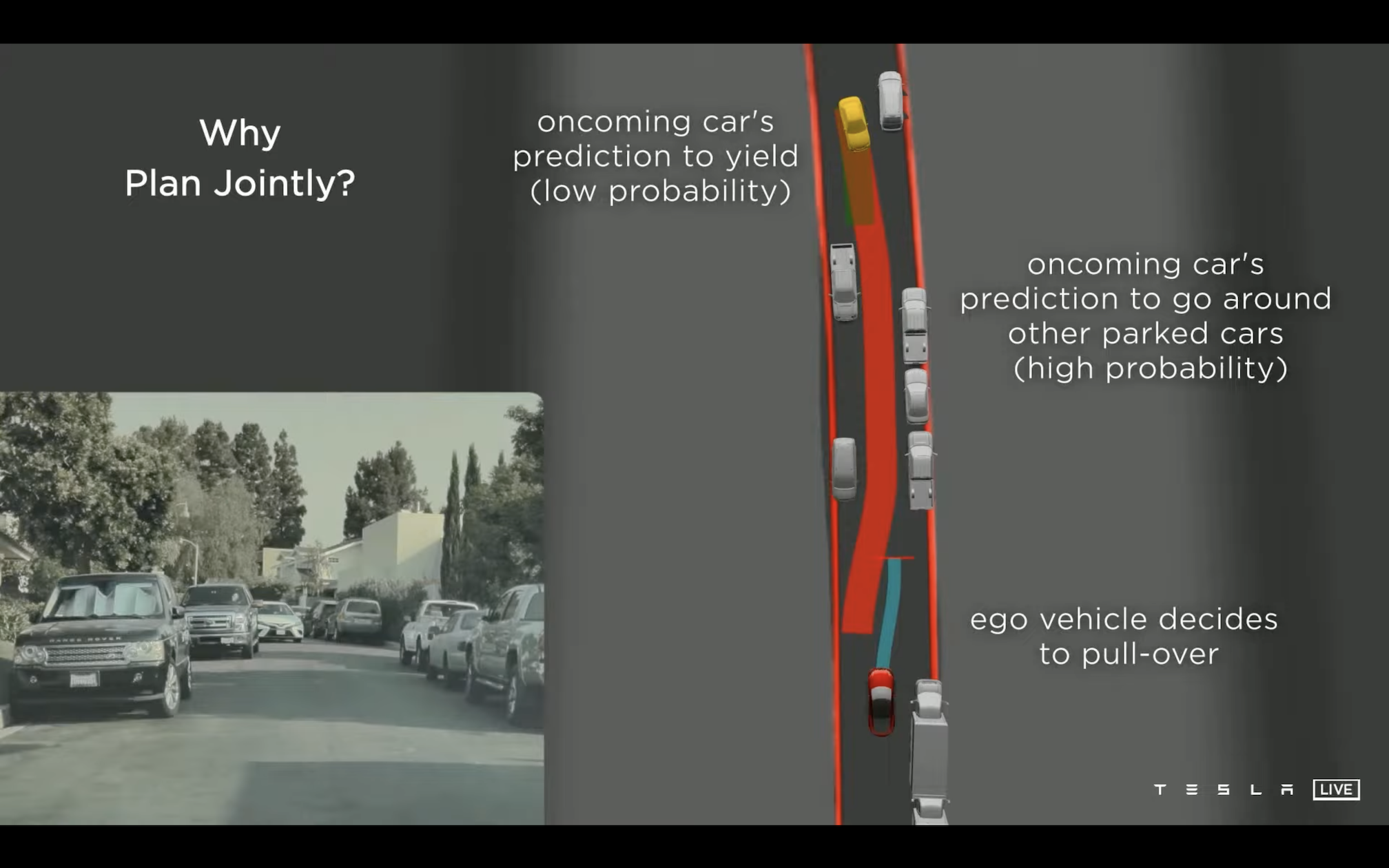
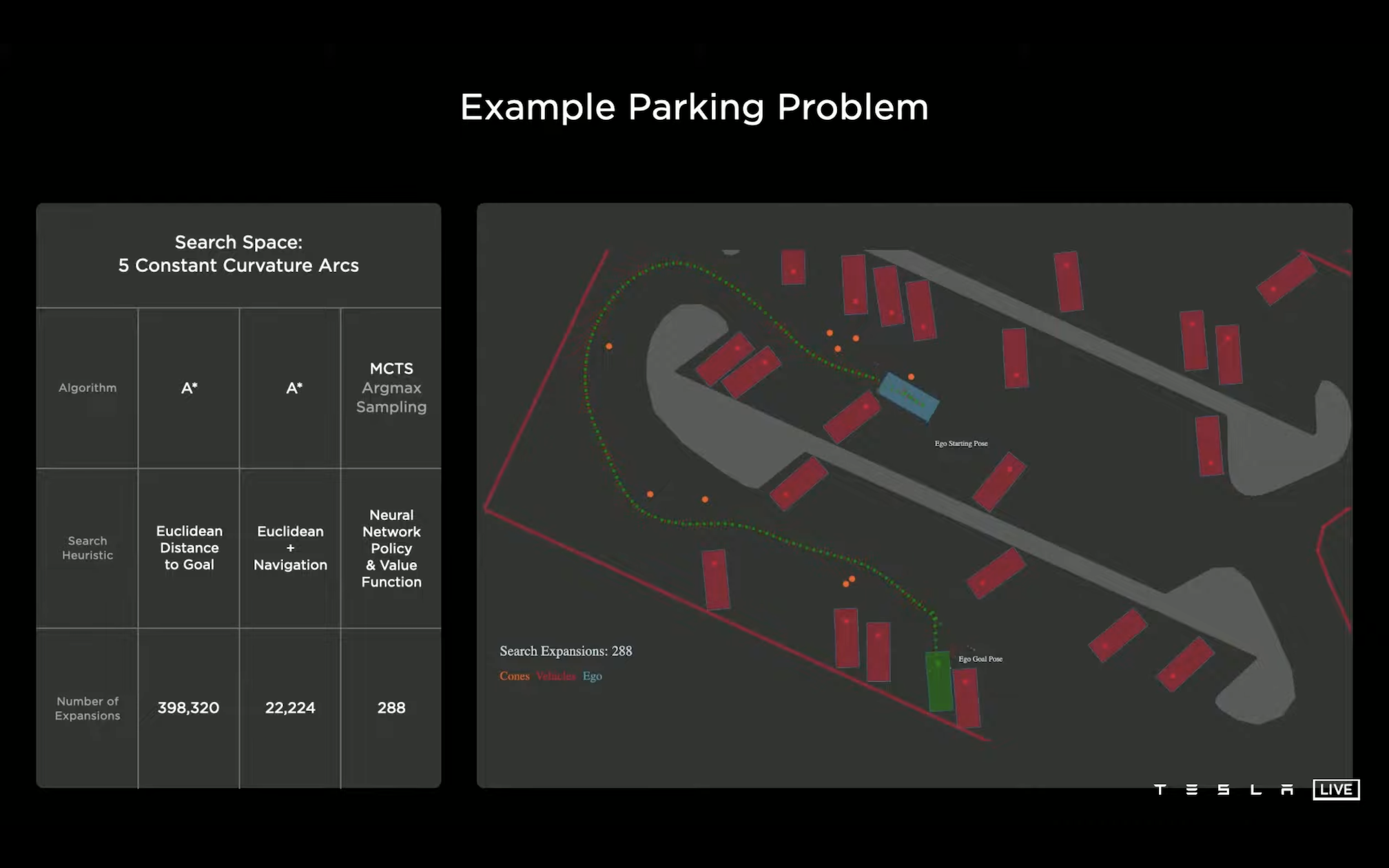
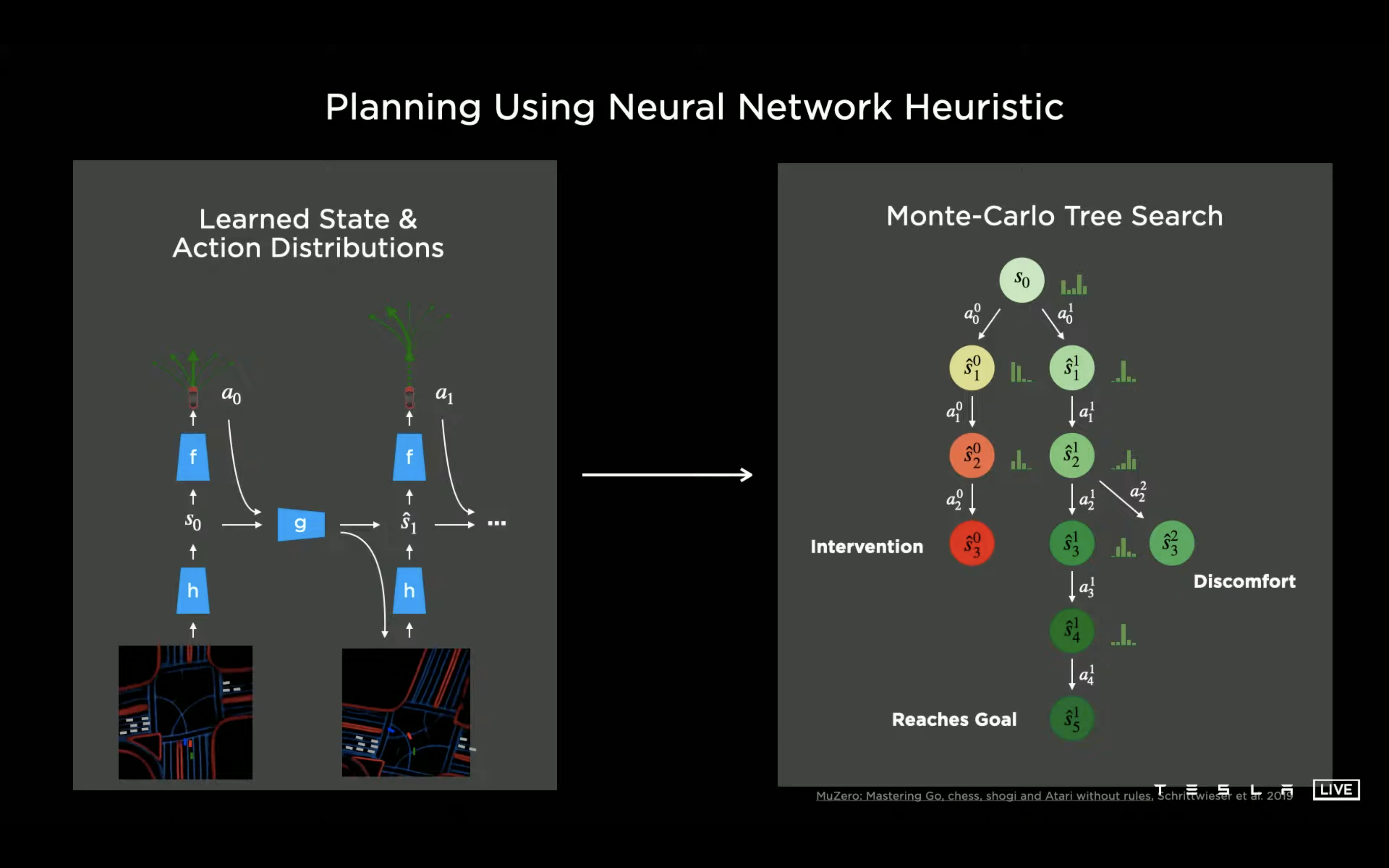
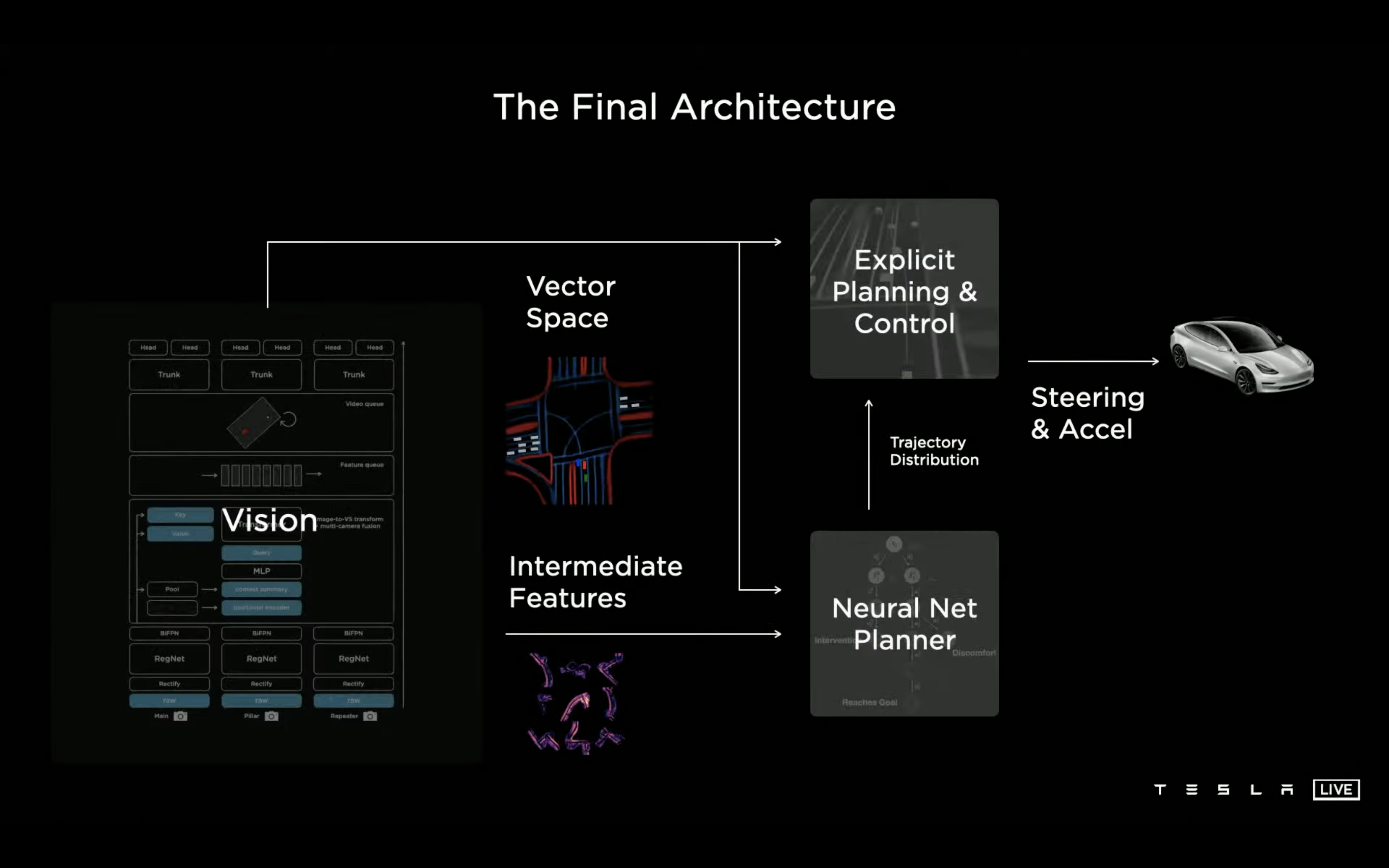
Talk 的视频链接在:这里
在过去的快两年时间里,我们依靠 TVM 打造了 NIO 全栈自研的 AI 引擎,支持各种感知、规控等等自动驾驶算法在 NT2.0 平台上的高效运行。我们几乎是看着 ET7 交付启动时只有 AEB,到后来逐步版本迭代可以支持 NOP+,再到今年 NAD 也即将要在我们的引擎支撑下开放测试了。
由于 talk 的时间限制,PPT 上对很多部分都是简单带过了,这里想稍微细节展开讲一下,也算是对来 NIO 以后工作的一个总结。
不知道算不算目前业界部署 TVM 范围最广的团队了(笑)。NT2 这代的车已经不止跑在全国各地的路上了,去年也已经出口到欧洲。
去年最早我们的部署目标只有 ET7,到后来 ES7、ET5 大规模交付,今年剩下的 ES8、EC7、ES6、EC6 也全面交付之后,路上能看到的 TVM inside vehicle 就到处都是了 ~(撒花)

Challenge and Solution

这里想说以下我们为什么选择了 TVM。
虽然说实话得承认有一个很大的原因是我们团队初期的几个成员在加入之前都是主要做 TVM 的。认真地回答则是我们其实也考虑过各种可选择的方案,那时候应该就是 TVM 和 MLIR 两个开源项目相对比较有活力了。我们认为 TVM 的当时的现状更加成熟一些:前端上,tf、torch、onnx 等等各种框架的支持都有了;后端有 AutoTVM 以及 Ansor 这样可用的工具,并且我们在 Ansor 中已经证明了通过搜索 codegen 是能够达到 SOTA 的性能的;另外像 TVM 中 BYOC 这样的 feature 也让我们在实际部署中有了更大的灵活性。
当然,MLIR 的架构更加灵活,想要把这些工作在 MLIR 中做到相同的水平当然也是可以期待的。只是凭借我们组的这么点人力,想要在短时间内做到可用基本上就比较难了。要知道从我们入职开始搭建 AI 引擎到 ET7 直接开启首批用户交付差不多只有半年时间。
值得一提的是,TVM 有 tianqi 来控制发展大方向,相比各家百花齐放的 MLIR 而言,感觉各个项目能更踏实地落到能真正用起来的实处上。我们也很期待能把后续工作切到 TensorIR、MetaSchedule 上,更多地把 TVM Unity 生态中的东西用起来。
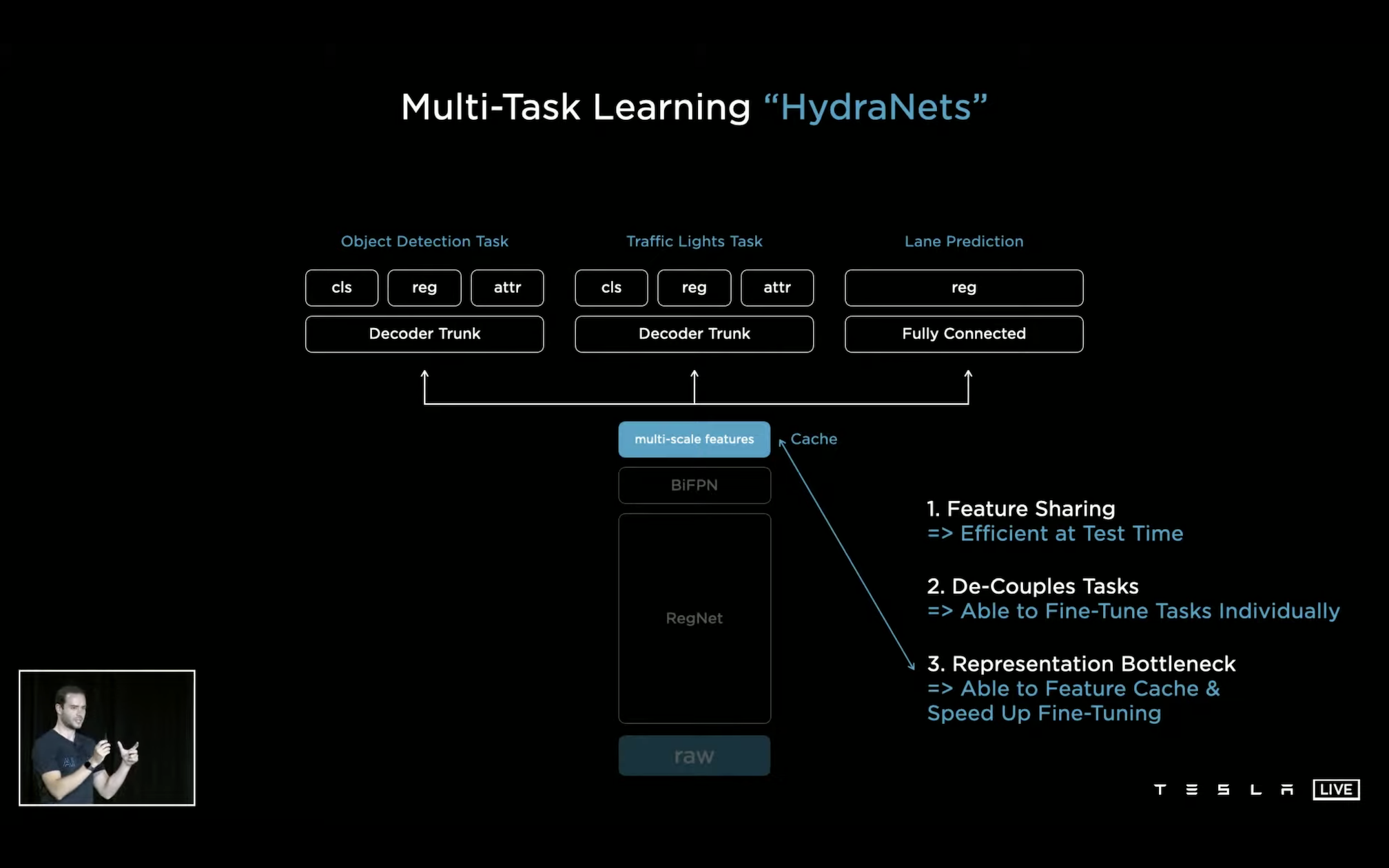
目前,我们实际部署过在车上跑的模型应该也有几十个了,模型包含 CV 类的、transformer 等等各种类型的模型,甚至还见过在上家公司做推荐业务时见过的 DeepFM 类模型,可以说自动驾驶真实是各种 AI 算法大综合的一个场景了。我们早期模型中存在比较多的控制流逻辑和动态 shape 情况,后来几个重点模型即使是上车前已经做了很大压缩和简化了,也还是会包含一部分动态 shape(例如 Lidar 点云数据天生就是稀疏 + 动态的)以及不少需要处理业务逻辑的 custom op 算子,模型本身还是相当复杂的。
也是受益于 TVM 中 BYOC 以及 VM 的灵活性,我们可以在模型中集 TRT + Cutlass + Custom Op + Ansor 等各种优化引擎的能力于一体,将每个部分的性能和精度优化到极致。
早期我们还会需要靠 TRT 来处理模型中比较规整的静态 DNN 部分;而随着我们自身的优化能力逐步起来之后,目前上车的业务模型已经全面去掉了 TRT,性能与量化后精度全面超越 TRT 的版本,在某几个重点的感知模型中至多能达到 TRT 的 1.5 倍性能。
一些内部的数据没法公开,PPT 里面就简单贴了下公开 benchmark 的结果。

去掉 TRT 之后,我们可以对模型本身做更多灵活有意思的事情,也才终于真正可以有底气地说是全链路全栈自研,全链路自主可控了,车上跑的 AI 模块里面的每一个地方我们都能拿得出来 source code。
Quantization
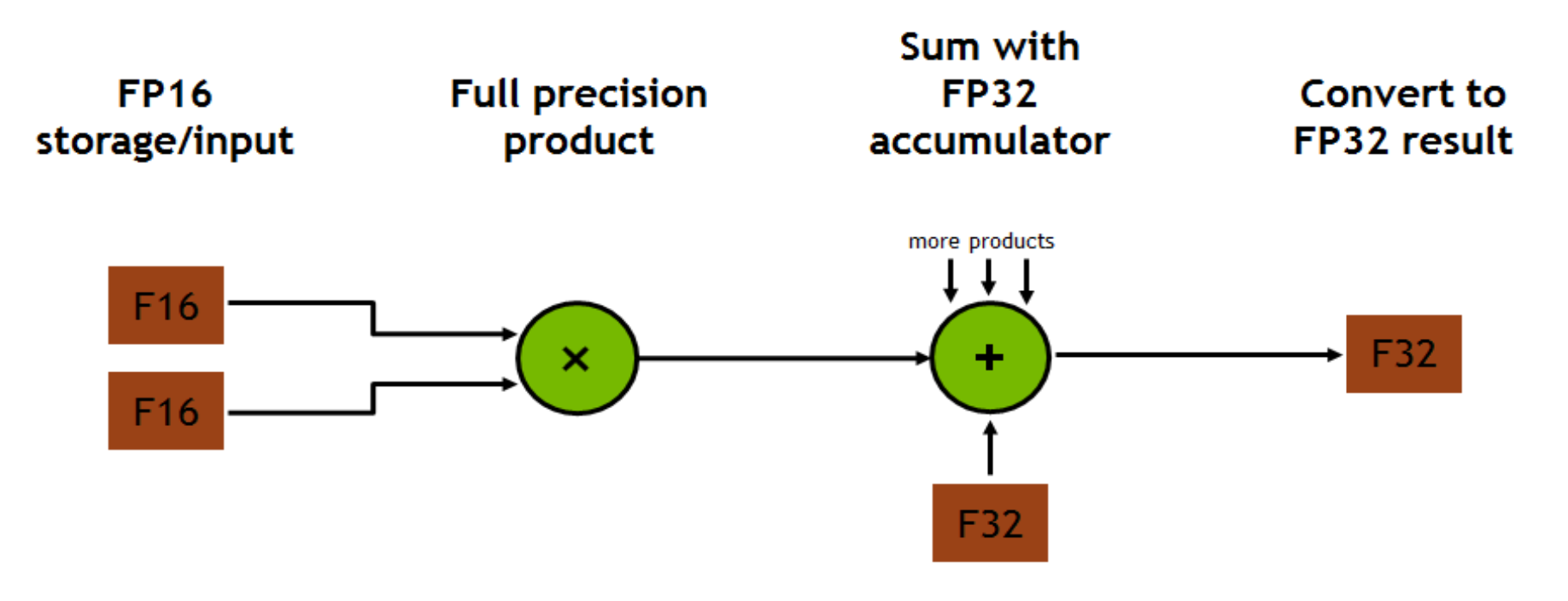
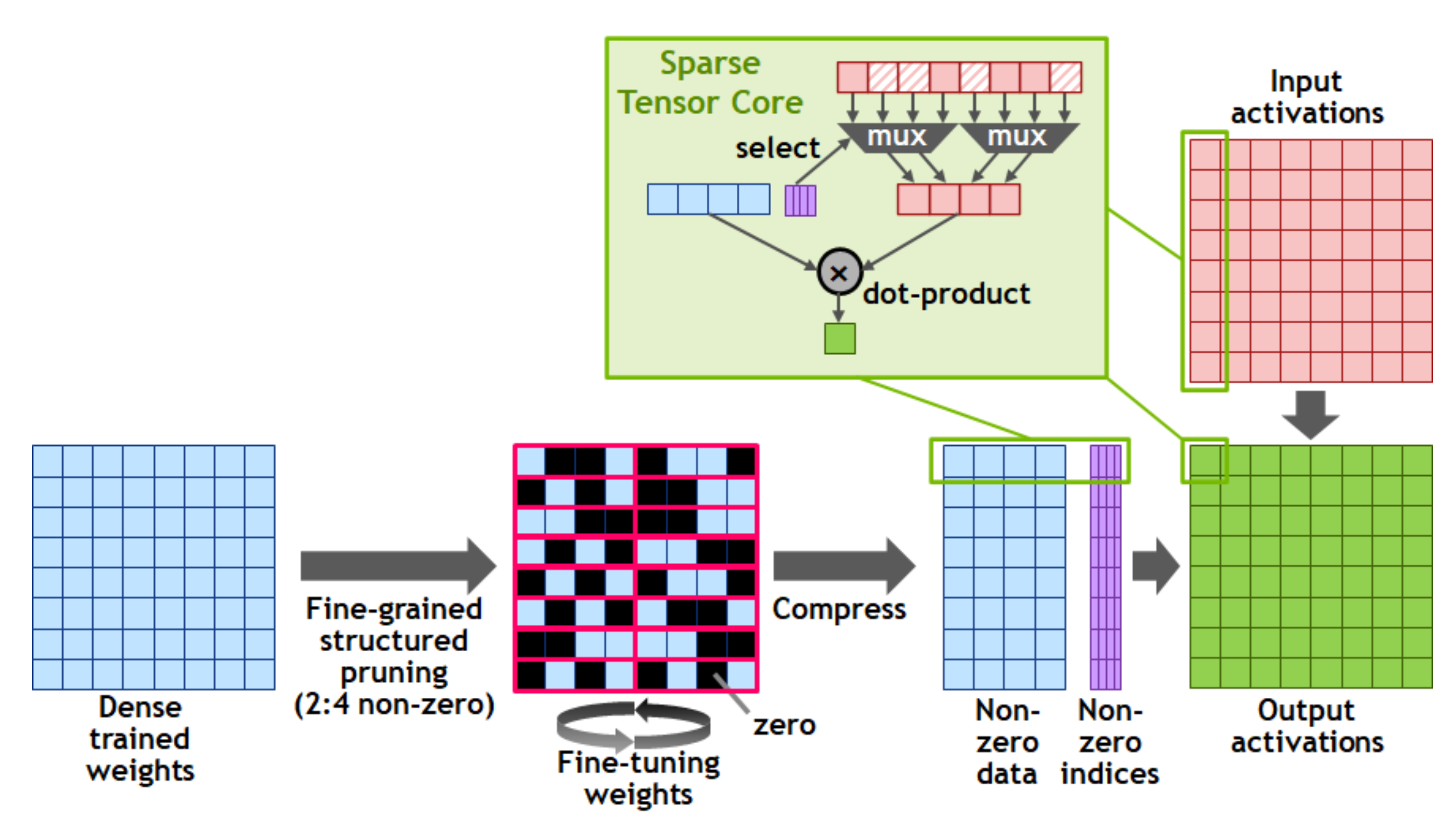
量化算法以 PTQ int8 + uint8 为主,对于一些精度敏感性较好的层会再继续尝试 int4 + uint4。如果遇到 scale 没办法通过进一步的误差分析和其他修正算法拉回来的情况就只能 fallback 回浮点了。量化模块处理完之后再将图过一遍 MixedPrecision pass,尽可能多的将剩下的浮点部分转成 fp16 处理。
这里有个也许是我们业务场景带来的特殊量化需求:部分量化。
车上环境对车规验证要求比较严格,每一次自动驾驶算法的模型更新都需要大量的仿真和实车路测验证才能通过验收。在目前比较普遍的一个 Backbone + 多个不同功能的检测 head 的模型结构中,有时候一些小版本更新只会更新部分检测 head 中的结构和参数。
我们通过控制量化算法的更新范围,可以做到一个模型中未改动部分的输出数值与之前的版本完全一致(误差在浮点 1e-10 以下严格一致),则小版本更新时所需的测试只需要重点关注改动部分即可。从引擎这一侧出发,我们给出了严格控制量化算法下 x86 云端 GPU 与车端 Orin 芯片结果一致性的保证,也是帮助业务和测试团队节省了很大的测试负担。
Graph and Kernel Optimization
图优化部分没什么太多可说的了,继续找到一些可优化的 pattern 优化掉,都是各家遇到了之后会做的工作。
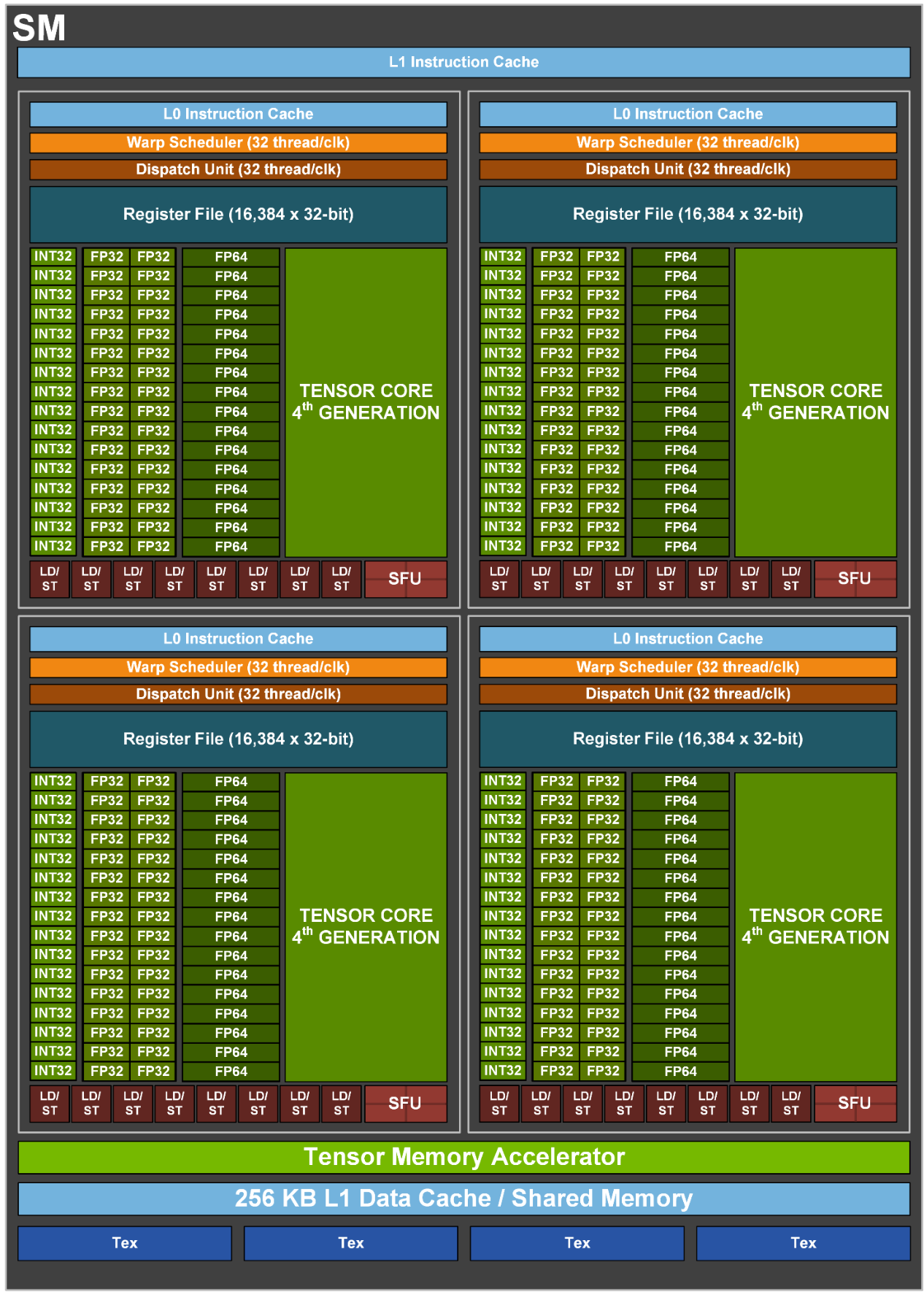
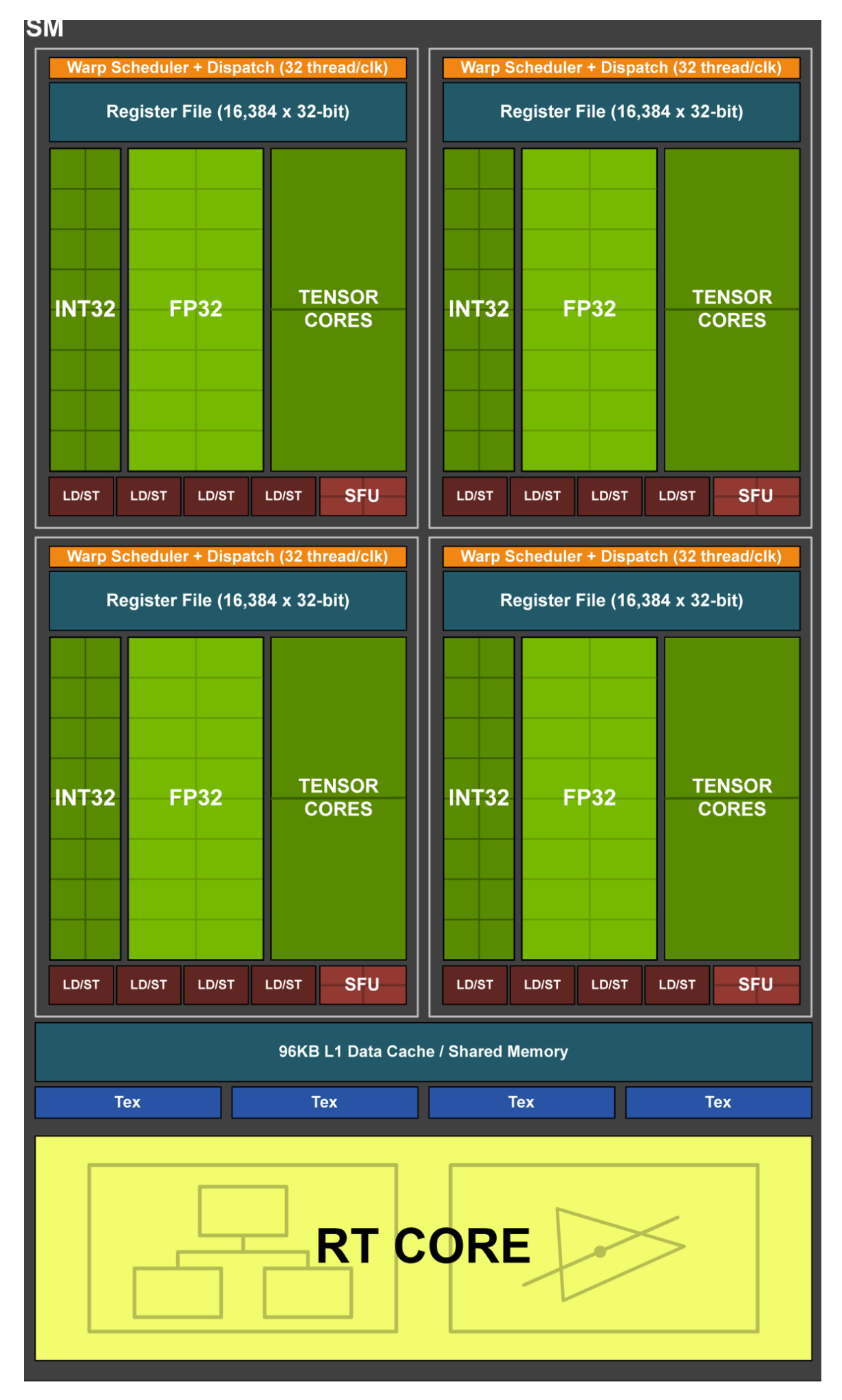
由于后续我们没有继续在 Ansor 中做 TensorCore 支持的开发了,目前我们重度依赖 Cutlass 来处理 Conv/Matmul 这样的计算密集算子。
论坛上也有好几个帖子问过相关的问题,其实之前我有个实验性的 custom sketch 是可以支持 TensorCore 跑起来的:
https://github.com/jcf94/tvm/tree/tensorcore_sketch_support/python/tvm/auto_scheduler/test_sketch
另外基于我们以前 AutoTensorCore 工作配合 Ansor 也能有不错的效果,只是后续没有精力继续完善了
后续更加合适的方向当然还是依靠 TensorIR 和 MetaSchedule 再来把 TensorCore 的性能推到一个新的高度了
拿到量化 + MixedPrecision 之后的计算图后,图上尽可能多的部分会通过 BYOC 圈给 Cutlass。相比社区版本的 Cutlass,我们扩展了更多 epilogue pattern 的支持,将 Conv/Matmul 前后的 q/dq、bias/residue add 以及连接着的 activation 等等边角的算子都尽可能圈进去。
剩下一些零碎的访存算子以及其他不太适合使用 TensorCore 来计算的算子则由 Ansor 来 cover 了。举例来说,大多数 CNN 模型的输入图像 channel 会是 3,也就导致第一层 conv 通常会有一个对 TensorCore 来说非常不友好的计算 shape,我们在 Ansor 中扩展了 CUDA dp2a/dp4a 指令的支持,这样第一层 conv 可以做到相比强行使用 TensorCore 更好的性能。其他像优化 Warp Shuffle 实现 cross thread reduction 等等也是社区版本上原本就有基础的实现,我们的版本就是在基础上继续扩充了更多各种场景下的 Ansor Sketch,让 Ansor 的搜索空间能够包含更强的性能,搜索得更有效率。
当然,我们也一直在跟进和在 MetaSchedule 上进行着性能探索工作,期待未来的有一天我们能将对 Cutlass 的使用逐步迁移到 MetaSchedule 上。
MSC
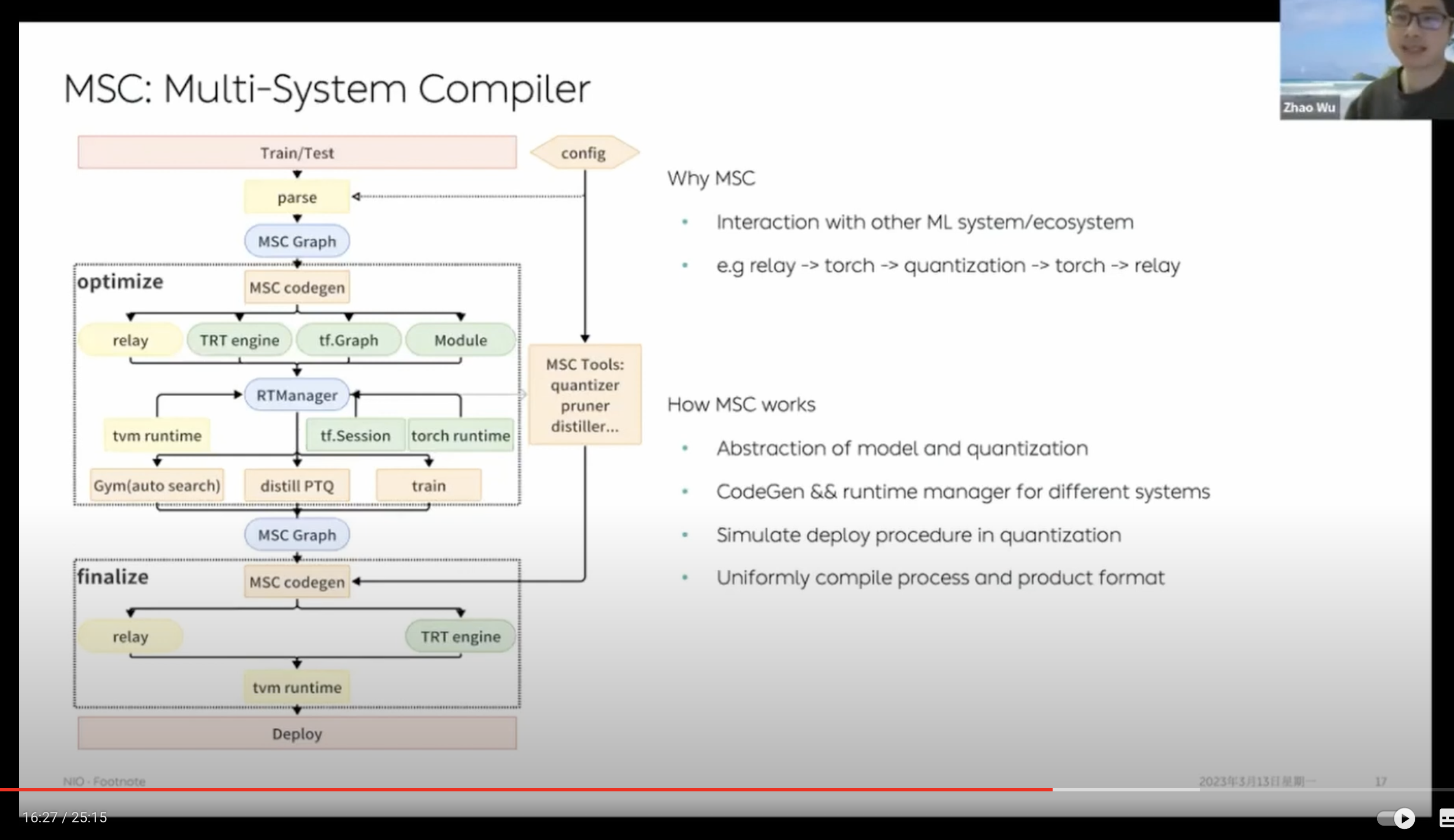
这个其实也是个比较有意思工作,大思路上与 TVM Unity 的想法是完全一致的。我们的初衷是为了能在 TVM 中方便地引入其他系统能力。比如 TensorFlow、Torch 中就有像 NNI 这样成熟的量化工具。
我们通过 MSC 可以很方便地完成 Relay graph 到 Torch、TensorFlow 等等各种第三方框架代码的转换,通过其他工具完成处理,最后重新转回 TVM 中完成最后的后端 codegen 部分。我们目前的整套量化算法就完全是在 torch 中实现的,借由这样一套灵活的架构,其他包括 Gym、Nas、稀疏化、QAT 等等工作也可以更方便地得到实现。
Better VM & Runtime
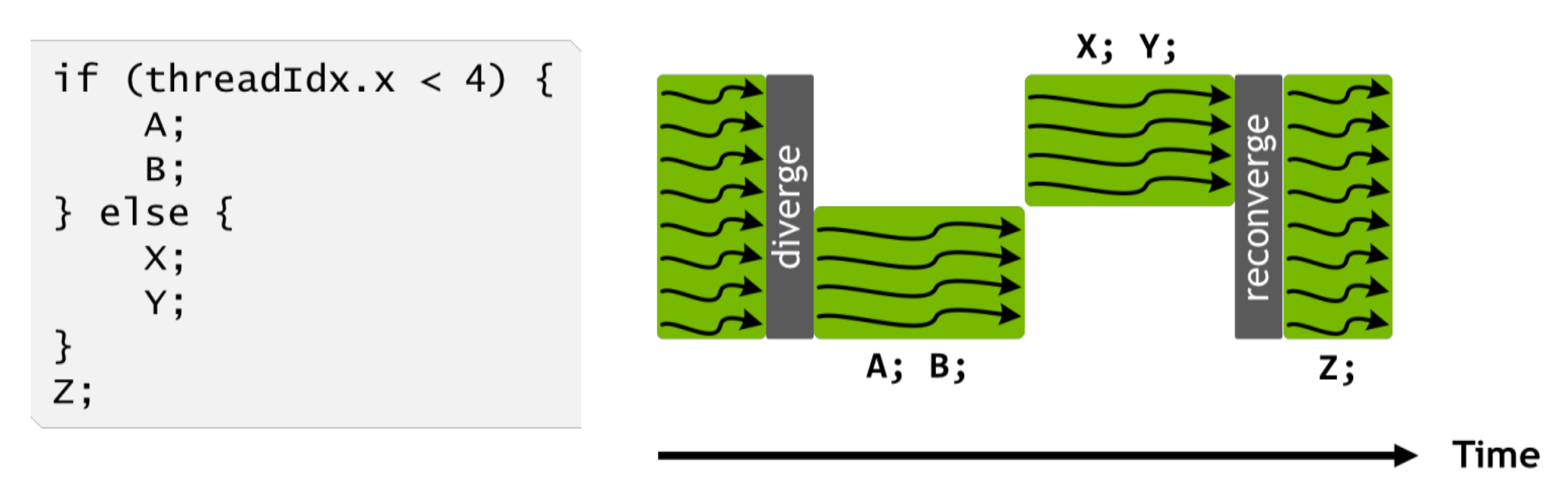
最后这部分算是我近半年来觉得做的最有趣的一块工作了。TVM 中主要依靠 VM runtime 实现动态 shape 的支持。由于业务模型中的部分动态性没有办法避免,VM 也是我们唯一的选择。
如果实际跑过的同学应该也会有体会,虽然 VM 已经是个相当轻量级的 runtime 了,但是相比静态的 GraphRuntime 而言,kernel 之外的 overhead 还是会更大一些。尤其是像在 Orin 这种 ARM 核性能并不是太强的硬件架构上,CPU 部分的负担有时候会超过 GPU,当 workload 太多的时候整个系统可能会 bound 在 CPU 上,最严重的极端情况下 GPU kernel 甚至会被卡住发不出去。
VM 的指令设计非常精巧,但在实际的业务优化过程中,我们逐渐发现它还是有点复杂了。(话说我看新版的 Relax VM 里面已经把 ByteCode 指令的种类减少了很多了,不知道是不是也有这方面的思考)
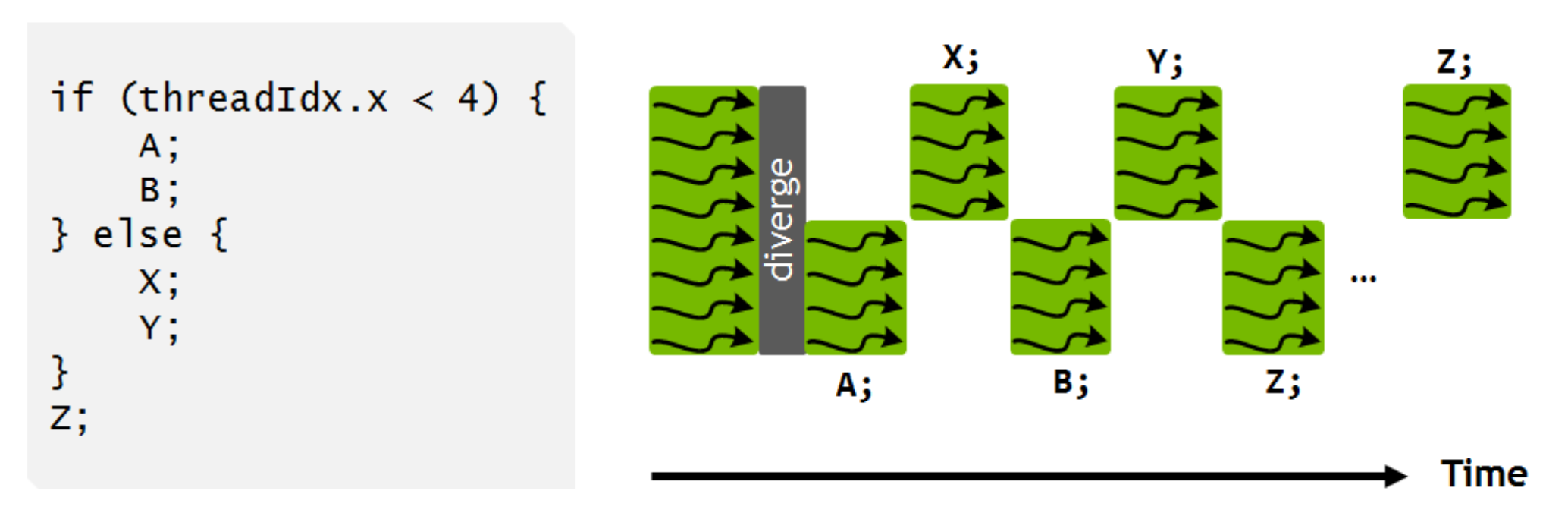
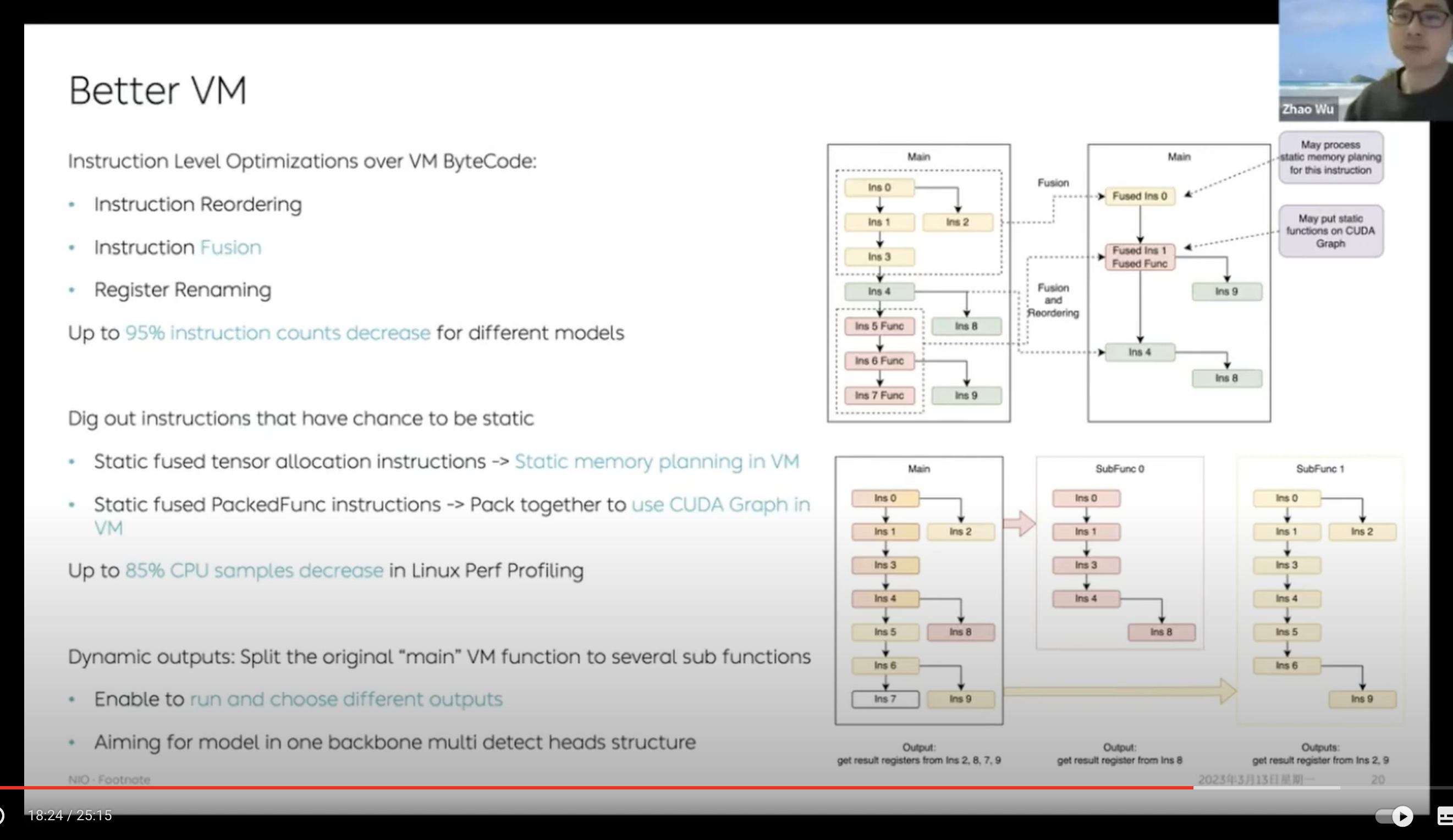
我们的想法是,能不能从现代超标量处理器对于 CPU 指令的优化经验中借鉴一些来,对 VM 目前的执行方式做一些好玩的工作呢。于是就有了我们现在的魔改版 VM。针对 VM 指令,我们加了一些基础调整策略:
- 无数据依赖关系的指令可以无损地进行指令执行顺序的交换(Instruction Reordering)
- 相邻的相同指令可以合成一条更大的指令(Instruction Fusion -> VLIW)
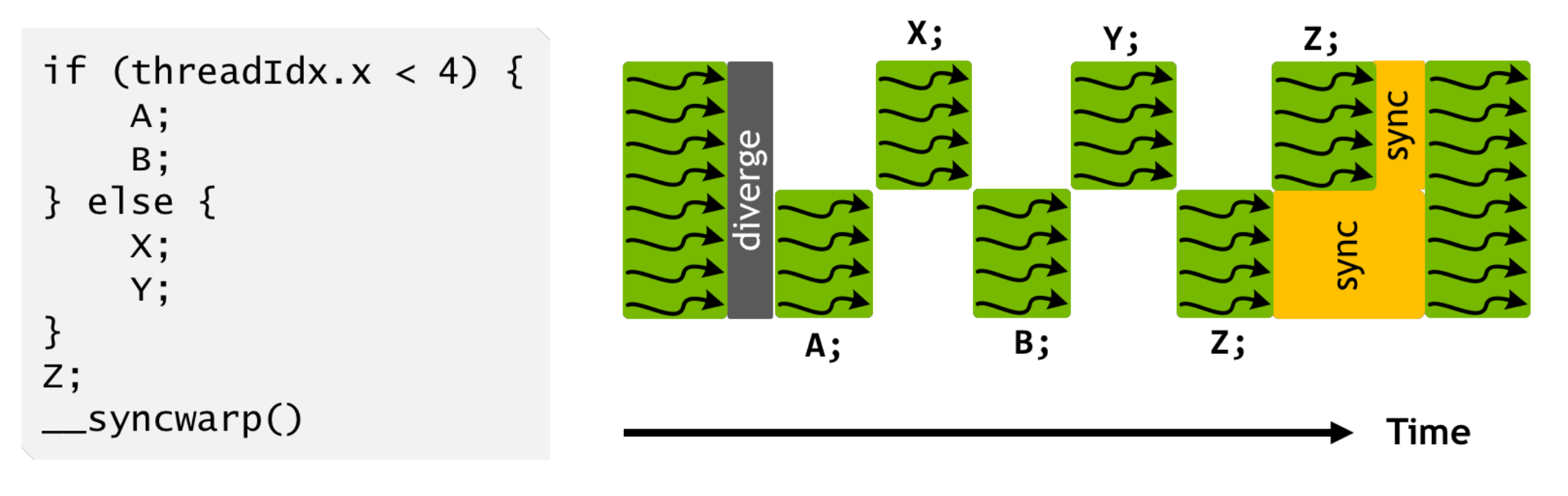
做完重排和合并之后,我们还想过可以做一个动态多发射(多线程 issue 最后顺序 commit)的超标量虚拟机(可惜简单试了下发现没有太大的收益…后面倒是有机会也希望能更多地探索一下)。不过,至少把 memory allocation 相关的指令合在一起之后就可以基于这个做类似 GraphRuntime 那样的静态初始化 memory planing 了。
当所有执行 kernel 的 memory 有机会变成静态之后,更大的收获是 CUDA Graph 也可以上了!所以可以看到我们最终做完指令级优化的模型相比刚转出来的时候能减少 95% 的 ByteCode 指令数量,实际部署环境下对 CPU 的负载也能大大减少了。
这里另外可以提的一个工作是基于 VM 可以往一个模型里打包多个 ByteCode Function 的能力,我们增加了可以每一次 inference 都能够动态选择执行模型某一部分的能力。这样车端的某些检测 head 在不需要这么高的帧率时可以动态关闭以节省算力和功耗。
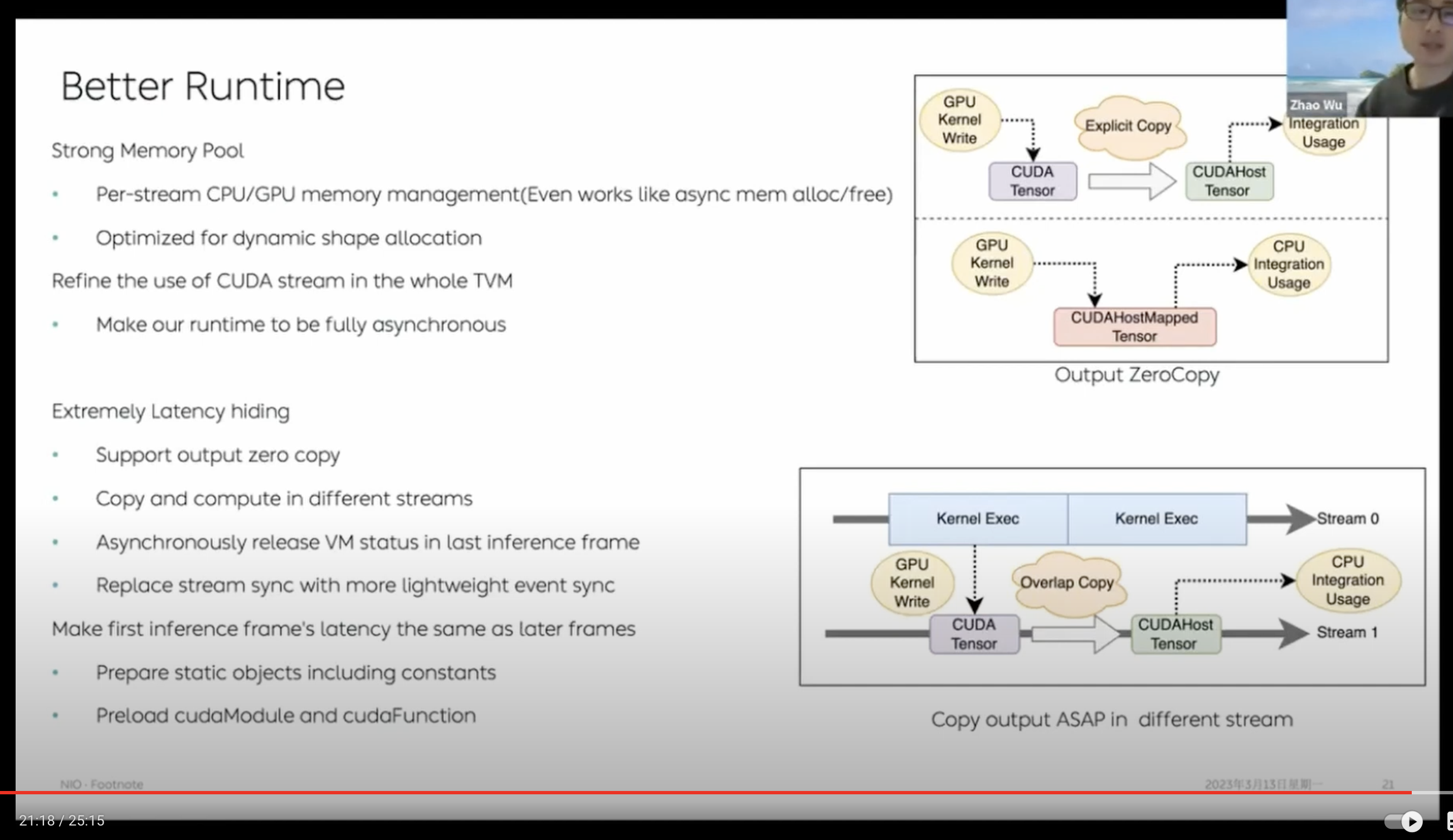
Runtime 部分其他的内容诸如重写了全新的内存池等等都是我们在业务摸索遇到了实打实的坑之后慢慢加上的。
我们几乎是把整个 TVM 里面对 CUDA Stream 的使用都重新理了一遍,基于内存池把 memory allocate、free 等等各种管理操作也都绑定到了 stream 上,实现了一个几乎是全异步的 runtime。
后记
非常幸运能在几年前从 TVM 开始 AI Compiler 的探索之旅,也非常开心能看到 TVM 每年都还这么有活力,朝着更强大的方向继续发展着。
至少我们现在已经证明了 TVM 这套编译栈架构是足以撑得起几十万辆车上车规级业务的稳定部署的。后续我们也还将基于 TVM 继续在自研芯片上支持 NT3.0 的下一代车型和自动驾驶功能。
]]>