
Node.js 现在已经发展成一个很强大的框架了,像 Hexo 这样的博客系统、Visual Studio Code 这样的文本编辑器、甚至Steam客户端(?)等等都是用这个写的。还有一堆,哪哪都是 Node。
很早就想学一下这玩意,结果各种事情一直拖着。
考完试终于有时间可以瞎折腾了。
记一下学 Node 的时候遇到的一些坑点。
Learning
我的学习路线大概是这样,找个 Node.js 写的爬虫的示例照着写,写完就学会了怎么写爬虫,顺便就把 JavaScript 和 TypeScript 的基本用法学会了。(理想情况)
实际情况大概是其中会遇到一些问题,那么再针对性地解决好了。(例如 Node.js 里面的异步逻辑)
然后,被异步这块绕的不行,所以干脆找了个对 Node.js 底层实现的分析。了解整个运行原理之后应该就好了。
参考资料:
下面记的好多东西都来源于上面的 深入理解Node.js。
Node.js 的整体架构:
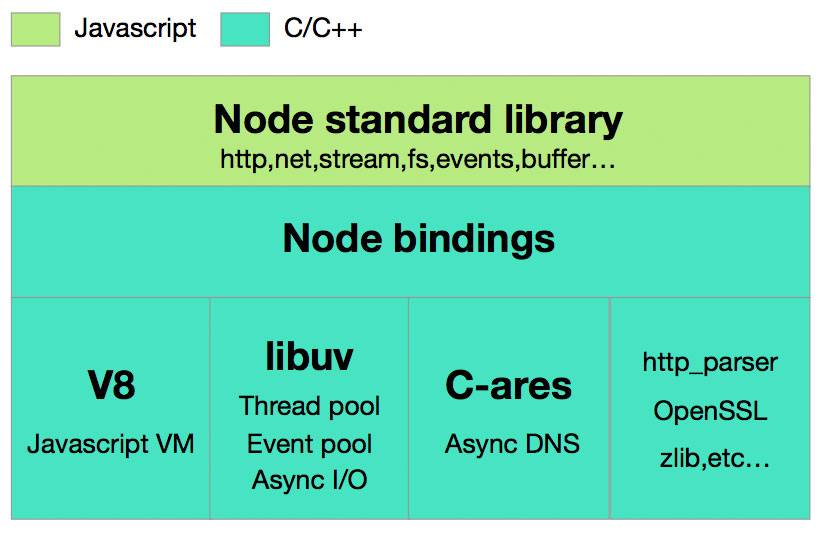
底层是 C/C++ 写的,所以 Node.js 的代码跑起来会比 Python 这样的脚本语言要快很多。
异步

Node.js 是一个单线程的事件驱动的异步系统。
Node.js 本身的 API 里面有同步函数也有异步函数,简单地说整个调度过程是这样的:
- JavaScript 线程启动,宿主环境创建堆和栈。堆用于存储 JavaScript 对象,栈用于存储执行上下文,当然每个异步函数都有一个对应的执行上下文,可以理解成一个函数要执行就要进栈。
- 栈内执行任务的顺序是同步的,跟 C/C++ 等等其他非异步的完全一样,自顶向下按顺序来,执行完退栈。当异步任务要执行时,异步任务不入栈,而是把相关消息通知线程(大概是把自己的信息注册到线程上去),然后进入等待状态。
- 当(前面注册过的异步任务对应的)事件被触发或者异步响应返回时,线程向消息队列插入一条事件消息。
- 栈内的同步任务先全部执行完,然后线程从消息队列取出一个事件消息,事件消息对应的异步任务入栈,如果消息上面绑了回调函数那就执行它。
- 当执行栈空了,就再从消息队列取出下一个事件消息,然后继续执行。这个就是事件循环。
关于单线程,从 深入理解Node.js 里面对事件部分的源码分析也可以很清楚地看到,事件循环的核心部分代码就是个简单的 do-while 循环。
异步则是因为 Node.js 底层用了 libuv,下面的事件消息通知是异步驱动的。(所以相当于整个调度是单线程的,而每个异步IO实际上是多线程进行的?)Linux 下用了 epoll。
举个栗子:(发现各种教程里面举异步的例子都喜欢用 setTimeout …)
1 | console.log("start") |
这段代码除了 setTimeout 这个函数,其他的 API 包括这个 for 循环都是同步的,所以同步的部分先执行了。
6 个 setTimeout 任务进入等待状态。
在执行同步任务的过程中,setTimeout 的计数器到时间了(因为本身就设的是 0),消息队列里面会插进去 6 条事件,分别是触发对应的那条 setTimeout。
然后同步部分执行完毕,start 和 end 都输出了。开始从消息队列中取消息,每取一条 setTimeout,就执行它的回调函数 console.log(i)。
!!然后要注意这里的 i 是个全局变量,i 在 for 循环执行完毕的时候变成了 6,所以后面每一次输出的 i 都是 6。
实际执行的结果是:
1 | start |
这里如果把 for 循环中的 var 换成 let,最后得到会是这样的结果:
1 | start |
再改一下:
1 | function test() { |
输出结果是:
1 | start |
从上面可以看出来的是:
- 普通的函数是同步的!…… 之前一直以为这里面的函数全是异步的,看来只要不涉及到异步的 API 就都是同步的
- 因为消息队列是个队列,所以
i=0那条触发的 setTimeout 中增加的 setTimeout 事件只会被插到队列的再后面去。
爬虫
爬虫的基本思路就是,把页面的 html 拿下来,然后用解析的工具从里面匹配出需要的信息来。
最简单的两个包是 superagent 和 cheerio,superagent 用于获取网页的 html 源码,cheerio 用于解析 html 信息。
这段代码是简单地抓了一下博客首页:
1 | let cheerio = require('cheerio'); |
然后是 request 包,比 superagent 更常用一些,用于请求网页等等各种资源。
简单的爬虫学会了,然后我就想试试能不能把网易云上歌曲的评论数抓下来,,这里遇到个坑点。
网易云音乐的页面用了 iframe 框架来动态加载内容,打开页面之后直接获取 html 的源码会发现抓下来的只有框架,没有内容。
这就抓瞎了。。。
然后就上了 selenium-webdriver 这个包。
selenium 原本是用于页面的自动化测试的,具体使用起来就是 Node.js 代码会控制一个浏览器完成点击、输入等等操作(按键精灵有木有?)。
简单的抓页面的代码是这样,这里关键在于这个 driver.switchTo().frame('contentFrame'),用于切换到 iframe 加载出来之后的页面。
切过去之后才能正常抓到页面内容。
1 | let webdriver = require('selenium-webdriver'), |