 N 旋转到它的 Splay 的根,然后断开 N 和右子树的连接
- 检查 N 的父节点 I,把 I 旋转到它的 Splay 的根,然后断开 I 和右子树的连接,把 N 接到右子树上
- 检查 I 的父节点 H,把 H 旋转到它的 Splay 的根,然后断开 H 和右子树的连接,把 I 接到右子树上
- 检查 H 的父节点 A,把 A 旋转到它的 Splay 的根,然后断开 A 和右子树的连接,把 H 接到右子树上
- 检查 A 已经没有父节点了,结束
然后我们就得到了右上角这棵 Splay 树,因为经过了 Splay 操作的维护调整,可能最终具体的形态不是这样的,但这棵树上的所有节点就是这 7 个。其他节点也还在,不过这里没画出来了。
有了 Access 之后,接下来我们有了 3 个进一步的操作:
FindRoot(N):找到 N 所在的树的根节点
首先 Access(N),根节点就是 N 所在的 Preferred Path 的最顶端的那个点了。把 N 旋转到它所在的 Splay 的根,然后向左走到底就是整个树的根了。
Cut(N):把 N 连同它的子树从它所属的原有的树中切出来
首先 Access(N),把 N 旋转到它所在的 Splay 的根,然后断开 N 和它左子树的连接。
Link(N, M):把 N 这棵树连接到 M 这个节点下(N 是树根,且 N 和 M 不在同一棵树中)
首先 Access(N),把 N 所在的 Splay 的根节点的父节点设成 M,然后再 Access(N)。
然后我们来思考一下 LCT 能干嘛。其实 Splay 本身已经是一种具有切分、组合能力的动态树结构了,但是从上面这个例子的描述中,我们也能很直观地发现,Splay 只能最多处理到二叉树的动态变化,而 LCT 可以处理多叉树的动态结构。
QTREE 文中最初给出的目标题目是:
给一棵共有 n 个结点的树, 每条边都有一个权值, 要求维护一个数据结构, 支持如下操作:
- 修改某条边的权值;
- 询问某两个节点之间的唯一通路上的最大边权。
第二个问题就是很直观的一个 LCA,关键在这个最大边权上。
首先来看用 LCT 怎么求两个点 N 和 M 的 LCA:首先还是 Access(N),然后下一次做 Access(M) 时,由于 Access 一直在反复找父节点旋转到根,当最后一步找到的最顶层的 Splay 就是 N 所在的 Preferred Path,所以此时 Splay 的根就是 N 和 M 的 LCA 了。
边权的处理:每个节点记录到它的父节点的边的边权,同时记录以它为根的 Splay 树中所有节点的最大边权值。最大边权值是满足结合律的,在 Splay 旋转的过程中注意维护即可。
然后是 LCA 的过程中,假设 N 和 M 的 LCA 是 L。Access(M) 的最后一步需要把 M 所在的 Splay 树接到 L 的右子树上,L 原来的右子树的最大边权值就是 N 到 L 的最大边权值,L 新接的右子树的最大边权值就是 M 到 L 的最大边权值,取这两个中的最大值即可。
HDU 2475 BOX 是一道裸的 LCT 题,把树的从属关系对应到盒子的包含关系上。
HDU 3966 Aragorn’s Story 一次性修改一条路径上所有点的权值,也是与 LCA 有关。
所以总结下来,LCT 可以处理多叉树的动态变化,以及与树上路径相关的一些操作(涉及到在线 LCA 的可能都能用 LCT 做吧?)。
Tarjan 论文中把 LCT 应用在网络流上也是一种创新的做法了,不过奇怪的是复杂度低为什么 OI 里面几乎从来没听说过有人这么解的呢?有待以后继续挖掘思考。
Splay 伸展树
【1985 - Self-Adjusting Binary Search Trees】
Google 学术引用数 1375。
论文首先介绍了 Tarjan 提出这种平衡树的出发点:虽然其他平衡树的实现,例如height-balanced trees、weight-balanced trees等等等最差情况下的复杂度都能有O(logn),但实际使用中出现的访问不会这么均匀,而且这些实现都需要额外的信息来维持整棵树的平衡性,所以其实并不是一直这么高效(求验证)。
Tarjan 认为应该关注于一堆操作序列的均摊时间,而不是关注于某个最坏情况的时间。所以 Splay 的设计有几个特点:
- 均摊情况下不要太考虑平衡树的常数问题(话说 Splay 的常数还真的挺大的)
- 节省内存,不要记录一些没用的平衡信息,这样可以节省一些操作的时间
- 访问和更新的操作要简单,易于实现
带来的后果就是,根据这个思想实现出来的 Splay:
- 需要更多的局部调整,通常一般的平衡树只是在修改的时候需要调整结构,而 Splay 在访问的时候就要对树的结构做改动了
- 单个操作可能会很费时(话说,最坏情况下 Splay 是会退化成
O(n)的链的。。。)
Splay 的核心是splaying操作,即把最近访问过的顶点放到树根,以此来达到访问均摊时间相对较优的效果。论文里面还提到了用 Splay 来实现字典搜索树和多维搜索树以及 LCT 的应用。
Splay 的思想其实特别简单,实现方面我在以前写 Splay 题的时候基本上也是先参考的其他人的模版改的。杨哲的 QTREE 论文中提到了他对 Splay 实现方面的思考和优化,准备按照他的介绍试着改改看我以前的代码。
。。。然后很尴尬的是好像失败了。光从代码结构上来看 QTREE 论文中的 Splay 代码确实要少好多行,结果按照他的伪代码改起来有点小问题,跟我原本的代码对不上,有待后续再看看,暂时情况下,我原本的 Splay 模板已经够用了。
把被访问的顶点放到树根这件事情实现起来有很多种方式,而 Splay 中比较特别的是限定了几种特定的旋转规则(花式旋转):
p(x) 指 x 的父节点。
- zig
p(x) 是根节点。则直接旋转 x 和 p(x)。(一次左旋或者一次右旋) - zig-zig
p(x) 不是根节点,同时 p(x) 是其父节点的左节点且 x 也是 p(x) 的左节点,或者 p(x) 是其父节点的右节点且 x 也是 p(x) 的右节点。则先旋转 p(x) 和 p(x) 的父节点,再旋转 x 和 p(x)。(两次左旋或者两次右旋) - zig-zag
p(x) 不是根节点,同时 p(x) 是其父节点的左节点且 x 是 p(x) 的右节点,或者 p(x) 是其父节点的右节点且 x 是 p(x) 的左节点。则先旋转 x 和 p(x),再继续旋转 x 和 p(p(x))。(一次右旋一次左旋或者一次左旋一次右旋)
具体的图可以见论文。
这样做的好处是,经过 Splay 操作之后,不仅仅是成功把 x 节点移到了树根,同时还把树根到 x 节点的路径降低了一半的深度(这个很关键!)。这部分的算法证明我就没看了,默默地跳过。
得益于 Splay 相比常见的普通平衡树的优点,就是它的灵活性(也可能是缺点,这也导致了事实上 Splay 并不是那么…额,平衡),Splay 可以做出两个一般平衡树很难实现的操作:join(t1, t2) 和 split(i, t)。
join(t1, t2) 是把两棵 Splay 树合成一棵,当然这里需要假定 t1 中的所有元素都比 t2 中的要小。实现是访问 t1 中最大的元素,这样这个元素就到了树根并且右子树是空的,把 t2 接到右子树的位置上即可。或者访问 t2 中最小的元素,把 t1 接到左子树的位置上。
split(i, t) 把 Splay 中小于 i 的所有元素切出来。实现也很直观,找到元素 i 旋转到树根,然后把左子树切出来就好了。
NOI2004 郁闷的出纳员 就是典型的平衡树性质加上
split操作的应用。
然后 Splay 的单个元素插入和删除也可以有两种实现:类似一般平衡树的做法,或者基于上面的 join 和 split 操作。
嗯,我以前的写法都是按普通平衡树那样写的,据论文上的说法,特殊实现能有更好的均摊时间边界:
insert(i, t),做一次 split(i, t),然后把切出来的两棵 Splay 分别接到新节点 i 的左右子树上去。
delete(i, t),在树 t 中访问节点 i,把它旋转到根,然后把根的左右两个子树 join 在一起。或者先把 i 的左右子树 join 在一起,再把 i 的父节点旋转到根。
HDU 1890 Robotic Sort 是删根操作加上线段树 lazy 标记方法的应用。
HDU 3487 Play with Chain 是spilt和join操作的综合应用,这里还用到了不仅仅是要切出小于某个值的部分,而是要切出一个区间范围内的值,同时也涉及到了 lazy 标记的应用。算是相当综合了。
看完 Splay 之后,再回到上面继续 LCT。
持久化数据结构
【1986 - Making Data Structures Persistent】
Google 学术引用数 806。
持久化数据结构的定义是:经过多次修改之后,还要能保证在任何时候都能得到到该结构的任何版本(不管是老的还是新的)。听上去很玄。。。
大致的做法是在原有的数据结构上增加一些额外的信息域,然后修改内容时保留原有的不变,增加新节点等等。例如持久化的二叉树,增加节点时,保留原有的不变,把原本的节点复制一份增加新节点等等,做好标记。
具体的操作、实现等等,先留待以后看了。
关于持久化数据结构,CLJ 和 FHQ 两位大佬也整理过一些东西:
斐波那契堆
【1987 - Fibonacci heaps and their uses in improved network optimization algorithms】
Google 学术引用数 2943。
这个也先留着吧,可以参见《算法导论》上的章节。